Blog
Top 7 Data Modeling Tools for Effective Data Management
The best tools to bring structure and meaning to data, and enable insightful analysis.



Data modeling is not just a fancy diagram. If yours are like mine, they are distinctly unfancy.
However good your design skills, data models are a great way to build the conceptual skeleton of any database system. Building a data model is an investigation into data requirements, data relationships, and data structures, all wrapped with your business requirements.
And they are never static. They're vibrant entities, responding dynamically to changes as they're poked, prodded, and shaped by business stakeholders or end users. The resulting model ensures accurate, consistent, and relevant data for decision making. The ability to use your data model to detect potential data integration problems, establish harmony across multiple systems, and provide transparency of data dependencies and workflows, are further feathers in its cap.
Moreover, data modeling offers a validating framework, elevating data quality. It busts data silos and ensures seamless integration, thus always keeping data ready at your fingertips. It's the guardian of data consistency, ensuring its accuracy and currency.
In the current era, data modeling has evolved to include an array of versatile open-source and premium tools. Let's dive in and explore these tools, alongside top data modeling practices, in this comprehensive guide.
Getting started with data modeling
Before we get into the tools, let’s take a quick tour of what you’ll do with those tools. Data modeling techniques define the logical structure of the data model–how the data will be stored, organized, and retrieved logically. There are several techniques for data modeling but here we’re going to introduce four:
- Entity-relationship (ER) modeling is a method to visualize data in terms of entities, their attributes, and the relationships that connect them.
- Relational modeling structures data into predefined tables, establishing connections based on shared attributes.
- Hierarchical modeling builds a tree-like structure, depicting data as interconnected parent and child nodes.
- Object-oriented modeling encapsulates data and associated methods into objects, bringing the real-world objects' behavior into the data realm.
Entity-Relationship Modeling
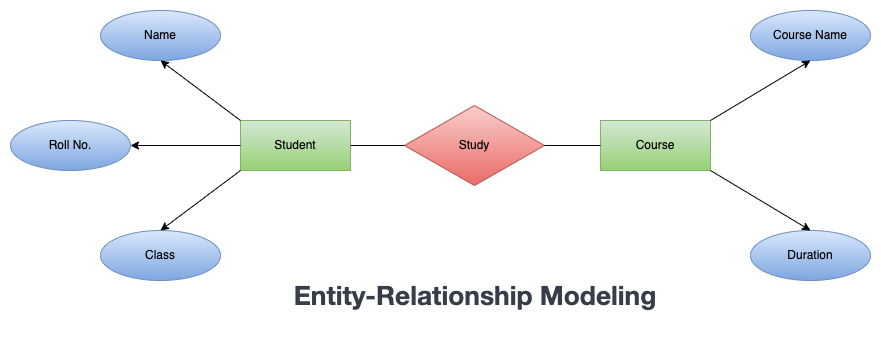
Entity-relationship (ER) data modeling is a technique for representing data in a database in terms of entities (objects), attributes (properties of the entities), and relationships (connections between the entities).
It’s a popular method for designing databases because it helps to ensure that the database is well-structured and accurately reflects the data that it will store. It uses different shapes to represent the whole model:
- each entity is represented as a rectangle with its name written inside
- each attribute is represented as an oval attached to the corresponding entity.
- Relationships between entities are represented as lines connecting the entities, with optional arrowheads indicating the direction of the relationship.
Relational Modeling
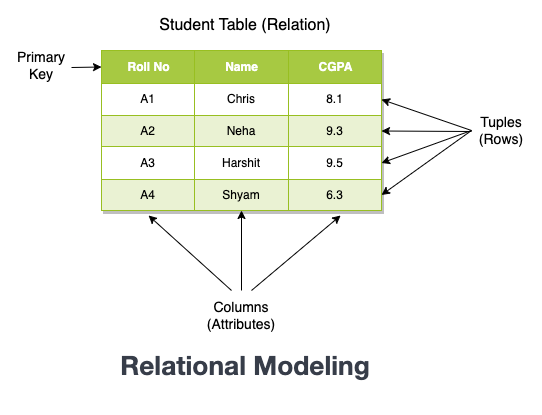
The most popular data modeling technique that is used in databases for analytics work is relational data modeling. Relational modeling organizes data into different tables that are related to each other. Each table contains a set of columns that represent the attributes (properties) of the entity.
