Blog
Notebooks weren't built for the modern data stack
Our tools for exploration and analysis are living in the past.

Computational notebooks might seem like a recent phenomenon, but they have actually been around for many years. The first data notebook, Mathematica, was developed in the 1980s, and Jupyter (then iPython) was first introduced in December 2011.
In the intervening decades, however, a lot has changed in the data world. Unfortunately, data notebooks haven’t kept up with these changes, and today they feel like relics of a bygone age, despite being used for analysis and modeling workflows by many thousands of data practitioners. The rest of our tools have evolved into a "modern data stack", but most notebooks are moving in the past.
The shortcomings of notebooks will be familiar to anyone using them day-to-day, and can be broken down into 3 big buckets:
- Scale - notebooks can’t handle the size of data we’re storing in the cloud
- State - notebooks have confusing and frustrating compute models
- Sharing - notebooks weren’t built for teams
Scale: data notebooks weren't built for the cloud
Probably the biggest story in the last 10 years has been, well, big data. Cloud data warehouses and data lakes can now flexibly handle all of an organization’s information, at reasonable cost. Terabytes of data can be stored in easy-to-query tables, and a bevy of new tools for extraction, transformation, and observability makes it simple to process. With this “modern data stack'', organizations can finally have complete, clean, reliable data assets available for analysis and modeling.
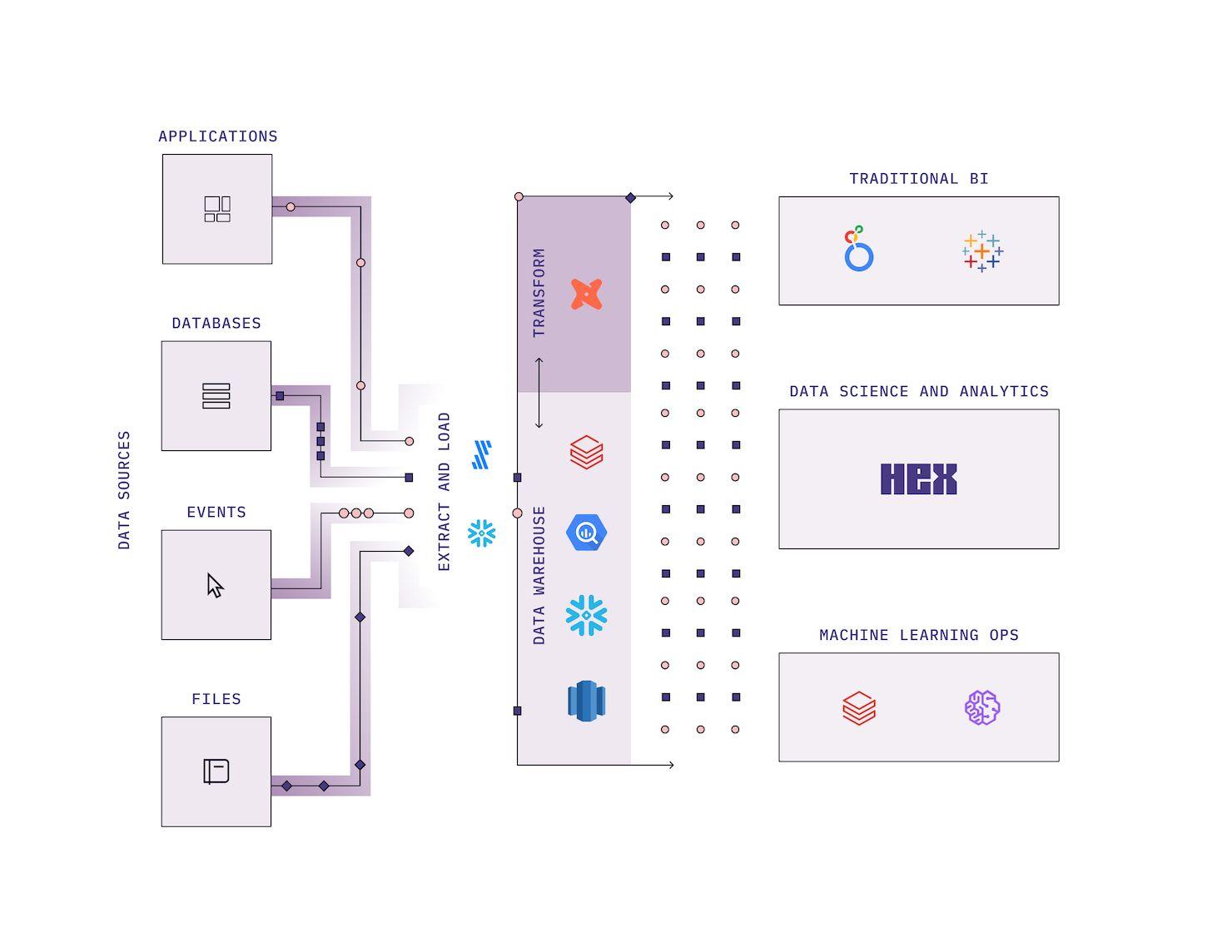
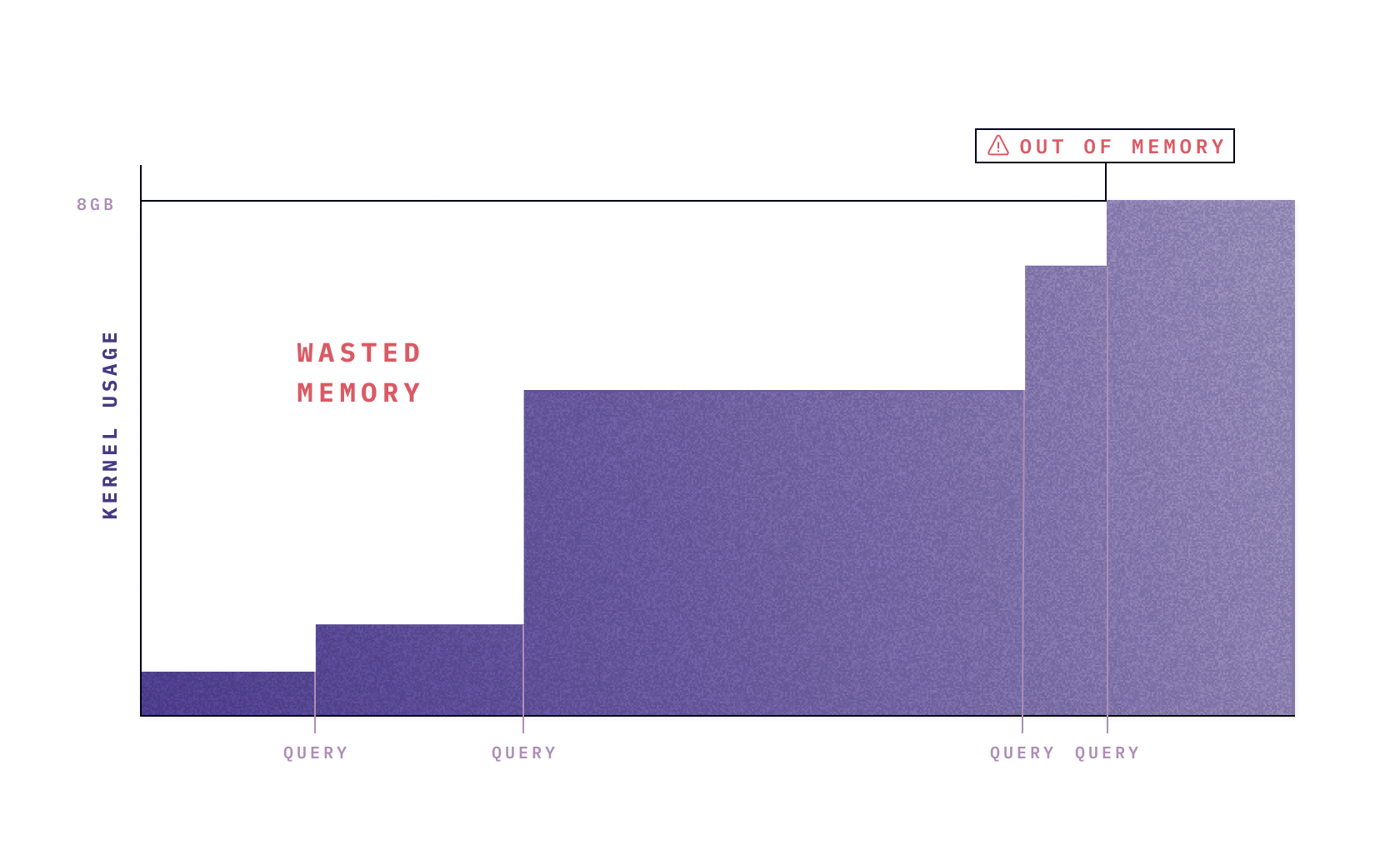
Notebooks, however, weren’t built for this world. In a traditional notebook, computation occurs in an in-memory kernel, which contains all the data you’re working with. These kernels can be fast, but are inherently limited by the memory capacity of whatever machine you’re running them on. This means that if you run too big of a query, you’ll blow up your kernel, lose your work, and have to re-build your workflows to use smaller samples.

