Blog
How to Get Your Data From Postgres to Snowflake
Extracting from a production PostgreSQL database and loading into Snowflake



There comes a day in every piece of data's life when it has to leave the cozy home of your production Postgres database and spread its wings in an analytical warehouse.
So how to get it from here to there? We’ll run through three ways to extract data from your Postgres database and load it into a Snowflake warehouse:
- Using a connector like Fivetran or Stitch
- Using Python as a wrapper for SQL commands
- Using SQL utilities from the command line
They are ordered in increasing levels of complexity, but you should choose the one that works best for your situation.
Option 1: Just use a connector
Writing code is fun. But do you know what’s more fun? Getting someone else to write code for you! That’s what Fivetran, Stitch, Airbyte, Weld, Rudderstack, and a ton of other data integration products have done. Here we are going to use Fivetran, but the process is going to be extremely similar across any of these tools. We have a ‘users’ table set up in a Heroku (RIP) Postgres instance that we’re going to be using throughout.
Once you’ve signed up for Fivetran, go to Connectors and click ‘Add Connector.’ On the next screen, search for your type of Postgres database. We are using Heroku, so we’ll choose ‘Heroku Postgres’ and click ‘Continue Setup.’
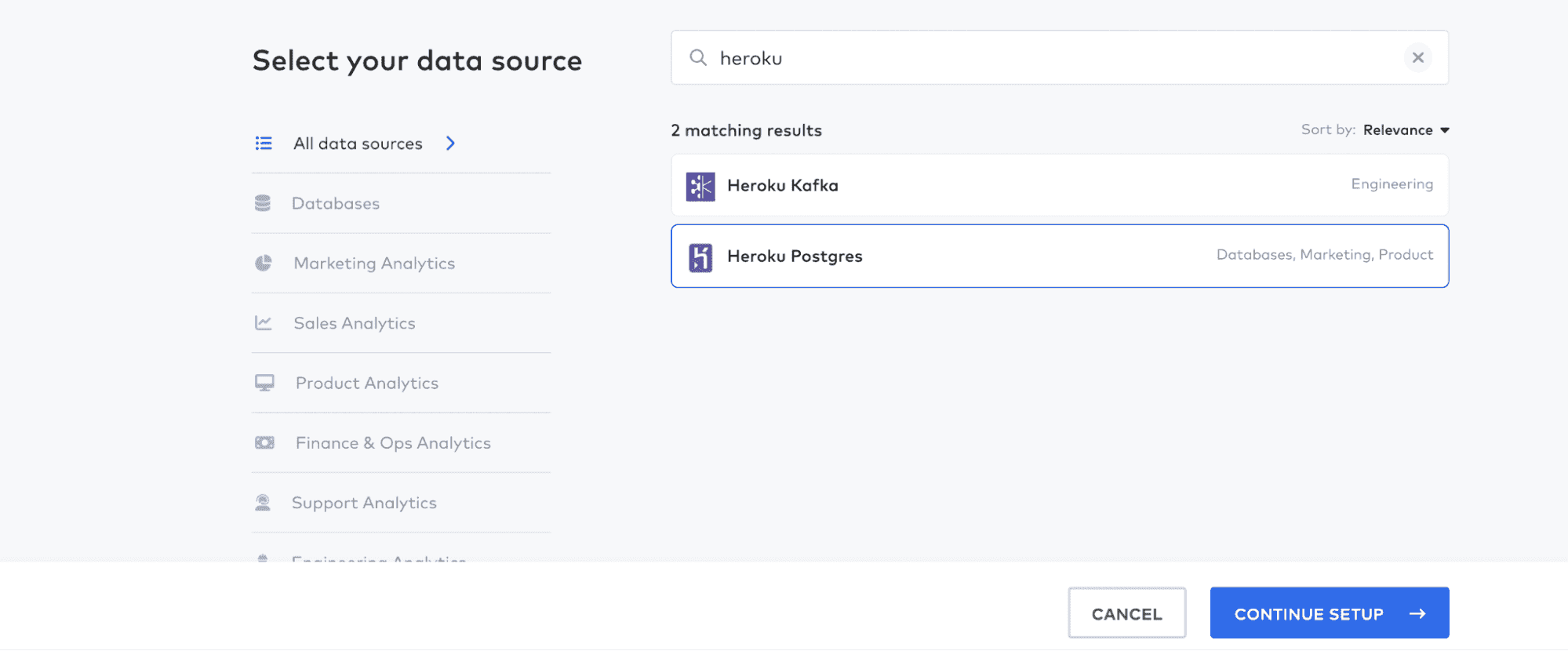
On the next page, you’ll have to enter the information to connect to your database. For Heroku, you can find all the information you need by going to the Resources tab, clicking on your ‘Heroku Postgres’ instance, and then ‘Settings’ and ‘View Credentials’:

Enter all this information:
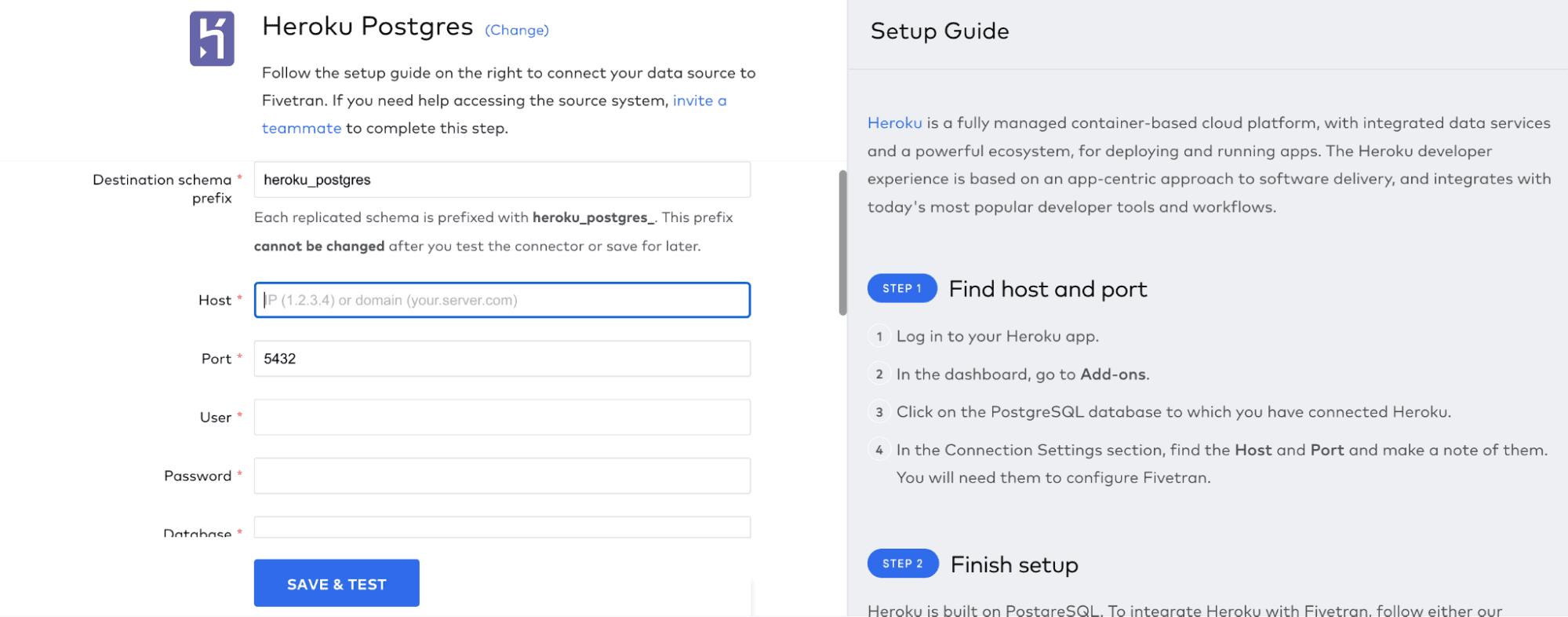
Click ‘Save & Test’ and Fivetran will test the connection. First time you do this, you will be asked to validate the security certificate for your TLS connection:
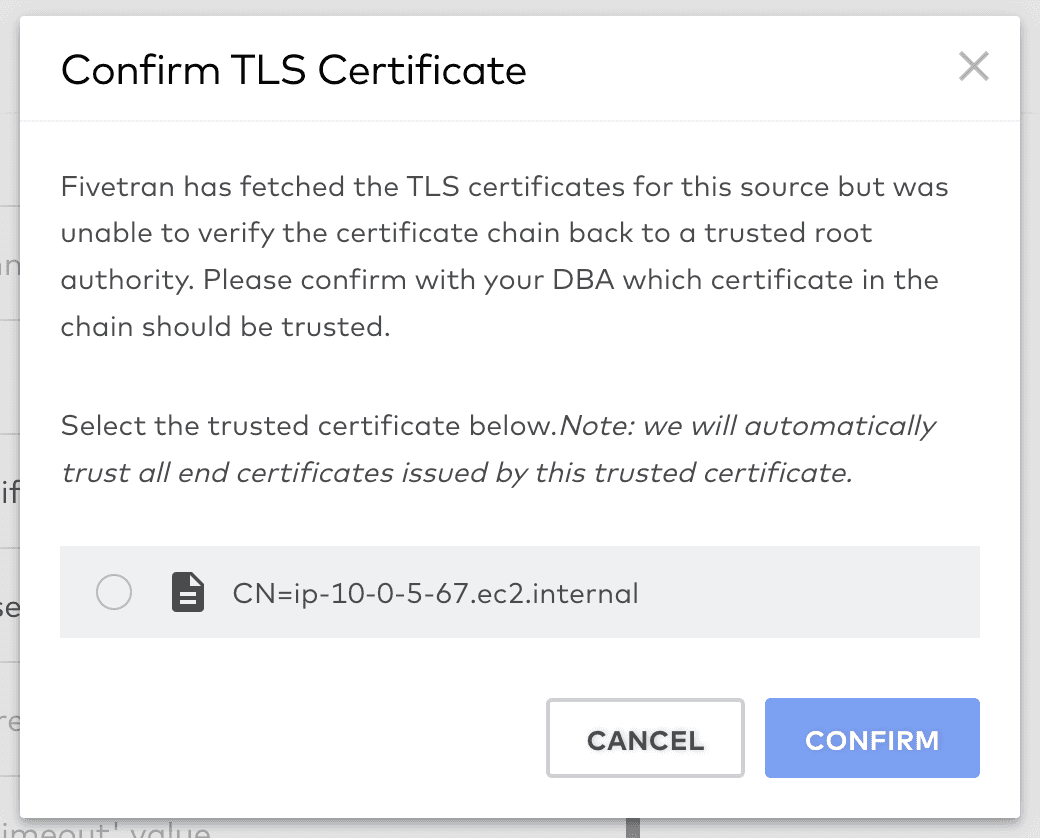
Select and Confirm. If all goes well you’ll see this screen:
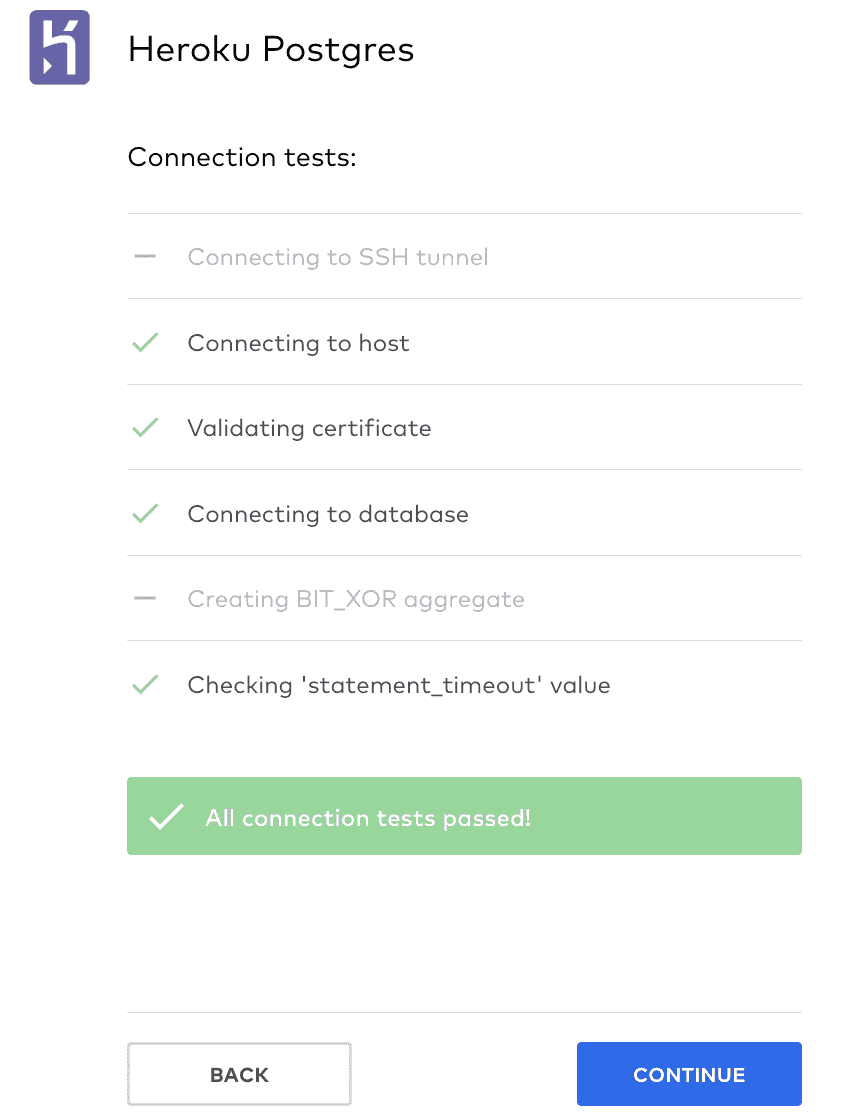
If not, go back and check all your creds. If you are able to get here successfully, click ‘Continue.’