One of the key benefits of relational data modeling is its ability to enforce data integrity and consistency through the use of constraints, such as primary keys, foreign keys, and unique constraints. The data stored in these tables can be managed efficiently using structured query language (SQL).
Hierarchical Modeling
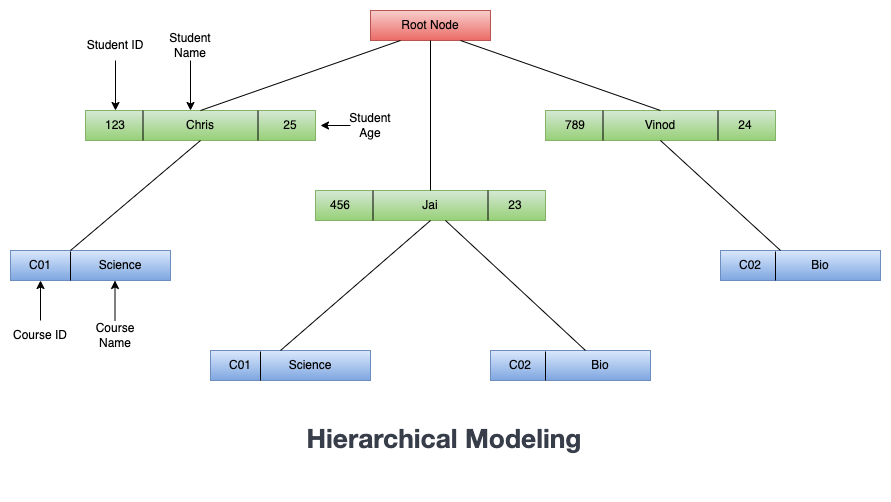
Hierarchical data modeling is a technique for organizing data in a tree-like structure, where each node in the tree represents an entity, and each child node represents a sub-entity or an attribute of the parent node.
This type of modeling is often used in hierarchical databases that organize data in a hierarchical structure. In this data modeling, data is organized into levels, with each level representing a different aspect or category of the data. The top-level node represents the root of the hierarchy, and subsequent levels represent sub-categories or attributes of the root node.
For example, in a hierarchical database of student data, the top-level node might represent the student information, with subsequent level representing the courses chosen by each student.
Object-Oriented Data Modeling
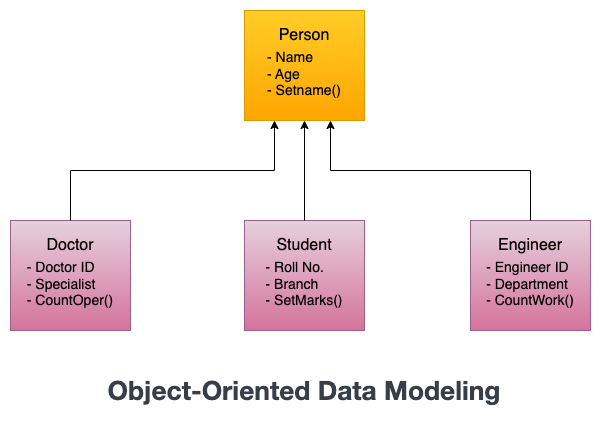
Object-oriented data modeling is a technique for representing data in a database using the concepts of object-oriented programming (OOP).
In object-oriented data modeling, data is organized into objects, which are instances of classes, with each object having its own set of properties (attributes) and methods (functions). It enables you to use the OOP concepts like encapsulation, abstraction, and inheritance.
While it is not as widely used as relational data modeling, it is well-suited for applications that require complex data structures or that are built using object-oriented programming languages.
Subsets of data modeling: vaults and warehouses
Most data modeling is done with a primary database in mind. But data infrastructure has grown far beyond just simple database structures, and data modeling has to grow as well. Two subsets of data modeling that you might need to consider are:
Data vault modeling
Data Vault modeling is a methodology designed for long-term historical storage of data coming from multiple operational systems. It is detail-oriented, fully auditable, and highly scalable, making it an excellent choice for complex and evolving data environments.
Data Vault modeling is composed of three primary entity types: Hubs, Links, and Satellites:
- Hubs: These represent the unique list of business keys within the organization. A business key is a unique identifier in the source system, such as a customer ID or a product ID.
- Links: These represent associations or transactions between business keys. For example, a sale linking a customer to a product is a Link.