If you’re still running notebooks locally, the data limit is the RAM installed in your laptop. Today, many data notebooks are run “in the cloud”, but now you’re just constrained by the size of the virtual machine you’re on. The only way to scale up your data workloads is with brute force, upping the memory for your kernel to 16, or 32, or 64GB, and so on.
This is expensive and inefficient: you’re keeping a bunch of memory wired up to store your data, but only occasionally running computations on it*.* In between operations, there’s a bunch of time where you’re thinking, or typing, or looking at charts, or playing Wordle, but you’re still paying for that big memory footprint.
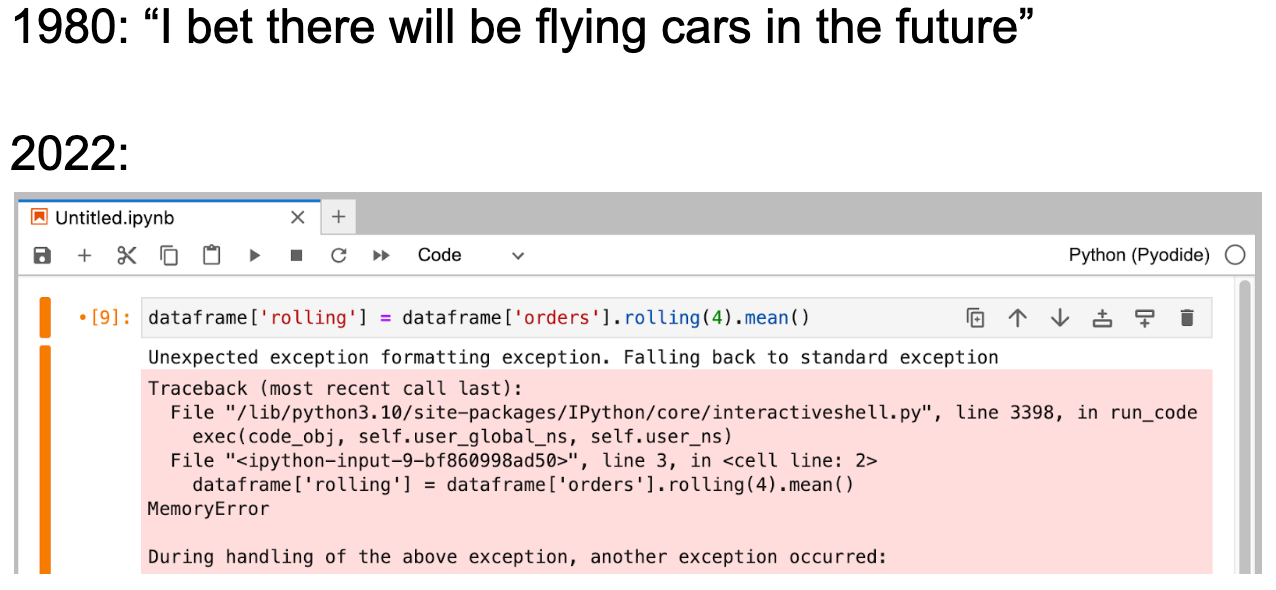
Most of us just want to run queries without having to also reason about memory management or running up huge compute bills. It’s 2022, and I have a cloud warehouse with all my data, but I can’t just use it? I can run select * from big_table in my cloud console, but in my notebook it crashes my whole workspace? I don’t worry about table sizes in my warehouse… why am I sweating dataframe sizes in my notebook?
