
Welcome to a new era of data exploration with Hex's Snowpark integration—a paradigm shift that brings together the power of SQL queries, the scalability of Snowflake, and the simplicity of Hex's intuitive visual cells. This blog delves into how Hex's innovative approach eliminates the complexities of working with large datasets, allowing you to uncover insights without the burden of memory constraints. We’ll explore the current burdens of working with large datasets, how Hex brings easy accessibility to Snowpark with SQL cells, and finally visualization powered by our Snowflake warehouse.
The Library of Your Company’s Data
A data warehouse can be thought of as your company’s data library. Ideally, most of your tables (books) are well written and have proper structure to them. Today, we’ll focus on Snowflake as the de facto data warehouse. Traditionally speaking, you use SQL to access your data most likely in Snowsight. That said, getting insights from this data becomes increasingly complex and you most likely rely on additional tooling:
- BI tools are great for visualizations
- SQL runners are great for one off queries or CTEs
- Traditional notebooks are great for data science and exploration but typically require more expertise and do not have traditional SQL support
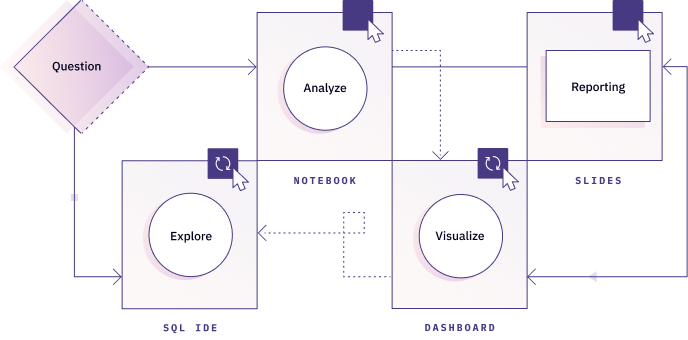
Hex seamlessly integrates these three workflows into a unified analytics platform, eliminating tooling fragmentation. From initial data exploration to the creation of polished reports, a collaborative project in Hex allows real-time updates, accelerating insights and enhancing workflow efficiency.
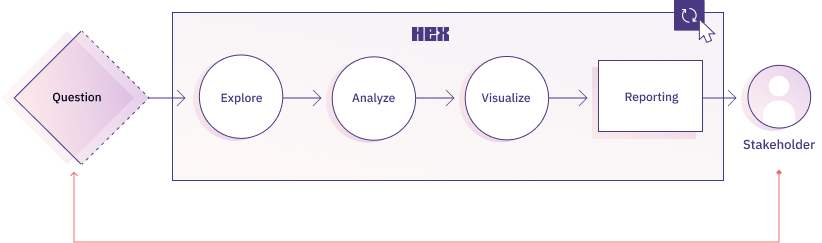
But that’s not the main topic for this blog - the real question is how can I maintain this workflow while working with large datasets. Consider scenarios where queries are not performant or, worse, memory constraints plague your tool of choice (including Hex).
Working with Large Data
Let’s first define what big data means in the context of this blog (we’ll save the debate for what constitutes big data for another time).
Big Data: Any amount of data that can not be efficiently and effectively managed in your environment.
For additional context, a single query of a couple million rows will typically plague your project with memory issues.
Traditionally, analytics engines like Spark were the go-to answer for processing big data. Data engineering, machine learning, and general data exploration would require you to move your data from your existing warehouse (library) to a new one. Of course, this comes at a cost for not only data transfer but also the time spent learning and managing a new system. Typically, PySpark would be the tool of choice for querying and working with big data. For SQL users, this meant a steep learning curve as they now enter the world of Python. Even if you are familiar with Pandas in Python, PySpark is not something you can pick up and be comfortable with in a week's time.
Spark - ELI5 (ExplainLikeImFive)
Let’s first explain how Spark works as Snowpark mimics its behavior and replaces the need for moving to Spark. Sticking with our library analogy, say you make a traditional SQL query against your warehouse. This is essentially getting up from your desk, grabbing a book (table) in your library and bringing it back to your desk. You have brought this data back locally and is now living in your local memory.
With Spark, you instead leverage a very knowledgeable librarian. She approaches you at your desk and you ask her questions about a book. She tells you what it's about, a summary, and other useful information. You now have gotten a snippet or sample of the book rather than bringing the entire book into memory. At any time you, the user, can go and grab the book and bring it into memory if needed.
This is the fundamental advantage to leveraging and working with big data. PySpark waits until you specifically ask for a piece of data before bringing it to your desk (local memory), much like a librarian. This is called lazy evaluation if you would like to learn more.
