Blog
Hex's Partnership with Snowflake: Behind the Magic
Behind-the-scenes look at how Hex built features that integrated with Snowflake.



Hex has partnered over recent years with Snowflake to create a seamless and smooth workflow for data science and analytics professionals. In a recent talk at Snowflake Summit, Hex's CTO and co-founder, Caitlin, discussed the various features built in partnership with the Snowflake team and gave a behind-the-scenes look at how they were developed.
How Hex works
Traditional notebooks were a huge leap in the data science and analytics workflow, allowing for sequencing and ease iteration. However their compute architecture, while flexible, makes reproducing work difficult — we refer to this reproducibility issue internally as the state problem.
The state program can be summarized as this: Notebook cells can be run out of order, and they can also be run without rerunning dependent cells. And if you work frequently with notebooks, I'm sure you’ve had the experience of restarting the kernel and discovering that it is in fact completely broken because there was a bunch of hidden state.
As you're writing code in Hex, in the background we automatically parse that code and pull out dependencies between the cells. So if you're reusing variables in various different cells, we know that behind the scenes and under the hood Hex is building up a directed acyclic graph (DAG) of all of the cells in the notebook. This means that every time a cell is run all cells it depends upon are run in the same order every time removing any confusion about state.

It turns out having this DAG structure is really, really helpful for a bunch of the features we have built.
Hex Magic
