
In the past few years, SQL and Python have emerged as the linguae francae of data. As of 2021, they are the 3rd and 4th most used programming languages, in large part because of their popularity among Data Scientists and Analysts.

They are sometimes presented as competing alternatives, and evangelists for one or the other are happy to proselytize the advantages of their preferred language. There’s also a perception that Python is for “real Data Scientists”, while SQL is for the less-technical masses. Despite being debunked multiple times over the years (an excellent and recent example being Pedram Navid's "For SQL"), the myth persists.
While it’s true that SQL is super approachable and Python has more flexibility, like any language they each have real strengths and weaknesses that manifest all throughout the data analysis process. You would expect analytics practitioners to leverage them both on a task-by-task basis wherever and whenever needed, lapsing into SQL for fast filtering halfway through a Python analysis. The issue, however, is interoperability.
Workflows in either language typically live in completely different tools. This creates a siloing effect, with users of one or the other unable to meaningfully collaborate on an analysis or workflow. It also creates friction for users who want to learn new skills: the jump from writing a quick SQL query to installing and diving into Python is big, and intimidating. For those already confident in both SQL and Python, it's frustrating to have to decide whether to context switch between tools or just muddle through a workflow in Python that they know would be simpler in SQL.
Today, we’re changing this with the introduction of Dataframe SQL in Hex. Now you don’t have to choose between SQL or Python for a data task: they can be seamlessly combined in one workflow, drawing on the advantages of each language anywhere in an analysis.
To understand why this is such a profound change, let’s first review some history:
SQL: the OG
SQL has been doing data for a very, very long time. All the way back in 1974, Donald Chamberlin published a paper called SEQUEL: A Structured English Query Language. Here's an example he showed:

Yep, that’s SQL! In the 47 years since its initial emergence, very little has really changed about the core syntax. Database advancements and dialect-specific functions have brought more power, speed, and functionality, but these are all just helpful additions to the same core language.
One of SQL's main appeals is its ease and readability. The learning curve is very short, with a clean syntax that reads similarly to English. This makes it approachable for those newer to writing code or working with data.
And now, half a century in, SQL is having quite a moment. A few years ago it was looking like SQL might be eclipsed by distributed, non-relational NoSQL systems, especially for large-scale workloads. As far as analytics and data science are concerned, however, these alternatives have been fairly well vanquished. SQL has cemented its position as a universal interface for data, and a new generation of data tools is being built around it as a core principle. According to the makers of TimescaleDB, “balance has been restored to the force”.
Pythons and Pandas, oh my
Where SQL is renowned for primordial simplicity and efficiency, Python benefits from infinite flexibility and a rich ecosystem.
Python first emerged 20 years ago, and quickly caught on due to its readability and ease of use. As a fully-featured, object-oriented programming language, it can be used to develop complex logic well beyond what’s possible in SQL, whether that’s hitting an API or training a model. Pandas, the de facto analytics library for Python, provides high-performance DataFrames, the primary tabular structure for exploring, cleaning, and processing data in Python.
The ecosystem around Pandas is amazing, and essential to its popularity and dominance in Data Science. For almost any use case, you can be sure someone has already solved the problem and published some code that you can easily pull into your work and use on a dataframe. You can easily add in Geopandas to work with geospatial data, scikit-learn for machine learning, the endlessly customizable matplotlib for charts, or any of the 320,000+ other packages available on PyPI.
Other statistical languages, like R or Julia, have devoted followings and dynamic ecosystems. Javascript, too, is strong among creators of interactive visualizations. They haven’t yet, however, reached the same ubiquity as Python and Pandas.
A pair of star-crossed lovers
We've established that both SQL and Python have their own superpowers, and are useful for different things. Their amazing utility and ecosystem dominance means that in 2021, most technical data practitioners are bilingual in them to some extent. We are expected to be able to dabble in either, but of course have different levels of familiarity as well as strong preferences when it comes to certain tasks.
But they have never worked well together. It's not their own fault— the tooling around them conspires to keep them apart. A SQL-first user who wants to layer in a Pandas function would have to completely invert their workflow, move to a script or notebook, configure a secure database connection, and stuff all their queries into clunky wrapper functions without autocomplete or syntax highlighting. It's technically possible, but a really bad experience.