State: the notebook execution model is broken
The way notebooks handle compute and memory state is a massive source of frustration, especially for beginners. This angst is most infamously documented by Joel Grus's "I don't like notebooks" talk at JupyterCon (video, slides).
The issue, in short: data notebooks are backed by a kernel, i.e., an in-memory process with mutable state. The commands run in each cell of a notebook modify that state, such as creating or reassigning a variable. You can run anything in a cell, and execute those cells in any order, meaning that the current kernel state can be difficult to reason about and reproduce.
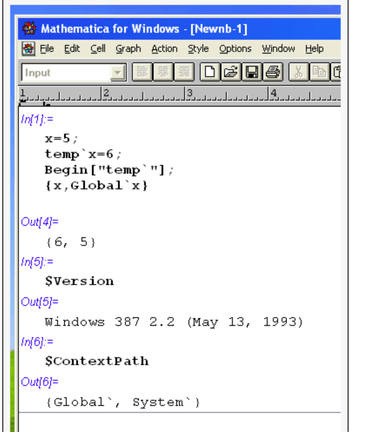
Check out this basic example: quick, what’s the current value of x?
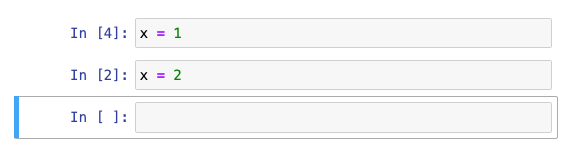
At first you might think 2, given it's the last cell. But you're a grizzled Notebook Veteran, so you look to the [execution order numbers] and see that the first cell was run most recently, and reason that it's actually 1. Ok, let's check:
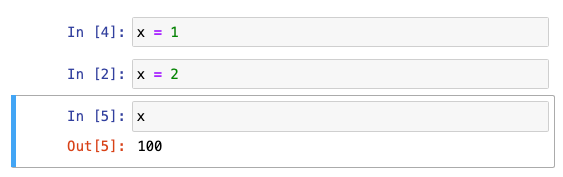
Oops, turns out the correct answer is 100, because the cell 1 was edited after it was previously run with x = 100. Better luck next time!
This is a really simple example, but as projects grow more complex, it’s very easy to tie yourself in awful state knots. You run a few cells out of order to test some things, or avoid running an expensive chunk of logic, and suddenly you’re seeing weird, inconsistent outputs. There isn’t a great solution to this, other than building up a complex state map in your head, or frequently restarting your kernel and running everything from scratch.
This causes three major issues:
- Interpretability: it’s hard to reason about what’s happening in a data notebook, whether it's your own or someone else’s.
- Reproducibility: because cells can be run in any arbitrary order, reproducing a current state can be difficult without frequently re-running all the logic from scratch.
- Performance: re-running everything from scratch can be wasteful and time-consuming. This is true for any notebook, but unfortunately it's especially painful in Hex: published Data Apps run all of their logic top to bottom every time, explicitly to avoid weird state issues. While elegant, this has obvious performance implications if cells contain expensive logic like a query or model re-compute.
Sharing: notebooks weren’t built for teamwork
Traditional notebooks do basically nothing when it comes to making it easy to work with others, as co-editors or consumers. They were built for an older era, when most data work was done locally on one individual’s laptop, and feel out of place in the era of modern cloud productivity software.
Trying to work together on a notebook is somewhere between infuriating and impossible: you’re sending back-and-forth a hard-to-diff JSON file that includes serialized outputs. Good luck seeing what changed! And even if you figure that out, you’ll inevitably run into issues with environments, database credentials, and package versions.
Worse, perhaps, is the inability to share with stakeholders. 99% of people can’t open an .ipynb, so the the default way to share outputs from notebooks is sending screenshots and slides, which are severed from the underlying data, not interactive, and certainly not secure.
Notebooks have so much more potential!
Ok we’re a few hundred words into trash-talking notebooks, and why they aren’t keeping up in the modern data world, but it’s really a shame because notebooks actually rock! The notebook format is great for iterative, exploratory data work, but is only accessible to people who can figure out how to get it set up and fight through the issues above.
At Hex, we set out to fix all of this, and empower millions of people who want to do more with data, together. If you're curious about what a fully-collaborative, built-for-the-cloud, perfect-state notebook solution looks like, check out what we're up to or get started now.