The team at Hex is excited about the promise of AI and we have been working on a number of AI assist features we call Hex Magic. But being optimistic about the future still means that we must stay grounded in the problems that AI can help solve for our users.
A core problem we focus on is that it's really hard to get started in code-based tools, especially when you’re less familiar with the language or the data. In data analysis it is useful to start with a vague question and get some help from an AI to begin to understand how to find meaningful insights in the data. So we have put considerable work into prompt engineering, formatting, and intelligent scoping that can reliably generate some pretty complex queries based on our users’ natural language prompts.
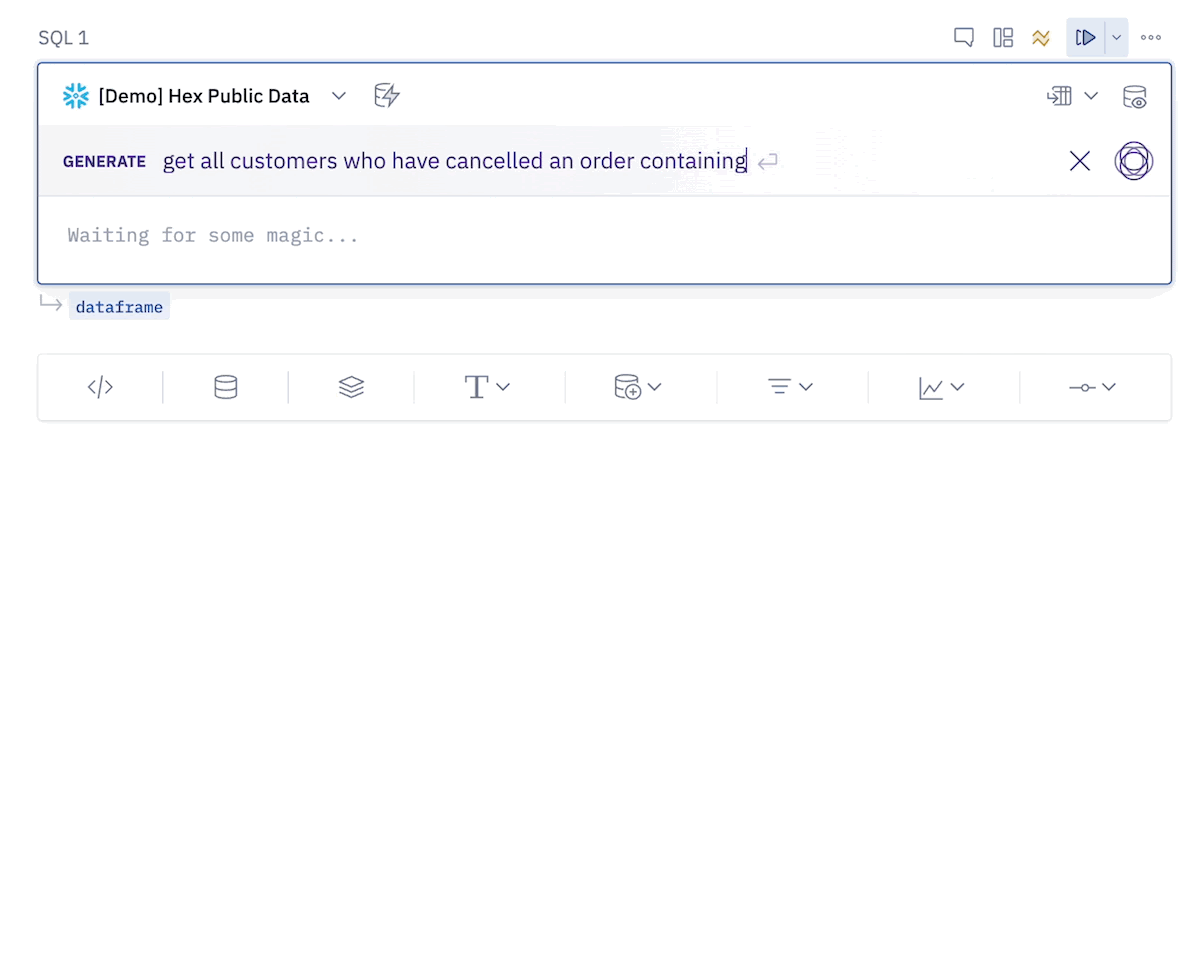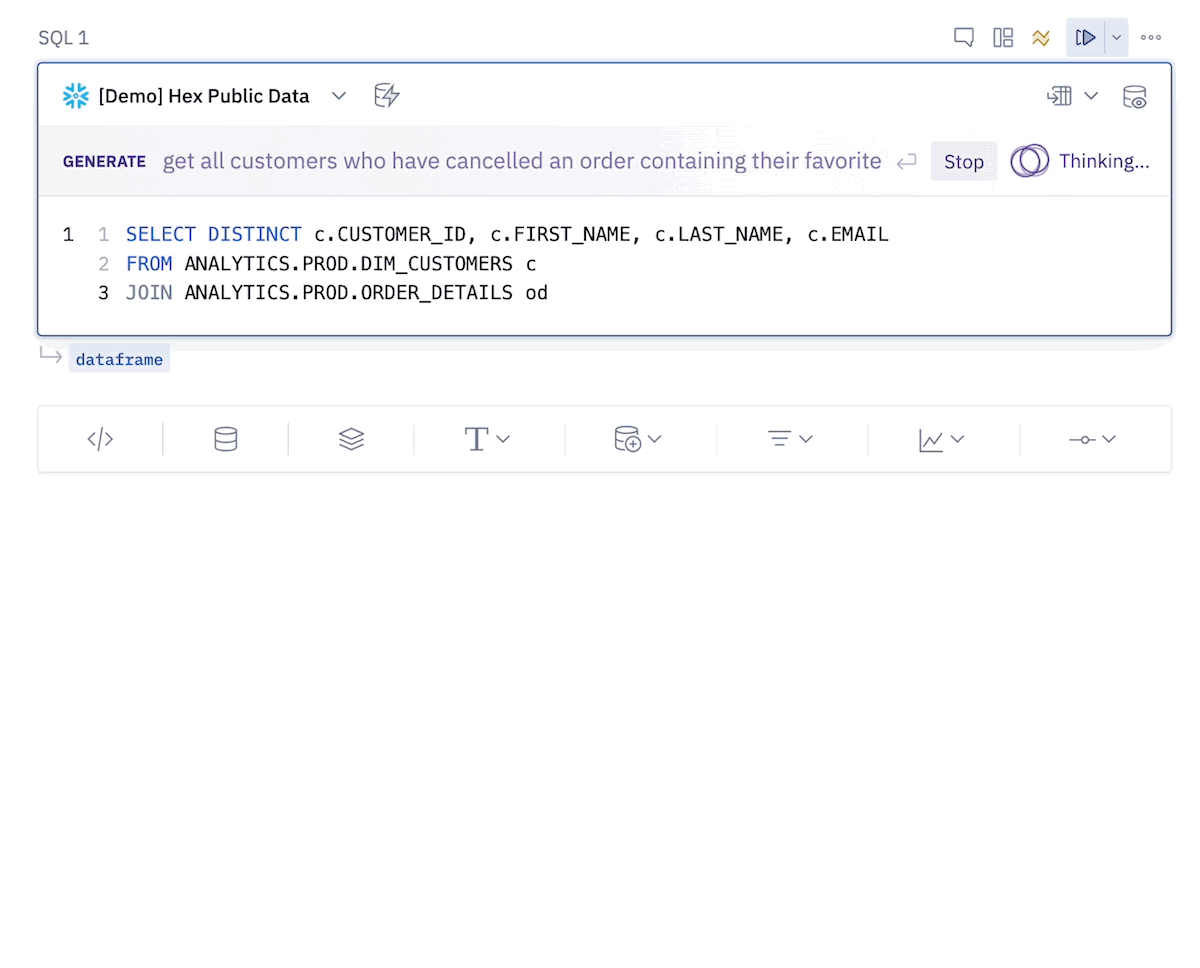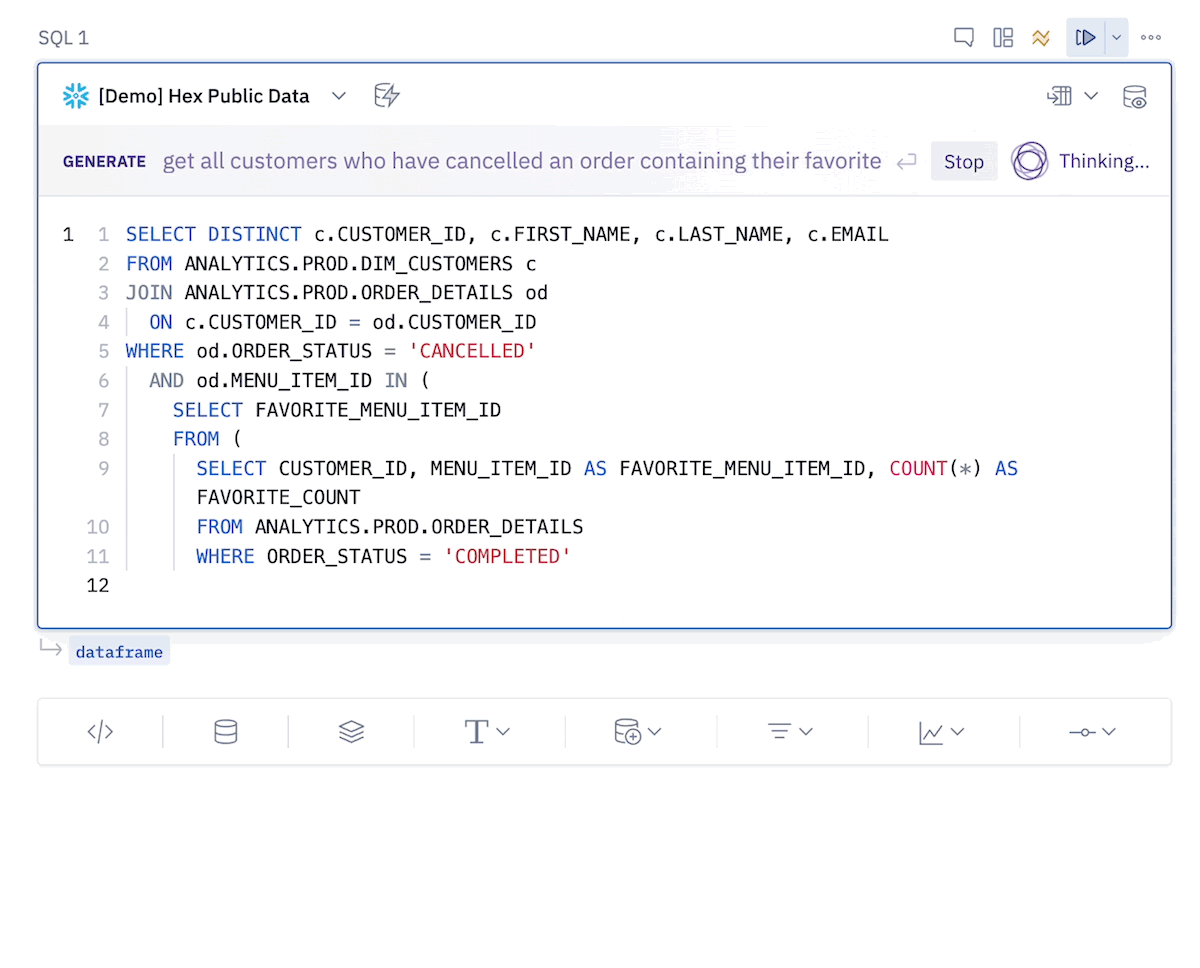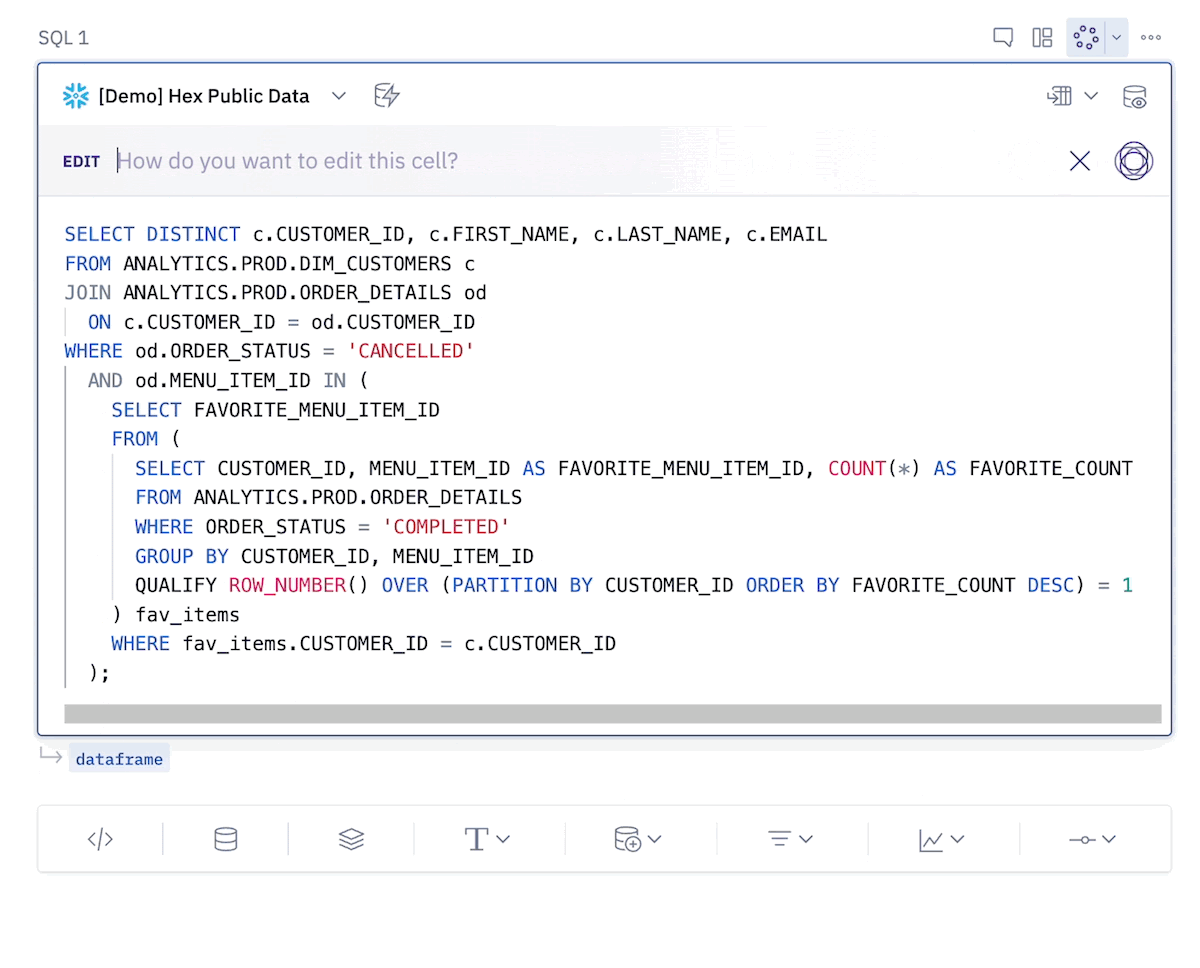
However, this does not work out of the box with a large language model.
