
What happens when a computer can write SQL or Python better than any human? Do all the data jobs go away?
This is the basic form of a complex question that people are asking in the Age of LLMs; as it turns out, a lot of data practitioners’ tasks are both highly specialized (e.g., require arcane knowledge of pandas or SQL syntax) and also pretty rote (e.g., writing out that same syntax over and over). And those happen to be the kind of tasks that LLMs seem really well suited for. So, it's easy to imagine the Executives gearing up to replace all the data people with computers.
The future is weird and uncertain, but I really don't think that's what's going to happen.
First, the job of a data practitioner is a lot more than just writing code or making charts. Knowing what questions to ask, or how to ask it, or anticipating the next twenty things that the Head of Marketing is inevitably going to want are not specialized nor rote, and don’t feel particularly at-risk from LLMs.
But one may still worry that we will require less humans to do these things. With AI, each task may require fewer human hours to complete – does that mean we require less human hours overall?
I actually think it means we might need more – and to understand why, let’s take a journey back to the 19th century.
Jevons’ Paradox
In 1865, the economist William Jevons noticed that as technological improvements made coal-powered engines more efficient, the overall consumption of coal went up. This is counter-intuitive: if the engines burn less coal, wouldn’t you burn less coal overall? Unfortunately for our atmosphere, it’s quite the opposite.
Jevons' Paradox, as it’s now known, is an example of a “rebound effect”, where the expected gains from efficiency are offset by changes in behavior. In the original case, as coal engines got more efficient, it got cheaper to generate each watt, which in turn stimulated a ton more generation.
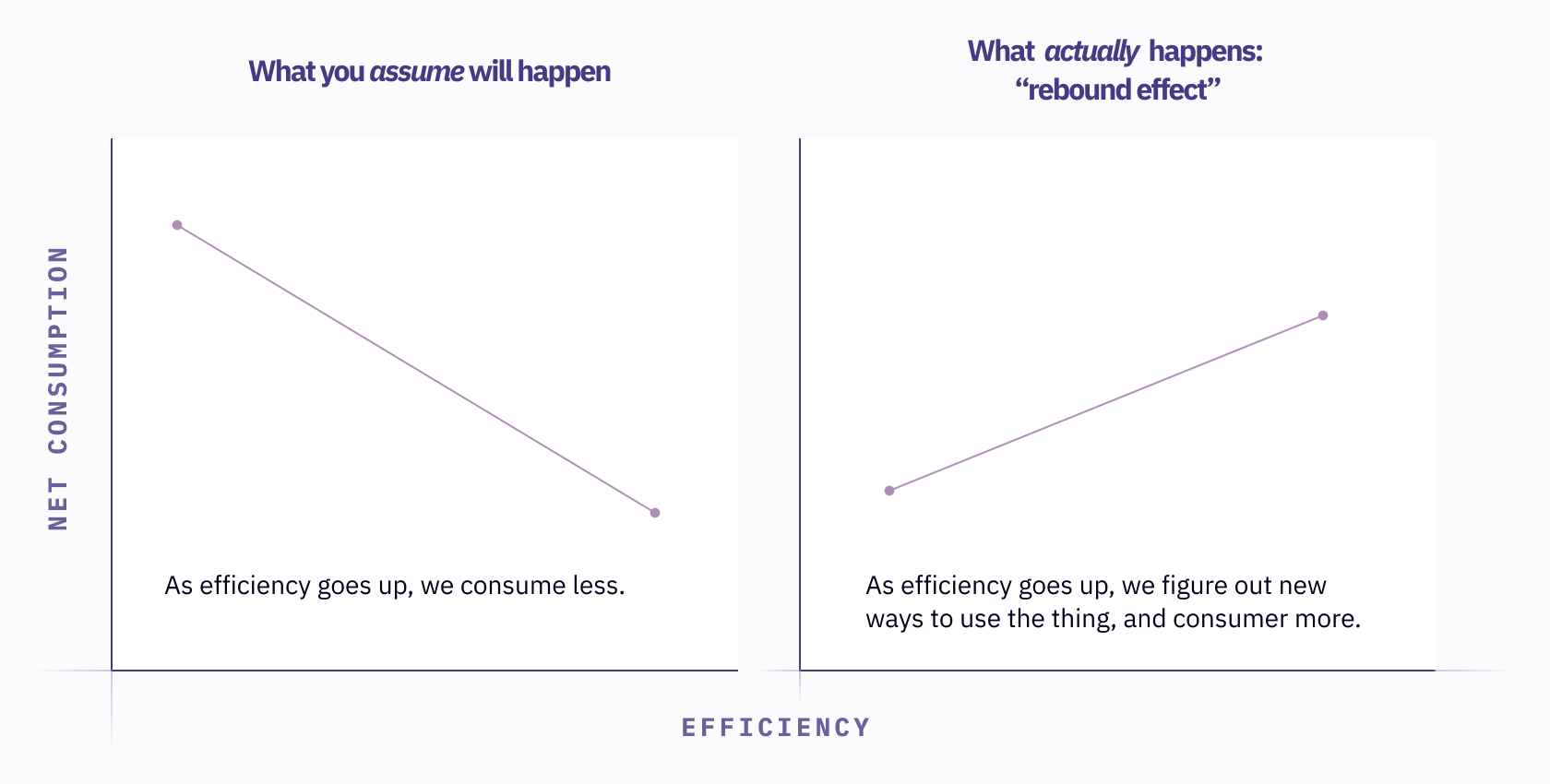
It turns out there was enormous untapped demand for power! By reducing the cost to generate it, people found all sorts of new ways to use it. They started using it to run looms, and move trains, and light houses, and power weird science experiments. In fact, it got so cheap that people started building standalone engines to power factories, so even though they were using less coal for the same power output, the overall number of engines and running hours increased, leading to greater total coal consumption.
Cheap, abundant energy completely changed society, and we kept inventing new things to do with it, so kept needing and producing more of it.
The enormous untapped demand for insight
Coming back to the 21st century, we’re sitting on the precipice of a step-change in the cost to generate insights, and I think we’re going to see a similar rebound effect with AI.
It may be correct that we require less human hours to do data tasks on a micro level: I certainly think data practitioners will be spending less time writing boilerplate or casting types than we do today.
But the demand for data work isn’t fixed; there's not some finite number of stakeholder questions, or decisions that could informed with data. In fact, we’re deeply supply constrained! The number of insights an organization generates is a function of the size of the data team, which is the result of a financial budgeting process – not a bottoms-up supply-demand matching exercise. In every organization, there are way more questions that could and should be answered.
And data teams are sitting on an enormous supply of potential answers! We have spent the last decade re-building our data stacks around infinitely-scalable cloud warehouses and their attending ETL tools. It’s a (wait for it) massive coal mine just waiting to be turned into energy. And as that process gets more efficient, we’ll find a lot of new ways to use it. We’re nowhere near the theoretical limit of the impact data can have on our organizations.
Is AI going to change how we work? Yes. Does anyone know exactly what’s going to happen? No. But if history is any guide, I don’t think we’re going to be firing all the analysts or data scientists – it might be the opposite.
If this is is interesting, click below to get started, or to check out opportunities to join our team.