- Satellites: These are descriptive attributes or context related to a Hub or a Link. For example, the attributes of a customer, like their name and address, would be stored in a Satellite linked to the customer Hub.
Data Vaults are built for the enterprise, so Data Vault modeling has characteristics that skew that way:
- Auditability: Each piece of data in a Data Vault includes a record of its source and load timestamp, which means you can trace every piece of data back to its original source.
- Scalability: Data Vaults are highly scalable. You can add new Hubs, Links, or Satellites without impacting existing structures, which makes it an excellent choice for evolving businesses.
- Flexibility: The Data Vault's structure can easily adapt to changes in business requirements or source systems. This flexibility allows for easier integration of new data sources compared to traditional methodologies.
- Resilience: Data Vaults are resilient to changes in source systems. If the structure or content of a source system changes, only the related Satellites usually need to be adjusted.
- Long-term storage: Data Vault modeling is excellent for maintaining long-term historical data, making it perfect for trend analysis and historical reporting.
Data Vault modeling is complex to implement and requires a good understanding of the source data and business keys. You will need an enterprise team to deal that are used to dealing with complex data landscapes.
Data warehouse modeling
Data warehouse modeling involves designing the architecture and structure of the data warehouse system to make sure it serves the reporting and analytical needs of an organization effectively.
Data warehouse modeling differs from traditional database modeling in some ways as warehouses mainly focus on supporting the decision support system (DSS) process while databases focus on retrieving, inserting, deleting, and changing data. But the good part is, almost every tool that is available for data modeling supports both traditional database modeling and data warehouse modeling.
Here's a breakdown of the different components and concepts you'll commonly encounter in data warehouse modeling:
- Fact and Dimension Tables: The most common approach to data warehouse modeling is the star schema, where data is organized into fact and dimension tables. Fact tables typically contain numerical data (such as sales figures) and foreign keys to dimension tables, which provide context to the facts (like time, location, and product details).
- Schema Types: Apart from the star schema, there are other schema types used in data warehouse modeling, including the snowflake schema (a more normalized version of the star schema) and the galaxy schema (also known as a fact constellation schema, which includes multiple fact tables sharing dimension tables).
- Normalization and Denormalization: Normalization is a process of structuring data to minimize redundancy and improve integrity. In contrast, denormalization is a strategy used to improve the read performance of a database by adding redundant data or grouping data. In data warehouse modeling, you often denormalize data to speed up complex analytical queries.
- OLAP Cubes: Online Analytical Processing (OLAP) cubes are a key component of data warehouse modeling. An OLAP cube is a multidimensional array of data that allows for complex analytical and ad-hoc queries with a rapid execution time. It's structured to display summarized, grouped data for easy analysis.
- Data Marts: A data mart is a subset of a data warehouse that pertains to specific business functions, such as sales or finance. Each data mart is dedicated to a specific topic or department, making it easier for individual business units to manage and analyze their data.
- ETL Process: Extract, Transform, Load (ETL) is a data integration process that's integral to data warehouse modeling. This process involves extracting data from various source systems, transforming it into a suitable format, and loading it into the data warehouse.
The key is to align the data warehouse's structure with the organization's specific needs, keeping in mind factors like performance, data quality, flexibility, and the types of analyses that will be performed.
The best database and data warehouse modeling tools
You can plan out any database or data warehouse modeling based on the techniques above manually. But using data modeling tools makes the process more efficient, more accurate, and more collaborative. It also means you have a standard you can work from whenever you need to update your model.
There’s a whole world of data modeling tools available. The best one for your scenario is going to depend on:
- Functionality: Examine the tool's capabilities, ensuring it supports the necessary modeling techniques, offers forward and reverse engineering, and provides version control.
- Integration: The tool should integrate seamlessly with your existing systems, software, and databases to maintain workflow continuity.
- Data Visualization: The tool should offer robust visualization capabilities to simplify understanding of complex data structures and their interrelations.
- Scalability: Consider the tool's ability to handle increased data volumes and complexity as your business grows.
- Cost: Analyze the tool's cost against your budget. Besides the initial expense, consider the total cost of ownership, including updates and maintenance.
Here are some data modeling tools that can work for your organization:
ER/Studio
ER/Studio is a robust and comprehensive data modeling tool developed by IDERA that offers a wide range of features and capabilities to support efficient and effective data modeling processes.