The existing LLMs are great at writing syntactically correct SQL but they don’t know anything about your data. Small prompt contexts can’t handle full schemas, and large ones are less accurate in identifying relevant tables/columns.
So how do we give the LLM only the relevant schema information? We can use the DAG Hex is built on! The DAG helps us produce relevant context for the LLMs to parse to return accurate SQL code. So the key pieces to our prompt engineering are:
- Dialect - e.g. Snowflake, Postgres, etc
- Directly referenced schemas in the code
- Fuzzy or semantic search on referenced schemas
- Schemas referenced by upstream cells
- Semantic search on upstream cells with a VectorDB
This prompt construction fits into our larger Hex Magic architecture.
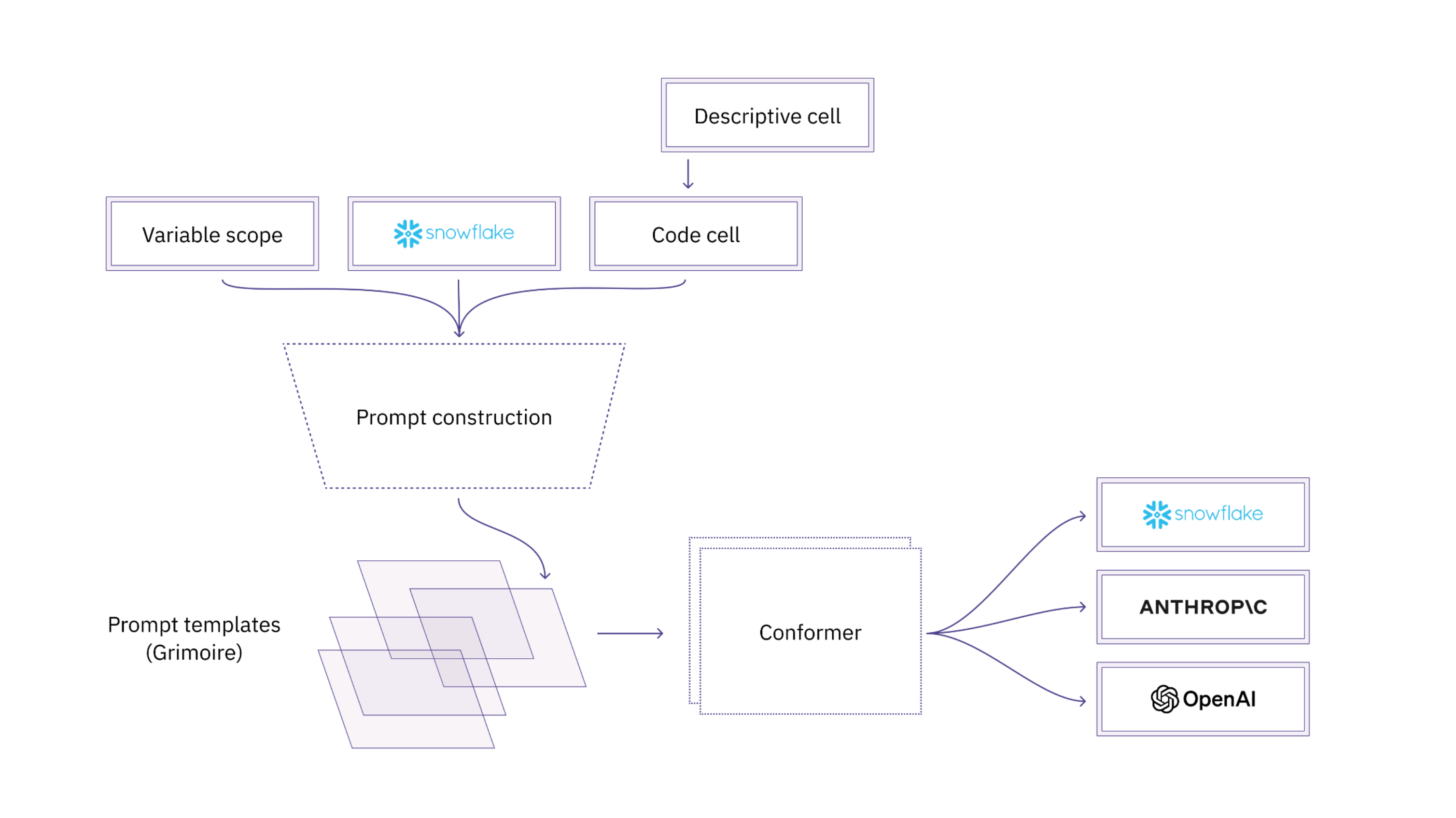
We also use prompt templates, such as Magic fix, for additional guidance on things like suggesting new code to fix errors.
