


At Hex, we on the Data team, are your typical Data People™️. We’re all fairly Type A and carry traits emblematic of the analytically-minded: outcomes-driven, ambitious in goal-setting, and fastidiously organized. Our team hero is Marie Kondo. None of this is surprising.
Perhaps more surprising was the realization that in pursuit of Getting Stuff Done, we, the tidy-loving Data folk, had let our warehouse become a bloated and confusing mess! This is the story of how we renovated our data warehouse with blue-green deployment and how, in doing so, we created a warehome that works for us, our stakeholders, and even our LLM assistant, Magic.
How can you find anything in here?
Our data warehouse wasn’t always a mess. When our first dbt PR was merged in November 2021, Hex was about 24 people. We were small; and though we had data questions, we didn’t yet need a lot of sophisticated data architecture. We created one database, analytics, and four schemas within it:
analyticsfor production-quality models,analytics_datafor dbt seed files,analytics_snapshotsfor dbt snapshots, andanalytics_stgfor staging and intermediate models.
Everyone at the company could access all of these schemas, though they only really needed the models in analytics.analytics.
❗Yes, if you wanted to query our core models, you had to reference a database-schema pair called analytics.analytics. Admittedly, naming your database and core schema the same thing is confusing. But hey! We were only 24 people! We could trust a small group to remember — and easily identify if they didn’t. In fact, this structure was intended as a one-stop-shop! All “useful” models were centrally located, and that location had one (albeit redundant) name. Talk about efficiency!
The thing about successful start-ups, though, is that they tend to grow: both in employee count and business complexity. And while this growth was great for us, it started to put strain on the foundations of our lightweight warehouse. analytics.analytics, which had begun as an easily navigable centralized data mart, ballooned to housing ~120 models by August 2023. Worse, the analytics_stg schema had nearly 300 models in it — and new Hexans weren’t always sure which schemas mattered. While the Data team knew every nook and cranny of our warehouse, it was starting to feel overwhelming for stakeholders.
😵💫 We have dim_ and hex_ prefixes for a lot of similar tables (e.g., dim_orgs vs. hex_orgs). I know one is multi-tenant only and one is all customers but I don’t commit to memory which is which.
Rebuilding our data warehouse with a blue-green deployment approach
It was time for a change. But we couldn’t just raze the proverbial ground and rebuild! Folks at Hex required continuous access to data in order to make decisions, track progress to goals, and generally keep the lights on. We needed a strategy that allowed us to renovate iteratively, so that we could live amongst the construction. We needed blue-green deployment. Here's what we learned.
What is blue-green deployment?
Blue-green deployment is a strategy whereby a new version of some asset (an app, a website, even a dbt project!) can be iteratively developed in a separate environment, parallel to the current production version of that asset. This “parallel path” strategy allows for gradual development and testing, all without interrupting production for consumers. When your development version is finalized, you can seamlessly swap your work into to the production environment.
What we learned renovating our data warehouse while keeping "the lights on" for production
First: Make a plan and set goals
The enticing thing about blue-green deployment when you’re staring down a warehouse that looks and feels overgrown is that you can change anything — maybe even everything! I began with dreams of tidying up not only our warehouse organization, but also all the spaghetti ball knots in our DAG and lingering naming conventions discrepancies too.
Reader, if I had gone down that path, I would have been in a blue-green state until my skin withered and my bones turned to ash.
If you try to tackle everything, you’ll inevitably finish nothing. When setting out on your own blue-green adventure, start with the end in mind, and work your way backwards. Begin by setting an achievable, time-bound goal for your work — and stick to it.
We had two big problems to solve, so we set ourselves two goals for the work:
Next: Get to work
There are a few ways to go about blue-green deployment for your dbt project. For instance, if your data warehouse is Snowflake, you can do this with a few clever macros and Snowflake’s swap syntax. If you care about always maintaining a prod and working database and being able to swap them periodically, this is a great strategy!