This is also a one-way street: the SQL is just there to get data into the Python context, with no way to go back and forth. Once your query becomes a Pandas dataframe, you’re stuck: no more WHERE for a simple filter, or quick aggregations with GROUP BY.
This means that moving between SQL and Python usually means downloading data and moving between completely different tools, which causes friction and fragmentation for users and teams. Projects are scattered all over the place, work is siloed, and SQL users especially have a big barrier to expanding their skillsets.
Introducing: Dataframe SQL
Many of us at Hex have felt this pain first-hand, and from Day 1 our vision was of a polyglot data workspace that allowed SQL and Python to work together on equal footing.
Earlier this year, we introduced a first-class SQL experience in Hex, adding easy-to-configure data connections, schema browsing, caching, and powerful query cells. This made Hex the easiest way to go from a SQL query to a Pandas dataframe... but it was still a one way trip.
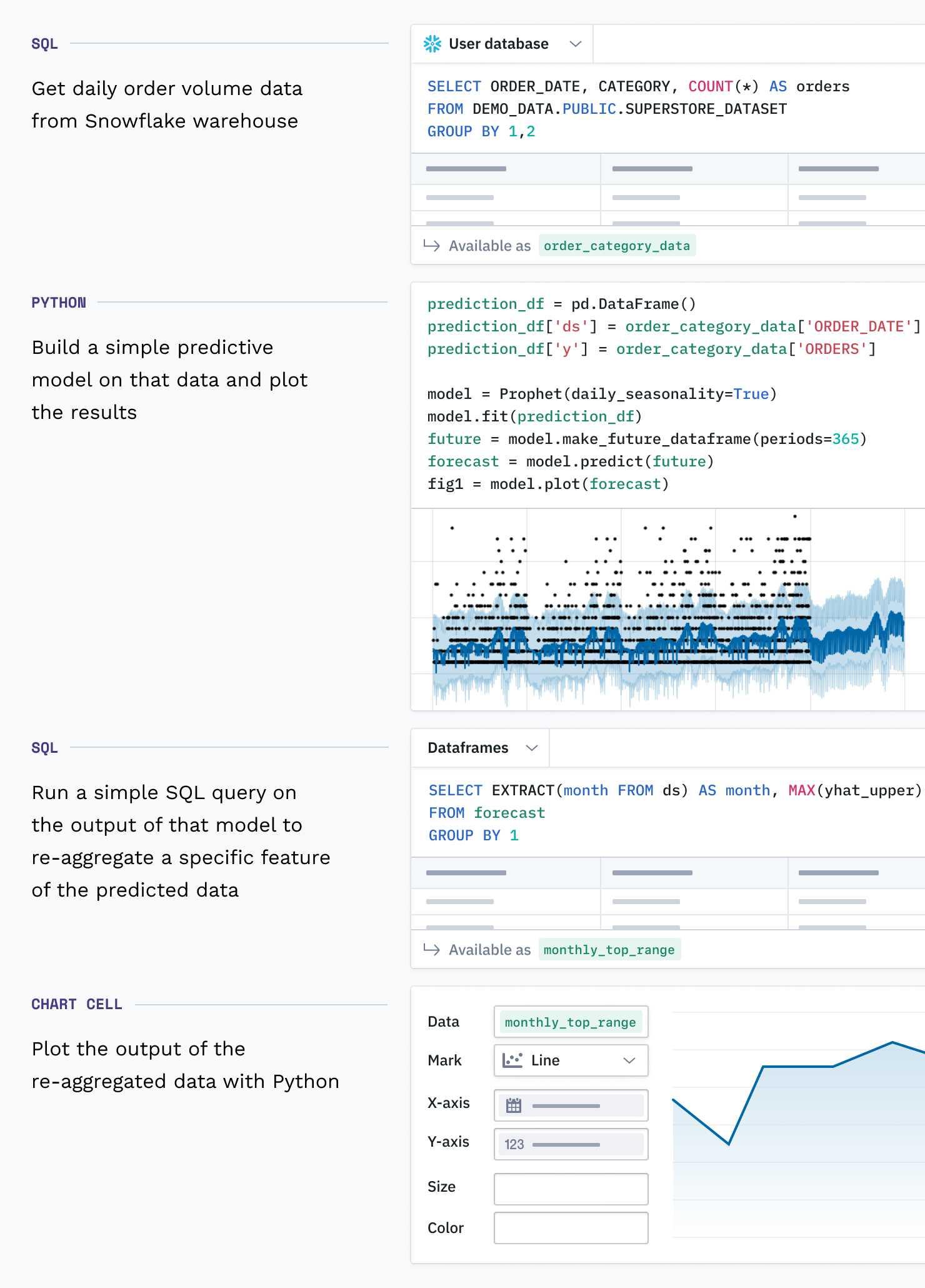
As of today, that street goes both ways: we’re introducing Dataframe SQL, a seamless way to work between languages in the same project. Hex SQL cells can now query other dataframes, whether they are the result of another SQL query or a Pandas operation.

All the features you’d expect to work for a typical query in Hex (schema browser, column autocomplete, etc.) now work on any dataframe in a project: the dataframes effectively form their own database.
Complex SQL queries using CTEs can be broken down into smaller units, forming a chain of statements operating on and passing down a dataframe from one to another. You can transition between languages in this chain as many times as you’d like, with any mix of languages, from all-SQL to all-Python and everything in between.
Wrapping up
At Hex we have always believed that truly empowering data users doesn’t mean getting rid of code, but embracing it. By making it simple to use SQL and Python together, we are now further lowering the barrier of entry and enabling a new set of powerful code-based workflows for data teams.
Want to give it a spin? Reach out about getting access. We can’t wait to see what you do with it!