And that’s it from the Postgres side. Fivetran supports different flavors of PostgreSQL (Amazon Aurora, Azure, Google Cloud, Heroku, Amazon RDS, and local Postgres). All will have slight tweaks to this setup process, mostly around making sure you grant the right access to Fivetran. Check out their docs for more info.
The Snowflake side is a little bit more involved, mostly due to those access details. But it starts in a similar way—this time go to ‘Destinations’ and click ‘Add Destination’, then search and choose Snowflake and click ‘Continue Setup’:
Next, you get the same type of information page as before:
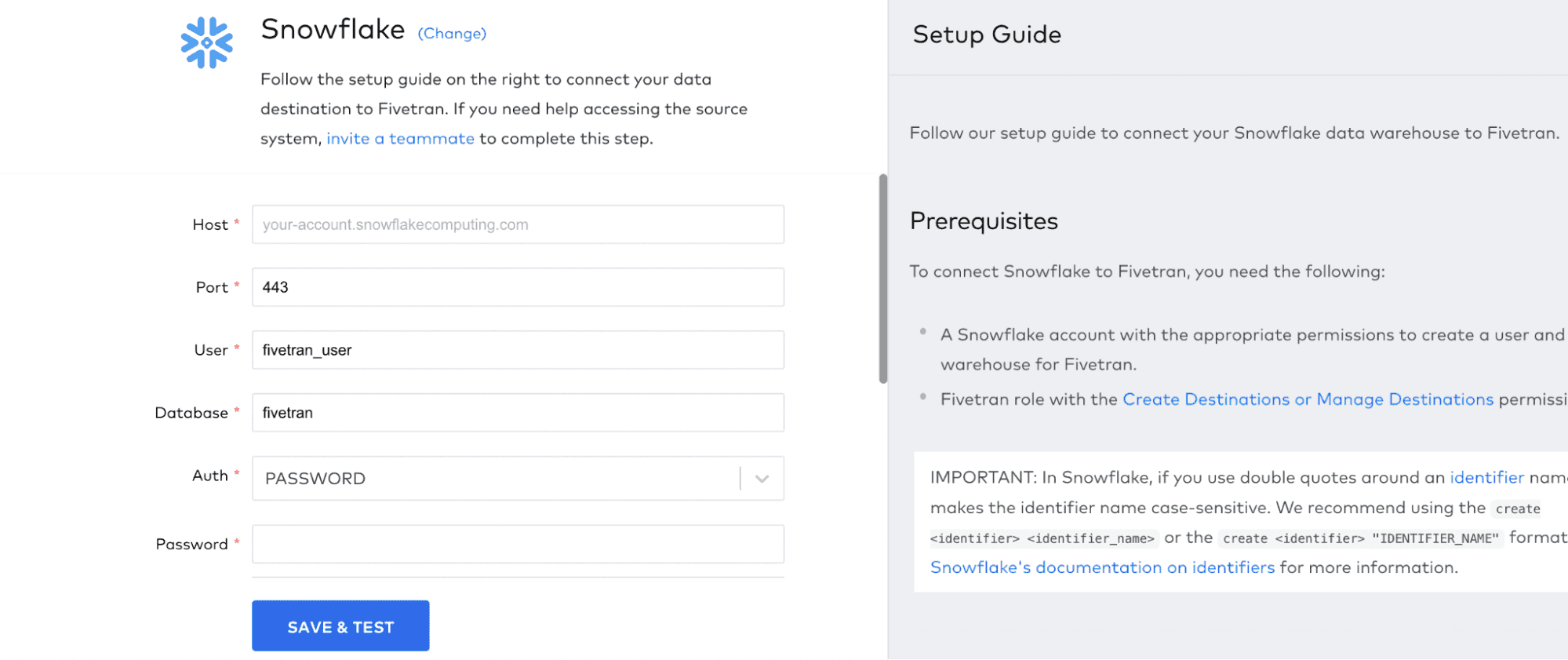
What you add is a little different here. Some of it, like the ‘Host’, you already have.
Not sure where to find this information?
Your account identifier is everything between https:// and .snowflakecomputing.com in your Snowflake web URL. If your URL is https://ab12345.us-east-2.aws.snowflakecomputing.com, then your account identifier is ab12345.us-east-2.aws.
You can find data warehouse, role, database, and schema information from the Context menu in a new Snowflake worksheet.
But the other details you are going to load into Snowflake with SQL first and then enter here. Don’t worry, the entire SQL command is in the pane on the right-hand side of the connect screen in Fivetran, you can just copy and paste. Fivetran is very helpful in guiding you through the setup for connectors and destinations:
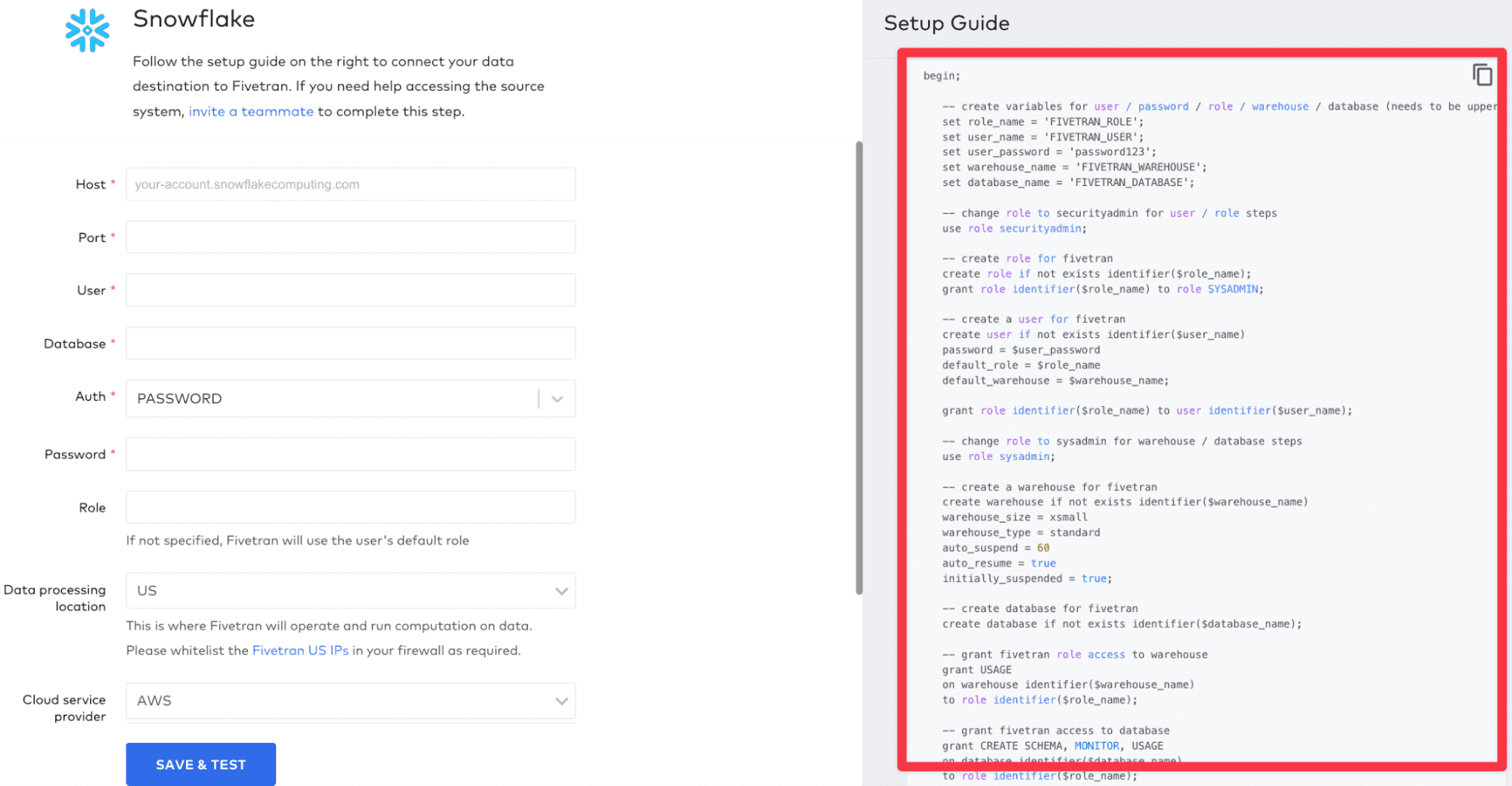
What this SQL command does is:
- Sets your role in Snowflake as a ‘securityadmin’