But maybe you want a solution that is warehouse-agnostic and you don’t need to continually swap databases. In that case, all you need for your blue-green work is:
- your code management platform of choice (we use Github),
- your orchestrator of choice (we use dbt Cloud to orchestrate our jobs),
- your data warehouse (we use Snowflake), and
- your dbt project!
Step 1: Create a working database and grant permissions
To begin, you’re going to need a place to materialize your development work. Keep your current database as your prod version, and create a second database for your development work.
In our case, analytics was our prod database, and hex_dwh was created as our working database. Within hex_dwh, we also created the new schemas we wanted it to have.
create database hex_dwh;
create schema hex_dwh.prod_core;
create schema hex_dwh.prod_mod;
create schema hex_dwh.prod_pkg;
create schema hex_dwh.prod_pub;
create schema hex_dwh.prod_sources;You can also clone your prod database here to save compute if your changes aren’t architectural!
Once you’ve created your working database, update your permissions so that your team has access to it, but it’s not accessible for a broader audience.
Step 2: Create a working-main branch
If you’re choosing to do blue-green deployment, the work you have to undertake is probably quite hefty. You’ll want to break this work up to tackle it iteratively, but you won’t want to merge all of these PRs straight into your main branch.
To circumvent this, we set up a working-main branch off of main. This gave us a space to branch off of and merge back into in a way that wouldn’t impact production until we were ready to cut our changes over.
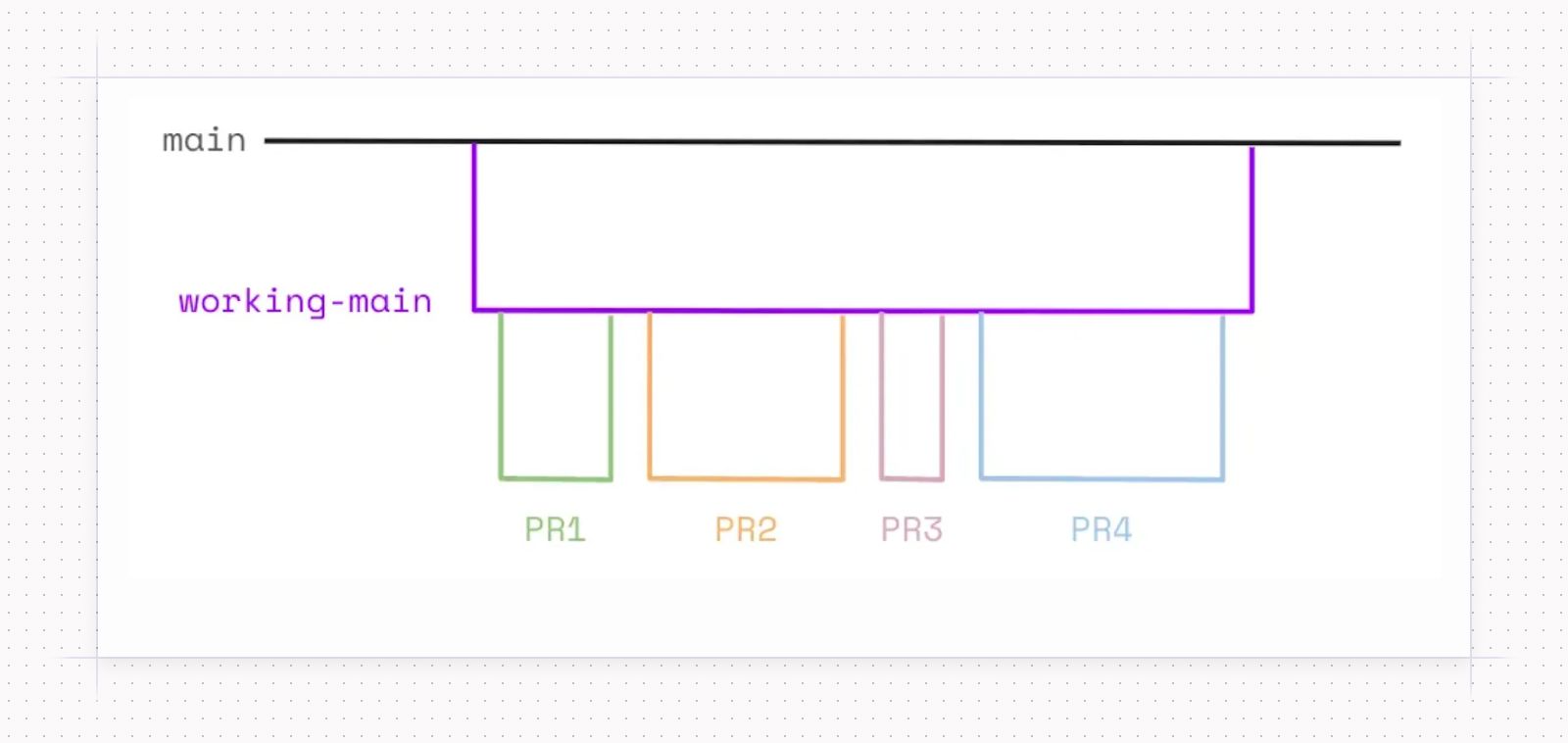
![While you’re working, you’ll create PRs as you normally would, but you’ll change where the merge goes! Our [working-main] was called [the-new-hotness-main] because it made us giggle, and humor is an important (and overlooked!) skill of analytics engineering.](https://cdn.sanity.io/images/e92memrj/production/b2a07f42b934488db9723d8e73f9a64fcc2f3954-1600x312.jpg)
Step 3: Set up orchestration specifically for your working-main branch
At Hex, we use dbt Cloud for our build jobs and CI checks. One of the great things about dbt Cloud is that you can easily configure multiple environments (each containing various jobs, like a daily build and a CI check) and you can run different environments on different git branches!
Now that we have a working-main branch and a working database configured, let’s set up a new dbt environment for our development work. This will let us keep our Production environment unchanged, so that our prod database (analytics) keeps running for stakeholders as we make our changes elsewhere. It will also ensure that we don’t run into any unnecessary merge conflicts!