Query Mode
People love notebooks because you can do a sequence of steps and iterate on the output. But in traditional notebooks this doesn’t scale because the size of the data you need to pull in and manipulate can crash the kernel.
So how do we enable a workflow that includes a sequence of steps and ease of iteration, but still take advantage of the scale of our cloud data warehouse?
Hex intelligently builds CTEs for you automatically to keep the full computation at the warehouse level while still making a preview of the data available, allowing you to run massive queries without having to pull all the data into the kernel.
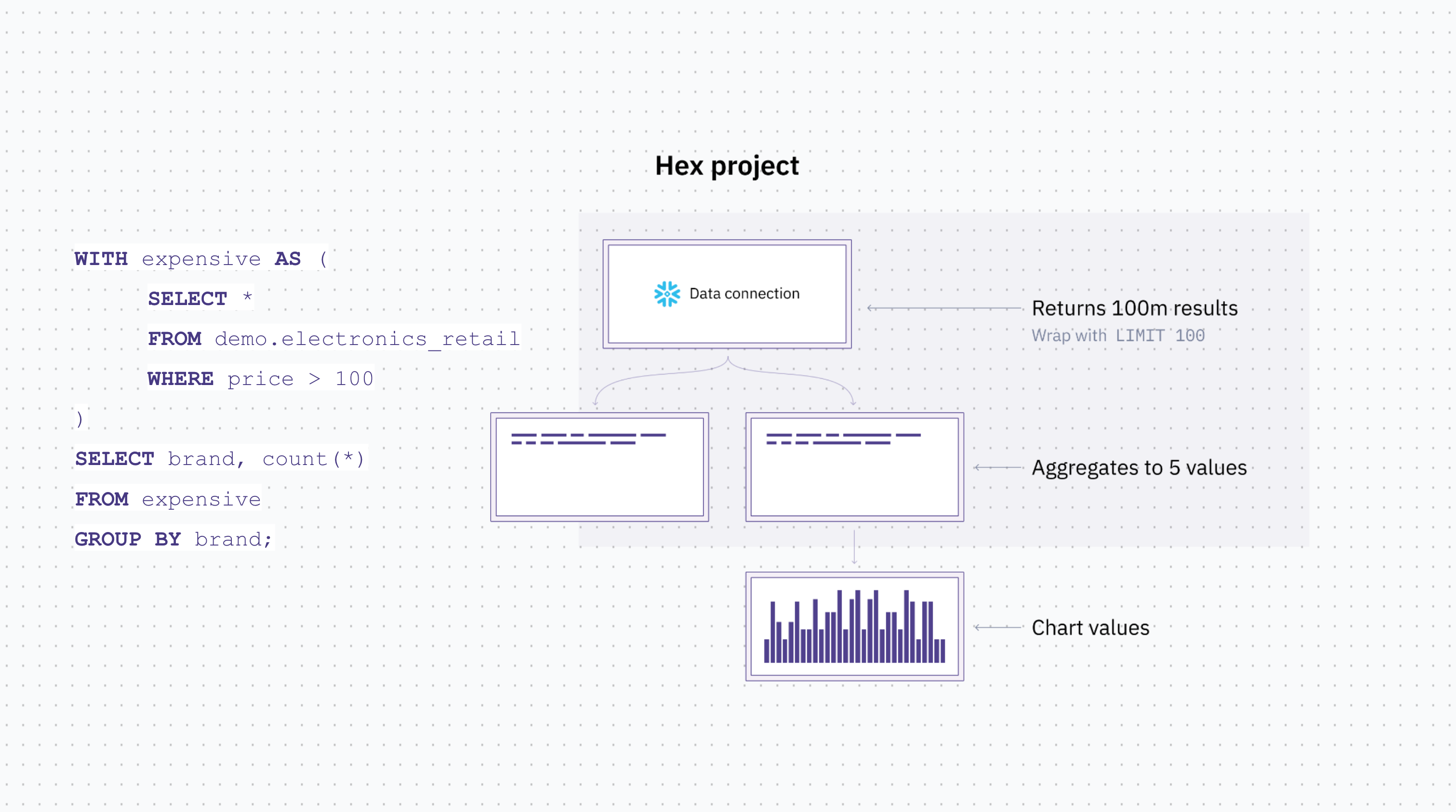
Hex takes a large query and wraps it in a limit 100, so that you're seeing a functional preview of the whole data set. And then for the second query, behind the scenes, we automatically construct the CTE for you.