- Creates a user in Snowflake with the details you set (default is ‘FIVETRAN_USER’) and also gives them a ‘securityadmin' role
- Changes your role to sysadmin
- Creates a new warehouse (default = ‘FIVETRAN_WAREHOUSE’)
- Creates a database in that warehouse (default = ‘FIVETRAN_DATABASE’)
- Gives the Fivetran user access to that database
You then have to run another SQL command to create a network policy to give Fivetran's IPs access to Snowflake. Again, deets are in the right-hand panel.
The discerning reader will note that this is quite a bit of warehouse access to give to a third party tool: if you’ve got the power to do so, good on you. Otherwise some Slacks may need to be exchanged with a db admin – at the moment this is the only way to sync with Snowflake via Fivetran.
(Side note: Snowflake has ‘simplified’ their dashboard recently. To get the above commands to work, Fivetran says you have to check the ‘All Queries’ checkbox on the worksheet, which doesn’t appear in the new version. We suggest going back to the ‘classic editor’ to get the above done with no hassle.)
After that, you can come back to Fivetran and add in the details for that Fivetran user you just created. Click ‘Save & Test’ and hopefully all should be good.
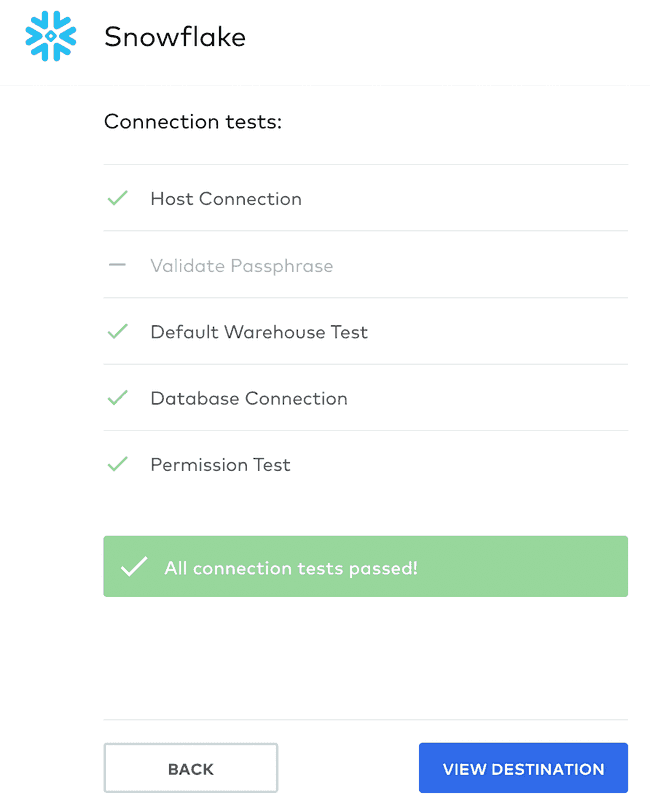
Excellent, you are connected. Now to sync your data. First, select all the data you want to sync from your Postgres database and click ‘Save & Continue’. Note that Fivetran automatically scans your source database’s schema so you never have to leave the UI.