The tool supports both forward engineering, allowing users to create a physical database from a logical model, and reverse engineering, enabling the generation of a logical model from an existing database or data warehouse. This versatility makes ER/Studio suitable for designing databases from scratch or analyzing and documenting existing databases or warehouses.
Additionally, ER/Studio provides a comprehensive data dictionary that serves as a central repository for storing and managing metadata related to the data models.
Some of the key features of ER/Studio are:
- It supports multiple levels of data modeling, including conceptual, logical, and physical models.
- It can generate DDL (Data Definition Language) scripts for different database platforms based on the data model.
- It enables the generation of detailed documentation and reports for data models. - It enables users to trace data lineage and perform impact analysis.
- It integrates with various database management systems (DBMS) and supports a wide range of database platforms.
ERwin Data Modeler
ERwin Data Modeler, developed by Quest Software, is a robust and widely-used data modeling tool that enables organizations to design, visualize, and manage their data assets.
With ERwin, users can create conceptual, logical, and physical data models using an intuitive and user-friendly interface. ERwin also supports forward engineering, allowing users to generate physical databases from logical models, as well as reverse engineering, enabling the creation of logical models from existing databases.
Similar to ER/Studio, ERwin also offers comprehensive data dictionary functionality, allowing users to store and manage metadata associated with their data models, ensuring consistent and standardized data definitions.
Some of the key features of ERwin are:
- It provides a user-friendly graphical interface that allows users to visually design and manipulate data models.
- It supports multiple levels of data modeling, including conceptual, logical, and physical models. - It has both forward and reverse engineering capabilities.
- It allows users to trace data lineage and perform impact analysis.
- It can generate DDL (Data Definition Language) scripts for various database platforms based on the data model.
- It provides features to support data governance and compliance initiatives.
IBM InfoSphere Data Architect
Developed by IBM, InfoSphere Data Architect (ISDA) is a robust data modeling and design tool that allows organizations to create, analyze, and manage data models across various database and data warehouse platforms.
You can discover, model, relate, standardize, and integrate various distributed data assets across the company with the help of ISDA. It is a collaborative data modeling and design solution that helps in advanced data modeling of databases and warehouses. As it provides column-organized tables, it provides a better understanding of data assets while enabling team collaboration and integration.
Some of the key features of ISDA are:
- Using JDBC connection, it helps to explore the data structures using native queries.
- Both logical level and physical level data modeling is offered by InfoSphere.
- It provides a user interface to easily investigate the data elements.
- It can automatically import and export constant mappings of data models to and from a CSV file.
- Using Information Engineering (IE) notation, elements from logical and physical data models can be visually represented in diagrams.
Oracle SQL Developer Data Modeler
The open-source data modeling tool SQL Developer Data Modeller, created by Oracle, increases productivity and makes data modeling tasks easier. It supports both forward and reverse engineering capabilities.
It allows you to create, view, and manage data models graphically, enabling you to design and visualize your database structures. Users can develop, explore, and change logical, relational, physical, multi-dimensional, and data type models using Oracle SQL Developer Data Modeller.
Some of the key features of Oracle SQL Data Modeler are:
- It allows you to generate database scripts (DDL) from your data models, facilitating the creation of physical database objects.
- The tool supports both relational and dimensional modeling techniques.
- It includes a validation engine that checks your data models for errors, naming conventions, and modeling standards.
- The tool supports comparing different versions of a data model, highlighting the differences between them.
- It supports various modeling standards and notations, including IDEF1X, Crow’s Foot, and UML.
Toad Data Modeler
Developed by Quest, Toad data modeler is a data modeling and database design tool that allows database administrators, data analysts, and other professionals to create, manage, and document database structures, relationships, and data flow.
With Toad, you can create and modify database schema and scripts, develop logical and physical data models, compare and synchronize models, write complex SQL/DDL quickly, and reverse- and forward-engineer databases and data warehouse systems.
Some of the key features of Toad Data Modeler are:
- It supports a wide range of database management systems (DBMS) such as Oracle, SQL Server, MySQL, PostgreSQL, IBM DB2, and more.
- You can generate a database schema from a model (forward engineering) or create a model from an existing database schema (reverse engineering).
- It you to create data flow diagrams that illustrate the flow of data within your database model.
- The tool supports team collaboration, allowing multiple users to work on the same model simultaneously.
SAP PowerDesigner
SAP PowerDesigner is a powerful data modeling and enterprise architecture tool developed by SAP that provides a comprehensive set of features and functionalities for designing, documenting, and managing complex systems like data warehouses and databases.