So now, all of your SQL compute is running on the underlying data warehouse, but you can still see a preview of your results, you can build SQL queries on top of each other, and build from there. This is made possible by the DAG in Hex which understands the underlying dependencies between SQL cells.
Polyglot - SQL, Python, and Snowpark
Some things are really nice to do in SQL and some things are really nice to do in Python. For example, if you have ever run a linear regression you surely noticed that in Python it's two lines and in SQL it's hundreds of very challenging lines. So wouldn't it be great to use Python for what it's best at and SQL for what it's best at - together?
We built just that, the ability to move back and forth between these two languages, which we call a polyglot workflow. We use the pandas dataframe as a foundation data set so whenever you write a SQL query, it can turn it into a dataframe. And when using Python to create dataframes we took advantage of DuckDB, which allows you to natively write SQL on top of a dataframe object.
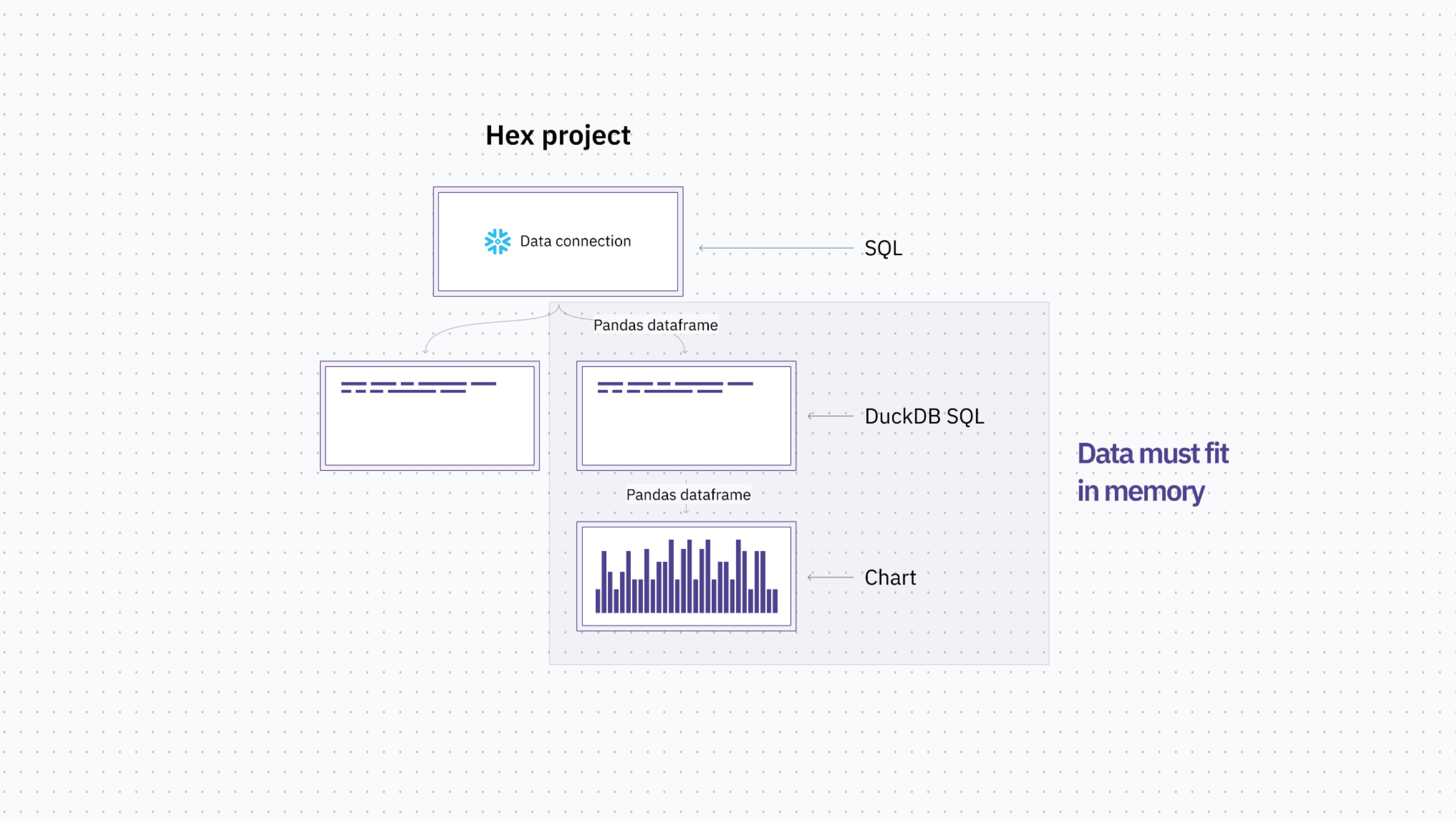
This worked great, and then we saw an opportunity to scale this polyglot workflow with Snowpark.