Getting started with a new environment is pretty easy. We just give it a name, select our deployment type and version, and make sure we’re running on a custom branch. For your custom branch, you’ll select the working-main branch you created in the step above.
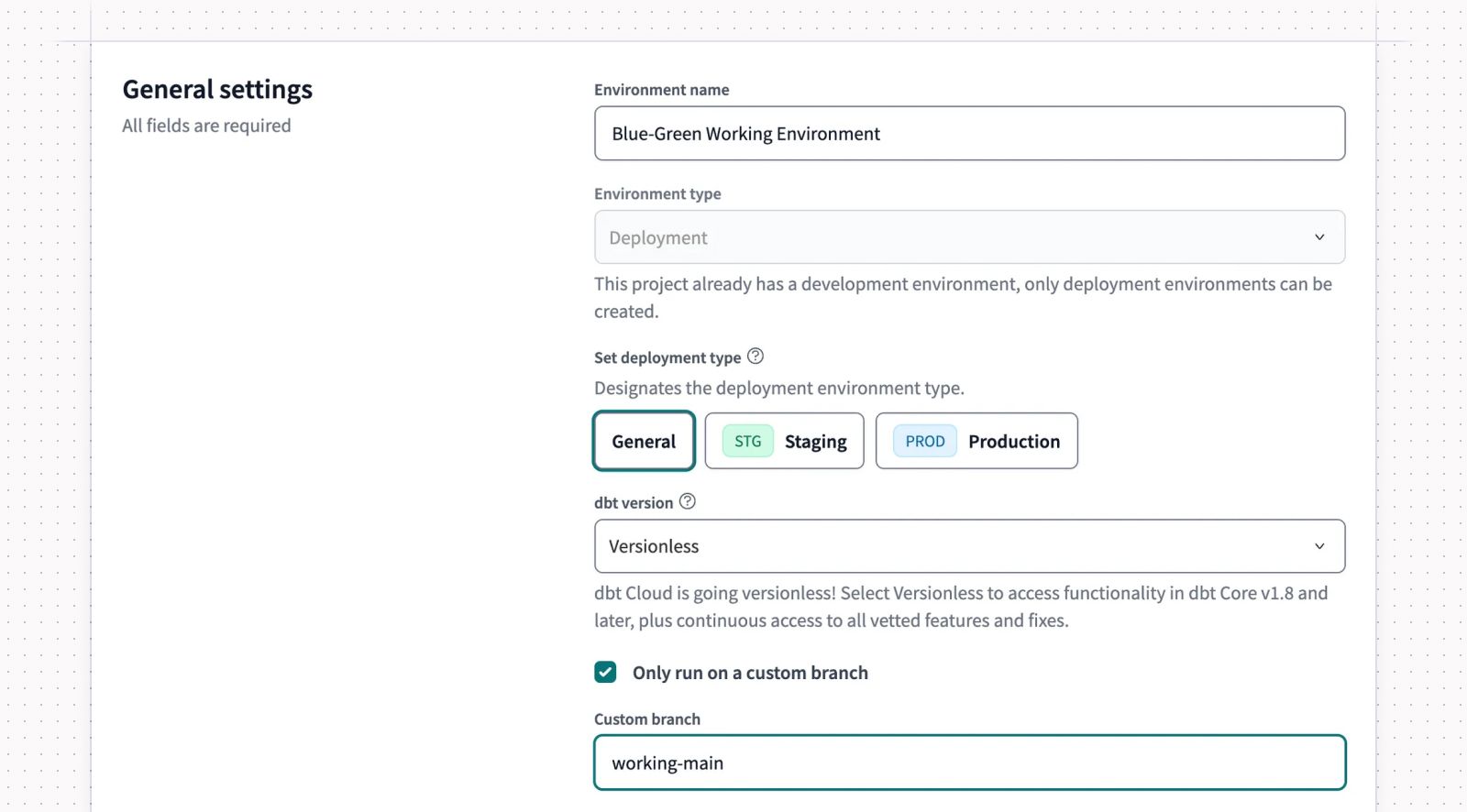
Then, you’ll configure the environment’s connection. Here, you’ll want to select the working database you configured in Step 1. Don’t forget to use the role that has permission to access your working database!
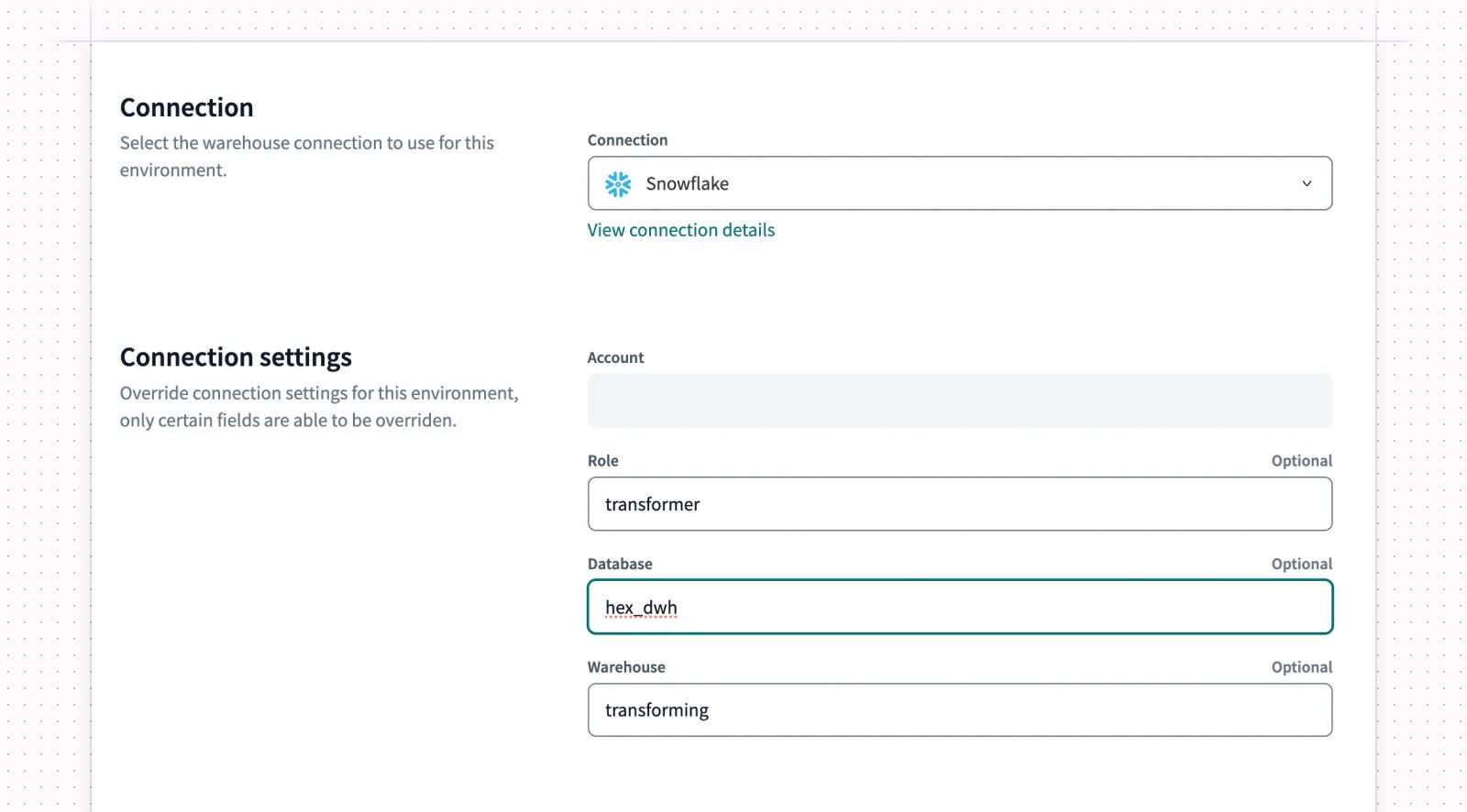
Once your new environment is set up, you’ll want to create at least two jobs within that environment:
- Merge Job: This can be on whatever cadence works best for your team, whether it’s hourly, daily, or manual. This job will build everything that is merged into your
working-mainbranch. - CI Job: This is important! You’ll want a separate CI job for PRs being merged into
working-main. You want to compare any PRs you create during this time to the status quo of your working environment, not production!
⚠️ Pro-tip for your custom-branch CI
CI jobs in dbt Cloud compare changes in your PR to the reality in a specific environment and defer to that environment for any unchanged files. In order for comparison and deferral to work for your first PR against working-main, you’ll need to first trigger a run of your new merge job so that CI has something to defer to!