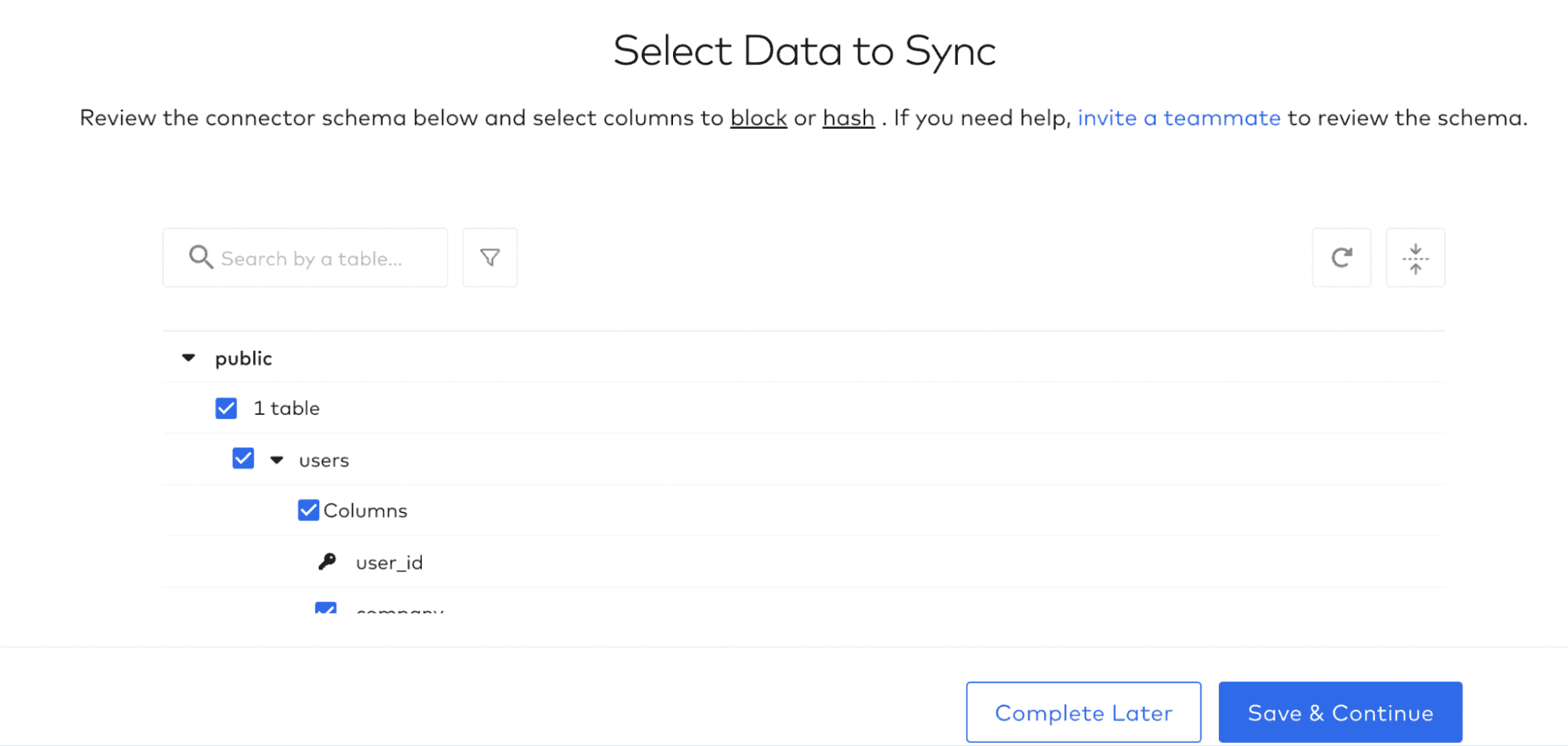
Then decide how you want Fivetran to deal with future changes to your schema:
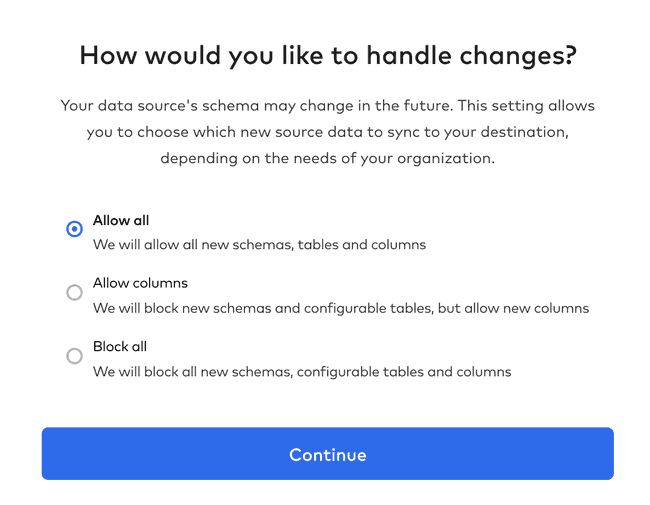
Once you click continue your first sync will start:
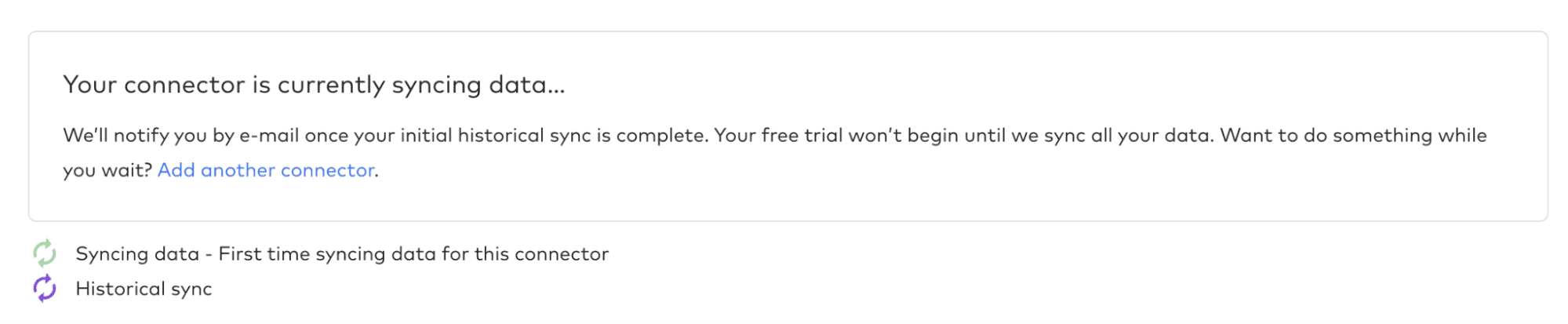
This will be a ‘Historical sync’ where Fivetran will replicate all of your data that you selected. Going forward though, a huge benefit of these data integration tools is that they’ll dutifully continue to sync your data automatically. You can schedule them to extract your data on a schedule, from once a day down to once every few minutes if you have real-time data you need to analyze.
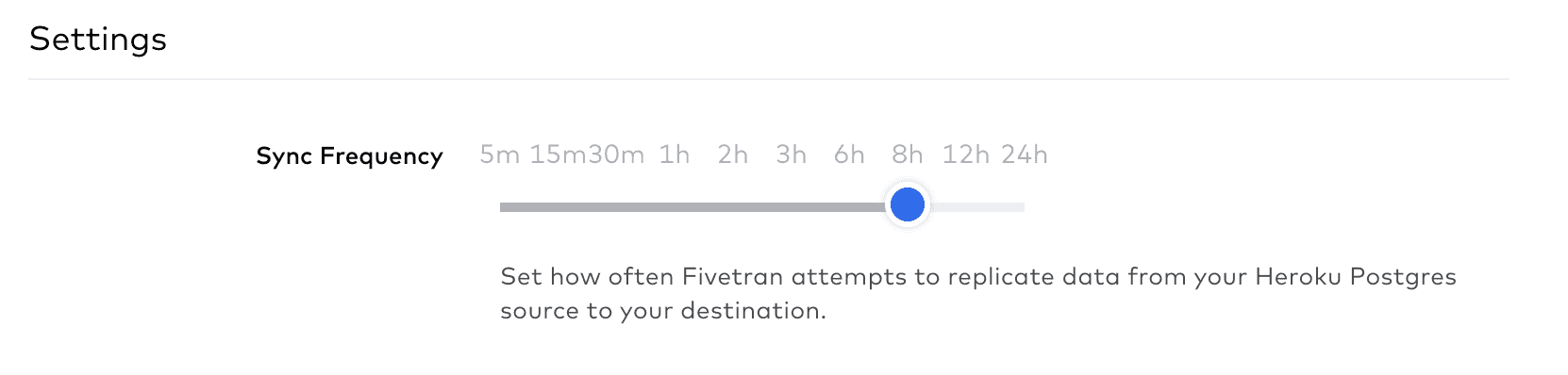
They do this through one of two mechanisms:
- Log-based replication. Every
INSERT,DELETE, andUPDATEchange you make in your Postgres database is saved in a log. Log-based replication uses this log to see what’s changed since the last update and then changes only that data. This is much quicker and less resource-intensive than replicating the entire database each time. - The hidden XMIN column. Sometimes log replication doesn’t work (like with Heroku, who locks down a lot of the options on their Postgres databases, including adding the external replication user roles needed for log-based replication). The fallback is using the hidden XMIN column in each Postgres database. This field is basically a ‘last modified’ field for Postgres, so Fivetran can traverse this column looking for change times since the last sync. The downside to this is time, as the system has to go through and check the XMIN of every row, and if you have deleted something, Fivetran can’t tell (as there is no XMIN to check).