We've been working really closely with the Snowpark team to use Snowpark dataframes instead of pandas as the interchange format. Now in Hex, you can natively run a SQL query and we'll create a Snowpark dataframe from it. And you can treat that Snowpark dataframe as if it was a table, and you can write SQL against it. Or you can use any of Hex's built-in visualization cells to leverage the Snowpark dataframe as if it were a pandas dataframe in memory.
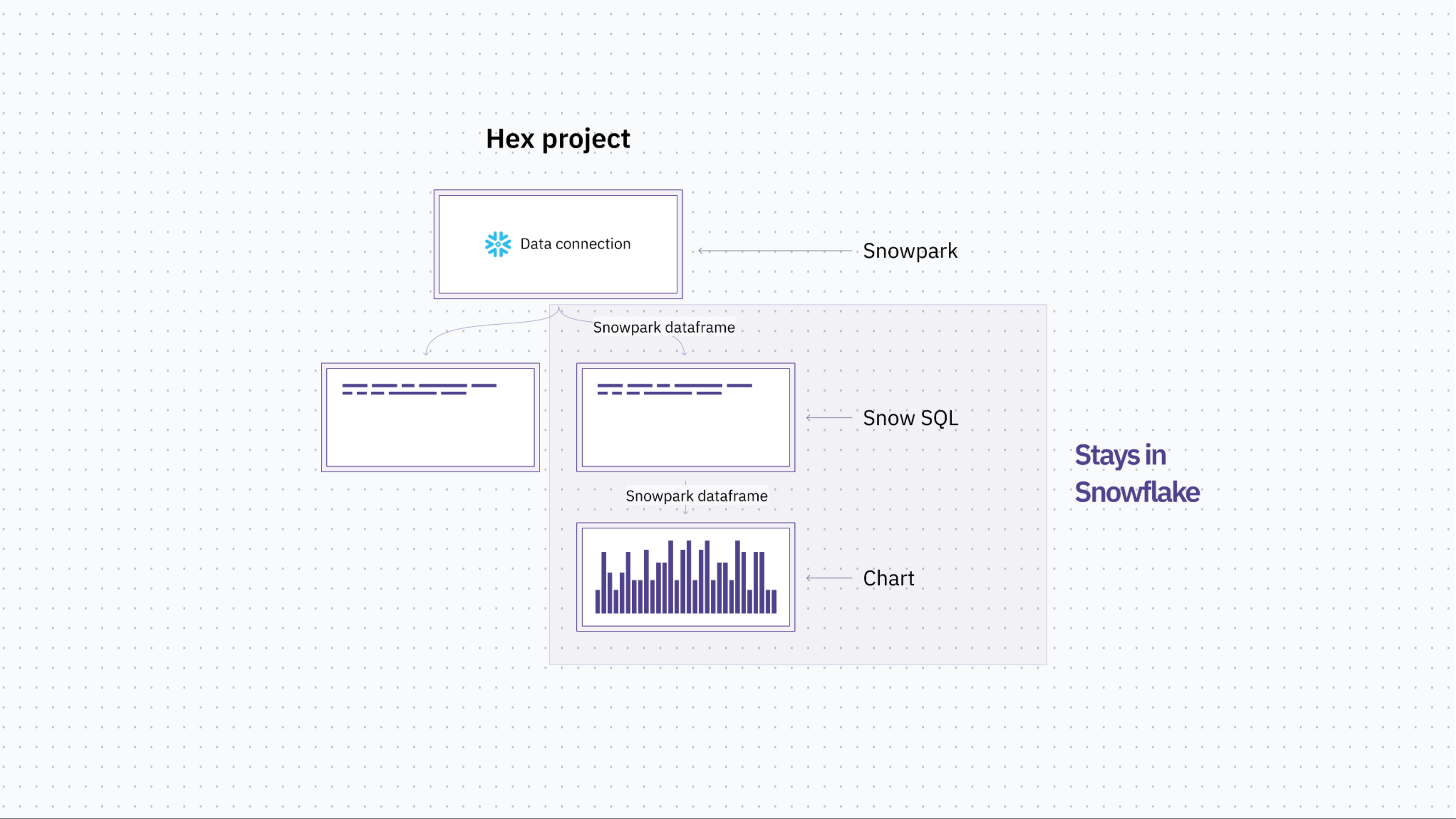
This ability to move between SQL and Snowpark requires two different approaches. To go from SQL to Snowpark we wrap the SQL in a session .sql, and voila, you get a Snowpark dataframe. To go the other way is a bit more complicated but we are able to do it thanks again to our DAG structure. We look for Snowpark dataframes referenced in SQL queries and automatically create a temp table using Snowpark's cache results under the hood. We then rewrite the query behind the scenes to reference that temp table and run the SQL completely transparently as if you were just running that SQL on top of that dataframe.