(Optional) Step 4: Update your profiles.yml for local development
If you use dbt Core for dbt development, you’ll want to update your profiles.yml so that you can build and test your working changes locally. If you use dbt Cloud for everything, you can skip this step!
If you’re a Core user, you already have a profiles.yml file configured with at least one target. For blue-green deployment, you’ll want to add a new target for your working environment.
When I was building out our hex_dwh, I updated my profiles.yml with the text in bold to add my new target:
default:
target: dev
outputs:
dev:
type: snowflake
account: <<account_id>>.us-east-2.aws
user: afioritto
password: absolutelynotmyrealpassworditsasecret
authenticator: username_password_mfa
role: TRANSFORMER
database: ANALYTICS
warehouse: TRANSFORMING
schema: DEV_ALF
threads: 8
client_session_keep_alive: False
query_tag: "dbt_dev_alf"hotness:
type: snowflake
account:<<account_id>>.aws
user: afioritto
password: absolutelynotmyrealpassworditsasecret
authenticator: username_password_mfa
role: TRANSFORMER
database: HEX_DWH warehouse: TRANSFORMING
schema: DEV_ALF
threads: 8
client_session_keep_alive: False
query_tag: "dbt_dev_alf"Once you’ve added your new target, you can toggle between local development for your production data and development for your working environment with the --target tag.
dbt build -t hotness --select +cool_new_model+Step 5: Do the work!