Once the sync is complete, you can check Snowflake for the data:
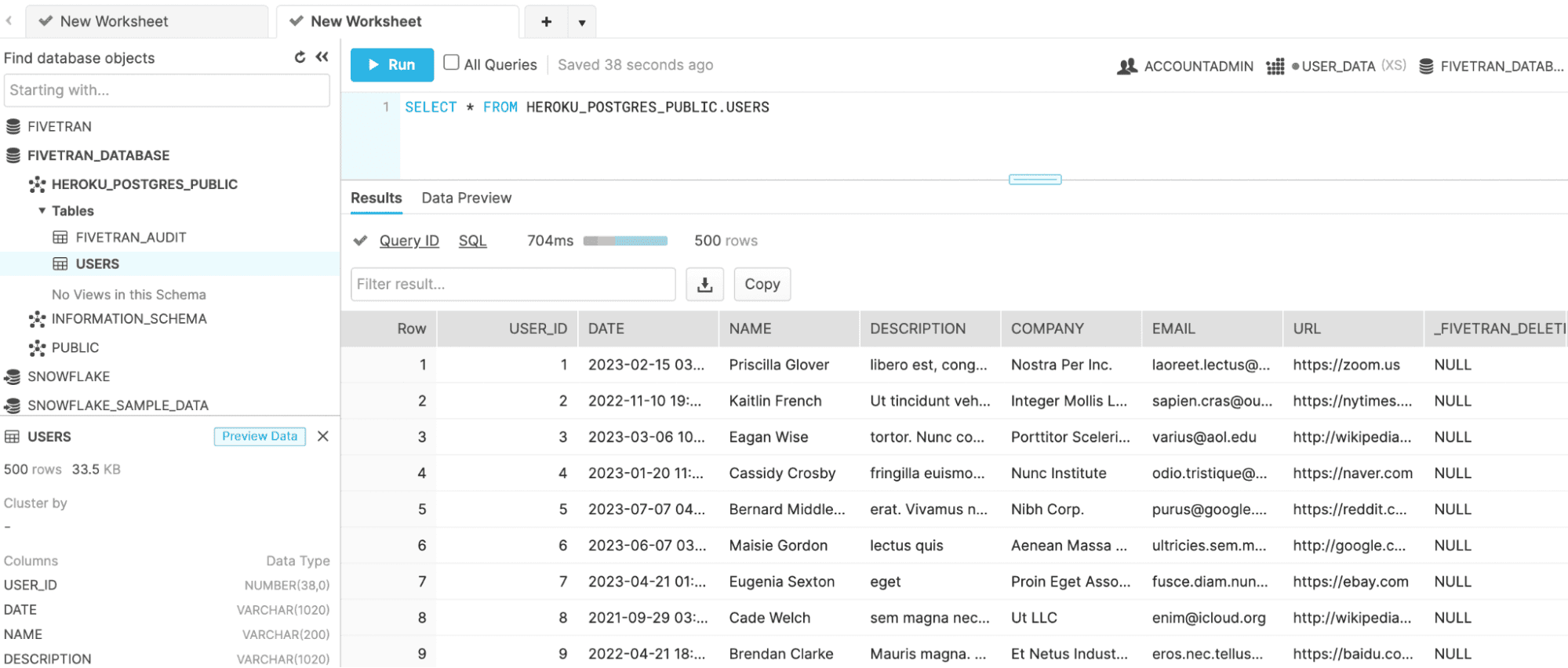
This entire process is, aside from the credential searching, extremely straightforward. So why not always use this? Well, you have to pay for it. Most data integration tools offer usage-based pricing based on rows of data. The more rows you have, the more you are going to pay. You might also have some intermediary steps you want to take with your data (such as cleaning) before you give it up to Snowflake and to the mercy of dashboards. Though even there, Fivetran integrates with dbt so you can run transformations on any new data arriving in your warehouse.
If you want to keep costs down or want to play with your data more, the other two options might suit you better.
Option 2: Use Python and psycopg2 as the middleman between Postgres and Snowflake’s Python connector
“I wanted to call it psychopg (a reference to their psychotic driver) but I typed the name wrong.” -Federico Di Gregorio, creator of psycopg2, on its interesting name
Di Gregorio is basically beating on some interns in that post, but props to him—psycopg is good and the main PostgreSQL ORM for Python. It lets you run SQL commands on your database from your Python code.
To get our data from Postgres to Snowflake we’re going to use psycopg to extract, and then Snowflake’s own Python Snowflake connector to import.
We’ll create a file called ‘pg-to-snowflake.py’, install both libraries with pip install psycopg2 snowflake-connector-python, and then import both, along with a csv module:
import psycopg2
import snowflake.connector
import csvWe then build a connection to our Heroku Postgres with the connect() method, using the information from our Heroku credentials page:
postgres_connection = psycopg2.connect(
database=<database>,
user=<user>,
password=<password>,
host=<host>,
port='5432'
)Then create a cursor, which is what’s going to traverse your table and extract your data:
postgres_cursor = postgres_connection.cursor()We can also use this cursor to find out information about our table in Postgres. We want to not only transfer our data to Snowflake, but also the table schema. Let’s first get our table name:
postgres_cursor.execute("""SELECT table_name FROM information_schema.tables
WHERE table_schema = 'public'""")
table_name = cur.fetchall()[0][0]Then get the column names and data types:
postgres_cursor.execute("""select *
from information_schema.columns
where table_schema NOT IN ('information_schema','pg_catalog')
order by table_schema, table_name""")Then use that information to build SQL that will create the same columns in our Snowflake database:
schema = "("
for row in cur:
if row[7] == 'character varying':
schema += f"{row[3]} string, "
elif row[7] == 'integer':
schema += f"{row[3]} {row[7]}, "
schema = f"{schema[:-2]})"Postgres and Snowflake data types aren’t an exact relationship e.g. “character varying” in Postgres and “string” in Snowflake, so you might have to replace some of the text, like above. We’ll use schema in a moment.