Hex on Snowpark Container Services
We take a security-first approach at Hex, so we've spent a lot of time on our infrastructure, minimizing the data that we need, making sure that it's all secure and well-governed. But at the end of the day, that's another surface area that you have to manage in terms of data governance. And especially when you've put a lot of work into making your investment in the data warehouse, this can be just a lot of effort. Knowing this was why we were early and excited to jump on the Snowpark Container Services train.
Snowpark Container Services (SPCS) allows you to run Hex completely within your data cloud. Hex has had Single tenant and Multi tenant deployments on AWS and now we have a new native stack deployment model for SPCS.
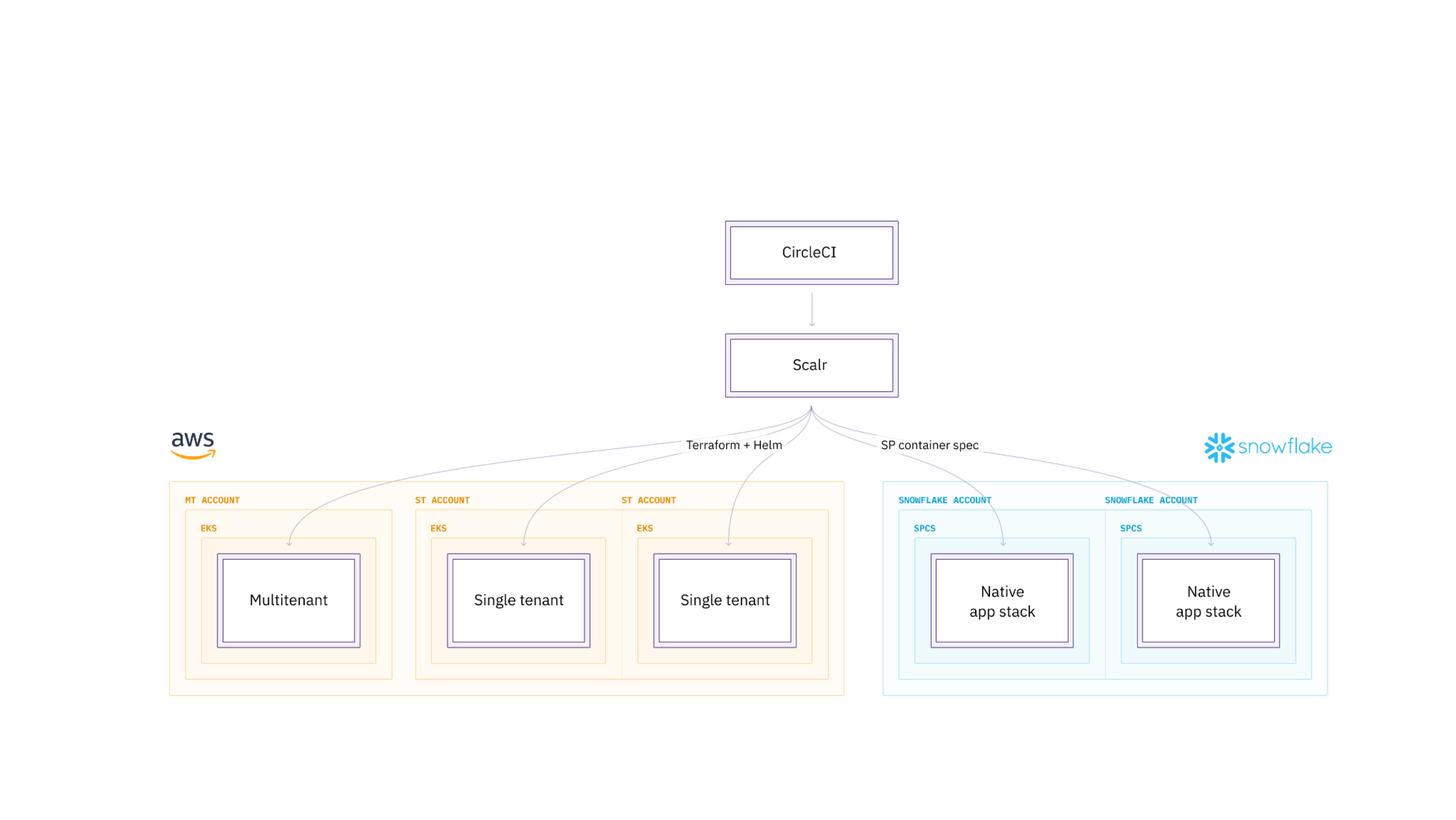
All of your data, compute, and user management can now always be within your Snowflake account.
Conclusion
Snowflake has been an amazing partner for us. We built features to lower the barrier to entry with code with AI-assisted queries. We allow users to work with more data by automatically combining and pushing queries to the data warehouse. We provide more seamless data science and analytics workflows by letting data teams interweave Python and SQL with Snowpark. And we allow orgs to access and run all of Hex inside Snowflake on Snowpark Container Services. We are excited about continuing to support data teams to ask and answer questions of their data on the data cloud!
If this is is interesting, click below to get started, or to check out opportunities to join our team.