Everything you need for your working environment is now set-up. You have a new database to direct new work, a working-main branch to store changes from your PR, and merge and CI jobs keyed on that custom branch to validate your work each step of the way. All that’s left to do is the work itself! 😅
For us, our work was defined by the two goals we set above:
- break up the big, bloated schemas
- implement a “least privileges” access strategy for the data warehouse
Break up big schemas
To accomplish this, we set up a new database in our development environment, called hex_dwh and planned a set of more specialized schemas to build within:
prod_corefor our core data models (i.e., anything prefixeddim_orfct_),prod_sourcesfor base models (models that maintain a 1:1 relationship with a given data source),prod_pkgfor all models derived from dbt packages, andprod_pubfor all models created for syncing to operational tools via reverse ETL, andprod_modor all “modifying” models in our dbt project (i.e., staging and intermediate models and seed files).
We also decided to move all snapshots into their own, completely separate database, called dbt_snapshots. (You can read more about why a separate database for snapshots is a good thing here.)
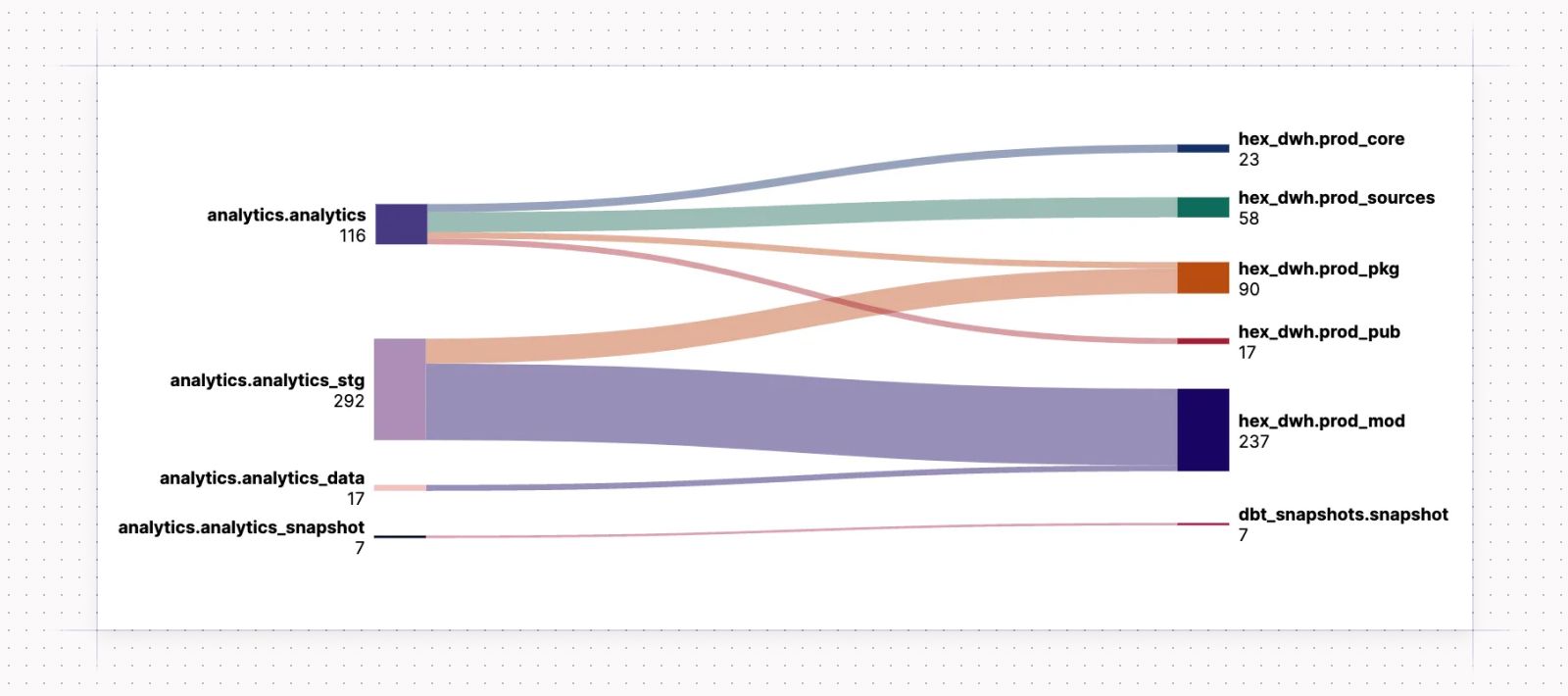
The goal was to create more, smaller schemas for faster and tidier data discovery. Though prod_mod would still contain the bulk of the models, it would no longer be a burden for stakeholders to bear, as you’ll see in the next section.