Then you can execute your SQL commands using the cursor. Here we just need to get all the data from our users table and store it in memory:
postgres_cursor.execute("SELECT * FROM users")
rows = postgres_cursor.fetchall()After that it’s vanilla Python to save the data into a csv:
with open('users.csv', 'w') as f:
writer = csv.writer(f)
writer.writerows(rows)We’ll then be good programmers and clean up after ourselves:
postgres_cursor.close()
postgres_connection.close()If you were to run just this now you’ll have a .csv file with all your data ready to upload to Snowflake. To get that data into Snowflake, the code is pretty identical to the code to get it out of Postgres. First, we connect:
snowflake_connection = snowflake.connector.connect(
user=<username>,
password=<password>,
account=<account>
)where:
- <username> is the username you use to log into Snowflake
- <password> is the password you use to log into Snowflake
- <account> is your account on Snowflake (the bit in your URL before ‘.snowflakecomputing.com’)
Then we instantiate our cursor:
snowflake_cursor = snowflake_connection.cursor()First, we want to recreate our database and table schema in Snowflake. This creates and sets a database for use:
database_name = 'python_database'snowflake_cursor.execute(f"CREATE DATABASE IF NOT EXISTS {database_name}")
snowflake_cursor.execute(f"USE DATABASE {database_name}")
And then we can use the schema we created above to deploy our table:
table_name = 'users'
snowflake_cursor.execute(
"CREATE OR REPLACE TABLE "
f"{table_name}{schema}")Then we execute all of our SQL commands to load the data:
snowflake_cursor.execute(
f"PUT file://users.csv @%{table_name}")
snowflake_cursor.execute(
f"COPY INTO {table_name} FROM @%{table_name} FILE_FORMAT = (TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY = '\\"')")The PUT command loads our data from our local file into a staging database (@%users) on Snowflake.
The COPY INTO ... FROM command takes the data from the stage (stages are how Snowflake manages data ingestion) and copies it into our users table that we created in Snowflake. The FILE_FORMAT = (TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY = '\\"') makes sure that the process understands this is a .csv file and that some fields might be enclosed by double-quotes. This is necessary if you have commas in any of your data. Otherwise, you’ll get an error like “Number of columns in file (11) does not match that of the corresponding table (7).”
Then what do we do? We tidy up:
snowflake_cursor.close()
snowflake_connection.close()If you run into any issues, we have a whole post on connecting to and querying Snowflake from Python.
Why do psycopg and the Snowflake connector look so similar? It’s not because they are the same thing in different clothes (as you see with Python dashboarding libraries), it’s because they both are well-written and use the PEP-249 standard for accessing databases.
When we check out our database in Snowflake we should see the data all loaded up:
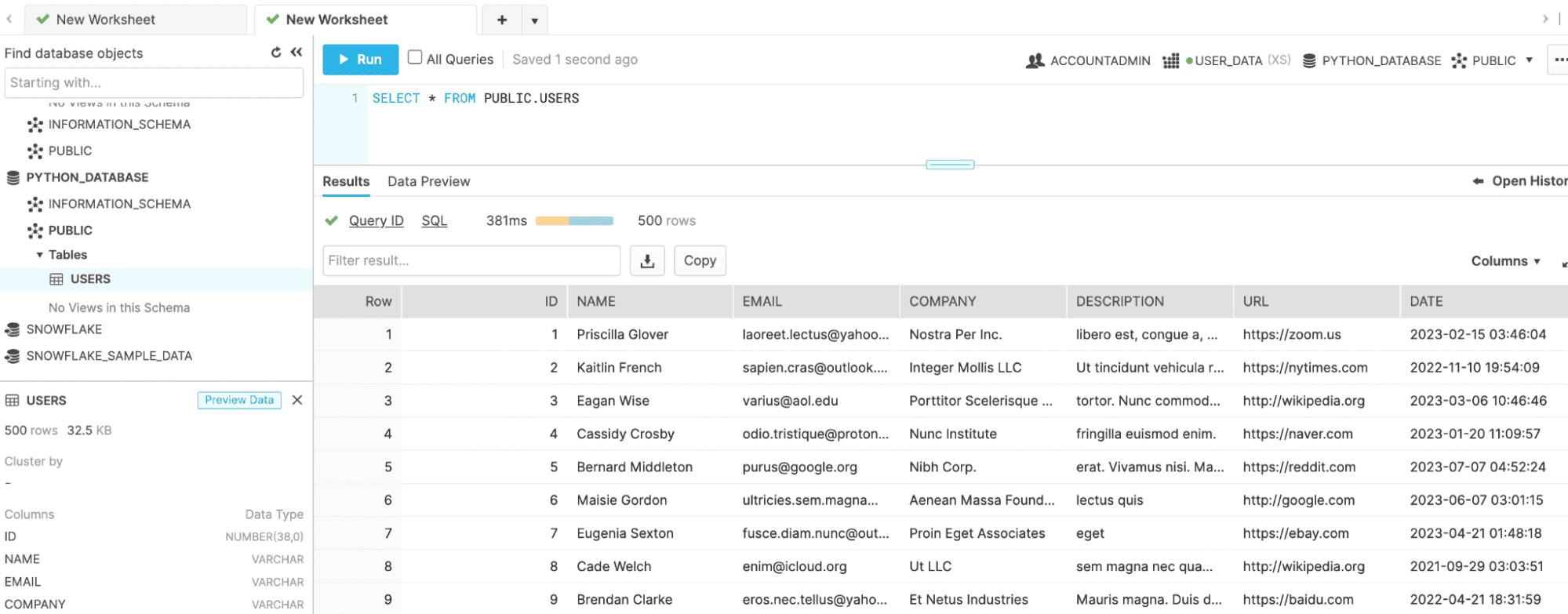
What if I have a ton of data?
This works fine when loading a 500 row example dataset. What if you have GBs of data in your Postgres database? Here are two options: split up the data into smaller files and load them separately, and/or use an s3 bucket as the stage. Snowflake always wants data in a stage, but this can be either an internal Snowflake stage or an external stage like an S3 bucket, if configured with the correct permissions.
Firstly, splitting. Say we had 1M rows and wanted to batch them per 100,000. We can SELECT just the rows we want:
postgres_cursor.execute("SELECT * FROM users LIMIT 100000")For the first batch, and save that as users_1.csv. Then we can use OFFSET to grab the next 100,000:
postgres_cursor.execute("SELECT * FROM users LIMIT 100000 OFFSET 100000")And save that as users_2.csv, and so on. We add all these to our stage and then copy into Snowflake using pattern matching:
postgres_cursor.execute("copy into users
FILE_FORMAT=(TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY = '\"') pattern='users_[0-9]+.csv';")Secondly, an external stage (e.g. an S3 bucket). The S3 method is a better idea if you are running this remotely (say, directly on Heroku) and you can’t save files locally.
You have to do quite a bit of setup in both AWS and Snowflake to set an S3 bucket as a stage. But Snowflake has outlined everything you need to do here.