It goes beyond data modeling and also supports enterprise architecture, allowing organizations to define and visualize their architectural components, business processes, and relationships. The tool promotes collaboration and teamwork by facilitating simultaneous work on models, version control, and communication through commenting and annotation features.
PowerDesigner also excels in generating comprehensive documentation and reports, enabling users to export diagrams and publish documentation for stakeholders.
Some of the key features of SAP PowerDesigner are:
- It allows users to create conceptual, logical, and physical data models.
- It provides a simple user interface with a drag-and-drop feature.
- The tool provides capabilities for managing metadata, allowing users to define and capture metadata information associated with their models, databases, and warehouses.
- It can integrate with SAP systems like SAP HANA, SAP ERP, and SAP BW/4HANA, providing a unified approach to design and development.
dbt (data build tool)
dbt, developed by Fishtown Analytics (now dbt labs), is a powerful tool that helps data analysts and engineers transform data in their warehouses. With dbt, you can perform data transformations using SQL, making it accessible to those who already have a good grasp of this ubiquitous data language.
Primarily used in the transformation layer of ELT (Extract, Load, Transform) processes, dbt allows data professionals to create, maintain, and document data transformation pipelines. This results in clean, reliable datasets for analysts to work with, which are defined and tested as code stored in version control.
Key features of dbt include:
- It supports code-based modeling. Transformations are written in SQL and stored as version-controlled code, allowing for clear audit trails and reproducibility.
- dbt includes built-in schema tests, allowing you to maintain data quality by checking that data matches the specified criteria.
- dbt tracks dependencies between different transformation steps, ensuring they are run in the correct order.
- It automatically generates documentation for your transformations, making it easier for others to understand and use your data models.
- dbt supports a wide range of modern data warehouses, including BigQuery, Snowflake, Redshift, and Postgres.
Just as the tools we have previously discussed, dbt can be an effective instrument for data modeling, especially in modern data stacks where ELT processes are favored over traditional ETL. It's also worth noting that dbt has a strong and active community, which can be a great resource for getting help and sharing best practices.
Data Modeling Best Practices
It’s common for data engineers to just start mapping out their data structures. But without considering the best practices of data modeling, you can end up with models that don’t scale or aren’t flexible enough to deal with your data as it shifts. Here’s a few ways you can prepare better data models:
- Understanding Business Requirements. Without knowing the exact business requirements, you might not know which data to gather, prioritize and capture from a data store. By understanding the business requirements data modelers can accurately identify the relevant entities, relationships, and rules that need to be captured in the model.
- Data Visualization is the Key. Data visualization enhances the clarity and accessibility of the data model, making it easier for stakeholders to grasp and analyze the information it contains. Ultimately, you should choose a data modeling tool or service that results in easy visualization of data models.
- Start Simple, Expand Later. As the business evolves and new requirements emerge, the data model can be expanded gradually and iteratively. This approach ensures that the data model remains flexible and adaptable to changes, preventing it from becoming overly complex and difficult to manage.
- Normalizing Data. Normalization helps in improving the data integrity, and data consistency and enhances flexibility and adaptability. It also helps in optimizing data storage and retrieval. By following normalization principles, data modelers can create well-structured and reliable data models that accurately represent the underlying business domain and support effective data management and analysis.
- Ensuring Data Integrity. Ensuring data integrity involves implementing mechanisms to enforce data integrity constraints, such as primary key constraints, foreign key relationships, and business rules. By enforcing constraints and business rules, data modelers create a trustworthy foundation for data-driven decision-making and analysis.
Data modeling is the backbone of your data strategy
Be it open-source or premium, these tools form the backbone of our data management strategies. They're our partners in uncovering data requirements, mapping relationships, and designing structures that align seamlessly with our unique business needs.
Our data models are more than just diagrams; they're dynamic entities that constantly evolve with our business. They help us spot potential data problems, harmonize our systems, and maintain transparency in our data workflows. With effective data modeling, we break through data silos and ensure seamless integration, making data accessible when and where we need it. It's a cornerstone for making informed decisions, setting the stage for valuable insights and robust data-driven strategies.
But bear in mind that choosing the right tool is only part of the journey. Pair it with best data modeling practices, and the best tools throughout the entire pipeline, and you’ll have an ideal scenario: a great data model and great data infrastructure to support it.