Don’t show what isn’t necessary
From the beginning, stakeholders had access to everything generated from our dbt project: not just “finalized” models, but every upstream model required to build them. As Hex grew, explaining the ins and outs of data modeling to a larger group of Hexans became harder to manage. Sometimes folks got tripped up, forgetting the subtle differences between stg_hex_users, hex_mt_eu_users, and dim_users.
This growing confusion prompted us to adopt a “least privileges” strategy for data warehouse access. Most Hexans don’t need access to every layer of our dbt DAG, so what if we just…removed that access?
To that end, we decided to build two connections to our data warehouse in Hex:
- A default connection,
Hex DWH, to be broadly accessible and contain only the most analytically useful schemas in the new database:hex_dwh.prod_coreandhex_dwh.prod_sources, and - A second connection,
Hex DWH Dev, to be used by the Data team for development and debugging, which would contain all the schemas inhex_dwh.
Remember to work iteratively
Of course, we didn’t tackle all of this work in one big PR! All together, we merged about 15 PRs into our working-main over the course of a two-week sprint. Each PR was validated by the CI job we set up in Step 3, and our custom merge job ran daily to keep hex_dwh fresh.
Step 6: Validate your changes + merge to main!
When your last PR is merged into your working-main branch, it’s time to perform any final validation that you need to feel good about the work you’ve done.
During our development process, we weren’t changing our dbt models themselves as much as we were giving them all new homes. A lot of our validation was making sure we had ended up with the same total number of models that we started with!
We also used this final validation period as an opportunity to preemptively clean up any merge conflicts we might find when merging to main. We had been pushing changes to working-main for about two weeks, but that didn’t stop development in production too! Over the course of those same two weeks, we pushed changes to main to fix bugs and respond to ASAP requests from stakeholders. So, before we could safely merge working-main into main, we had to account for any discrepancies that may have popped up while we were deep in the blue-green mines.
Undertaking a blue-green deployment strategy is a lot of work. But rest assured that that final merge of working-main into main will feel so satisfying, you’ll barely remember the grunt work you did to get there!

⚠️ Before you hit that merge button
Our end goal was not to move the contents of hex_dwh into analytics and analytics into hex_dwh in a traditional blue-green “swap.” Instead, we were sunsetting analytics and introducing the company to the new and improved database that was hex_dwh. If you are doing similar work, know that your downstream tools — your BI and data workspaces, your reverse ETL syncs, etc.—may be impacted!
If all of your Hex notebooks are built on queries referencing analytics.analytics.dim_users and one day analytics.analytics mysteriously is replaced by hex_dwh.prod_core, you’re going to have a lot of broken data assets and a lot of unhappy stakeholders. Be sure to plan ahead. Be loud in Slack. Make a migration plan. Write some how-to guides and FAQs for your stakeholders. Trust me, you’ll be glad you did.
The life-changing magic of tidying up
We’re a year into our new hex_dwh.analytics is officially retired and it’s safe to say that hex_dwh isn’t just a warehouse: it’s truly a warehome. Our stakeholders have exactly what they need — and only what they need — to self-serve their data questions. Those schemas are tidier than ever, so fewer people are getting lost and confused. And the cherry on top? Turns out more tightly-scoped warehouses make AI assistants like Magic better at their jobs too. But more on that in our next post. 😉
If this is is interesting, click below to get started, or to check out opportunities to join our team.