Once you’ve created your bucket, policies, roles, and integrations, the code to move your files to your bucket and from there into Snowflake is light. First we need to pip install boto3 and import boto3 to work with our S3 bucket in Python. Then:
s3 = boto3.client('s3', aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
bucket = AWS_STORAGE_BUCKET_NAME
s3.upload_file(local_file_name, bucket, s3_file_name")You get your AWS credentials by going to your account (top-right in the console), choosing ‘Security Credentials’ and then ‘Access Keys’ and then ‘Create New Access Key’.
Your AWS_STORAGE_BUCKET_NAME is whatever you chose as you set it up. Then within upload_file, local_file_name is what you saved your file as (‘users.csv’ here) and s3_file_name is what you want to call it within the bucket.
Once the file is in S3, you use a similar SQL command as above with the staging database:
cs.execute("""
COPY INTO users FROM s3://<bucket>/
STORAGE_INTEGRATION = <integration_name>
FILE_FORMAT=(TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY = '\"')")
""".format( aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY))Of course, you can do both these together–split up your files and then load sequentially from an S3 bucket.
Option 3: Use Postgres utilities directly from the command line
If you are one of those developers that just can’t bear to be separated from your command line, you can do this entirely through CLIs.
You need two utilities installed for this: psql and snowsql. The easiest way to get psql is via Postgres.app and snowsql is another Snowflake-built utility. You connect to your Postgres database with psql. With Heroku it’ll be:
heroku pg:psql -a <app-name>If this is your first time using the Heroku CLI, it’ll open up the browser to get you to sign in.
Once logged in, you’ll no longer be on the command line, but working directly on the database and using straight SQL. Mostly this is the same as in the Python example, just without the Python wrappers. For instance to get the table name, you can:
SELECT table_name into table_name FROM information_schema.tables WHERE table_schema = 'public';There is one difference there: we’ve added into table_name. This lets us save our table name into a variable within the SQL shell for future reference.
The same goes for our schema:
select * into schema from information_schema.columns where table_schema NOT IN ('information_schema', 'pg_catalog') order by table_schema, table_nameYou can copy the data out via:
\\copy users TO users_db.csv WITH (FORMAT CSV);This will again give you a local .csv file. To get that into Snowflake we’ll use snowsql:
snowsql -a <account> -u <username> -d <snowflake_database>where:
- <username> is the username you use to log into Snowflake
- <account> is your account on Snowflake (the bit in your URL before ‘.snowflakecomputing.com’)
- <snowflake_database> is a database with your users table that you’ve previously created in Snowflake
You’ll then be asked for your Snowflake password. Create a new database:
CREATE DATABASE IF NOT EXISTS UTILS_DATABASEAnd then set it as the current database:
USE DATABASE UTILS_DATABASESetting up the table and schema is a little more tricky as we can’t nicely use string concatenation and f-strings in SQL. So we’ll have to do it more manually, though we can use the table_name variable from earlier:
CREATE OR REPLACE TABLE table_name (user_id integer, name string, company string, email string, description string, url string, date string)Then we can use the same PUT and COPY INTO commands as with Python. First PUT the file into staging:
PUT file://users_db.csv @%users;Then copy into the main table from that staging:
COPY INTO users FROM @%users FILE_FORMAT = (TYPE = CSV FIELD_OPTIONALLY_ENCLOSED_BY = '\"');And you are done. Once again the data appears:
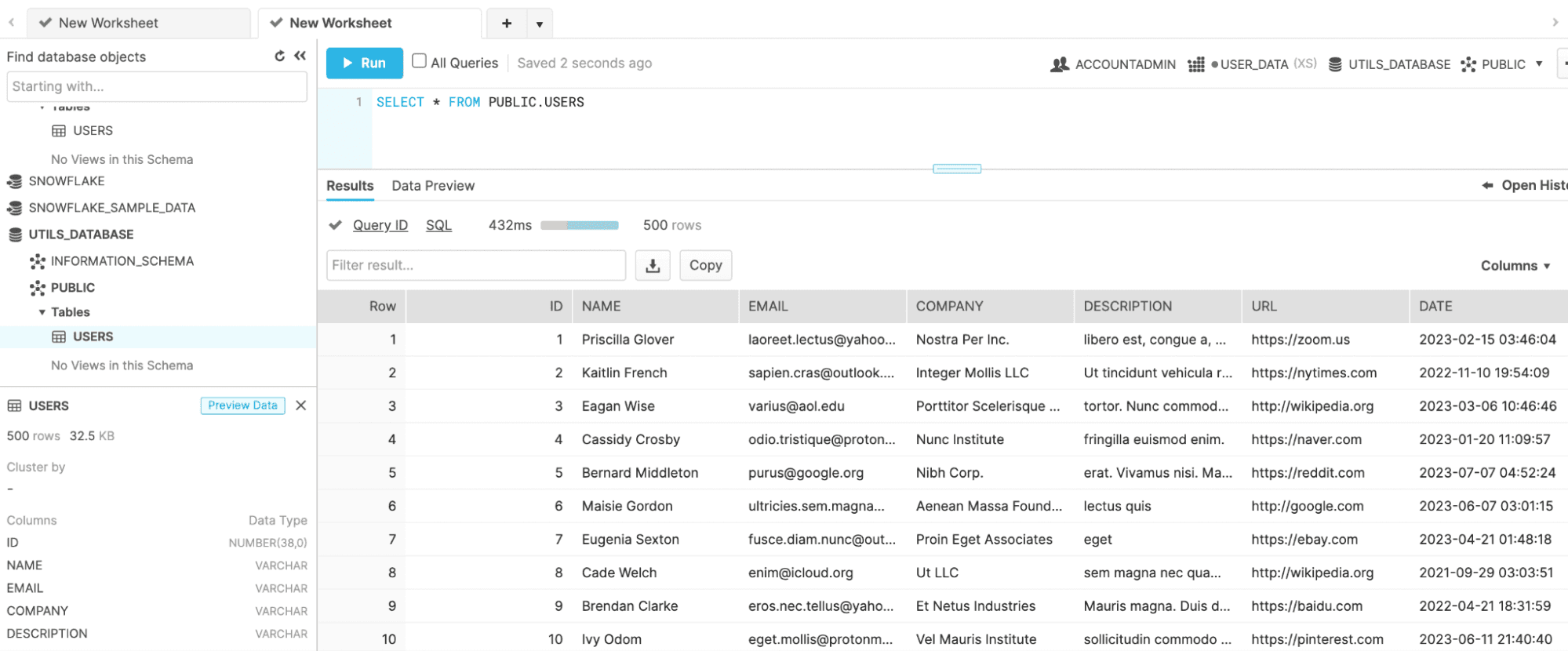
If you are scheduling this, you can include an OVERWRITE = TRUE in your COPY INTO command. This will make sure you aren’t duplicating data.
Summarizing your options to get data from Postgres to Snowflake
If you want to set it and forget it or always have up-to-date data, then a connector is the way to go.
If you need to do some work on your data before it sees a warehouse, then the Python route is the best option.
If you just love that CLI life, the psql and snowsql option gives you a ton of flexibility in what you want to do.