Ok great, so now you can work with large data. But, PySpark does not support visualizations - remember you just have snippets of the data so you’ll need a tool that can understand how to handle this. Also, working with SQL in PySpark is not a pleasant experience and requires an understanding of setup and configuration. As someone who has done this, you end up with the desire to just push through and learn PySpark rather than trying to write SQL.
Enter Snowpark in Hex and the New-age Librarian
So, what is Snowpark then? Snowpark is Snowflake’s answer to PySpark. It follows the same syntax as PySpark as well as the lazy evaluation paradigm for working with big data. The core difference is that it leverages Snowflake’s compute and processes queries in a parallel fashion using their SQL query engine. PySpark, in contrast, uses a Spark cluster for its parallel execution and computation.
However, you still can’t visualize your data, and using SQL with Snowpark is just as cumbersome as with PySpark. That’s where Hex comes in!
Let’s first see how easy it is to leverage Snowpark - we’ll use a SQL cell to start:
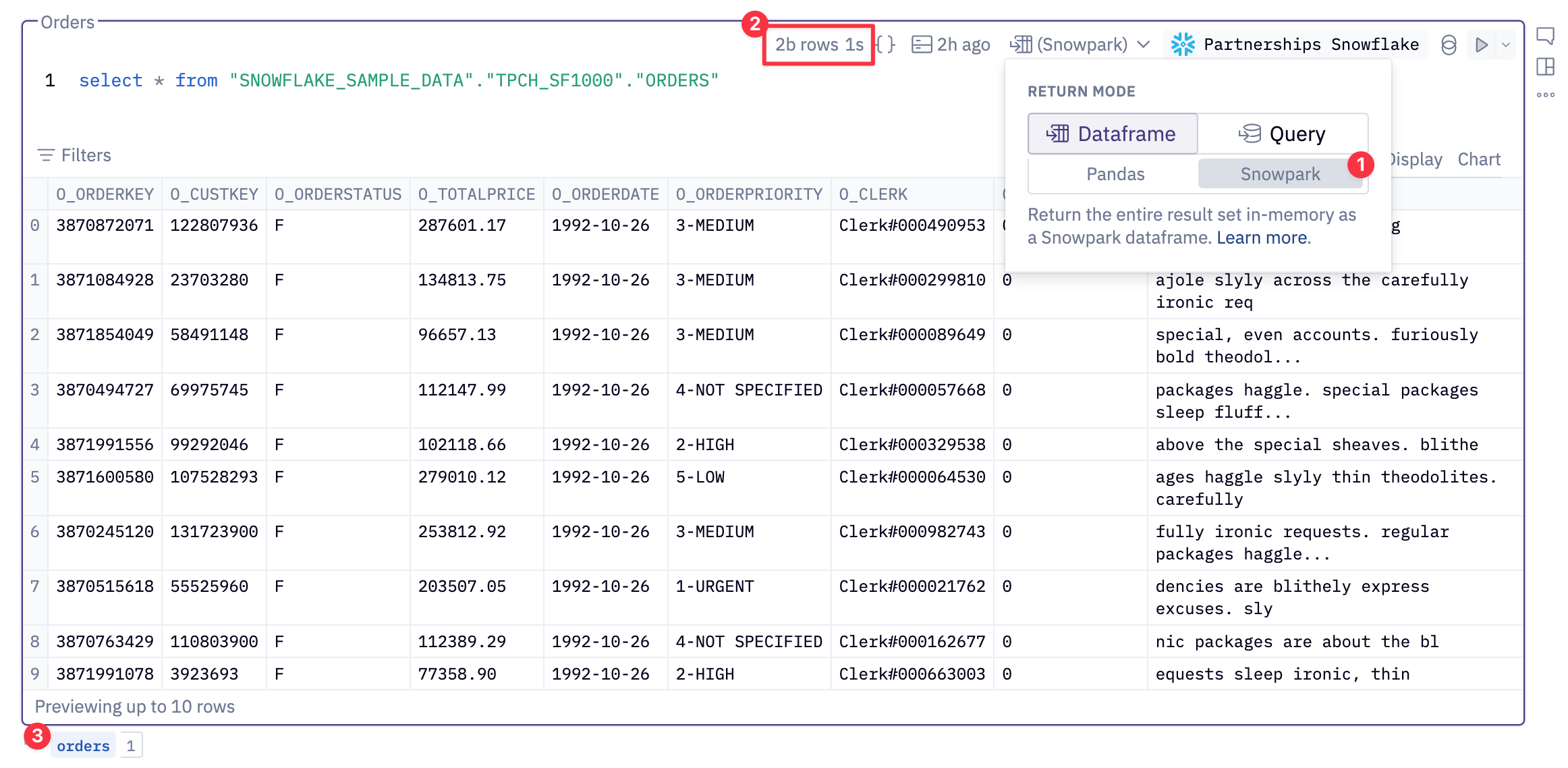
- I’ll ask for the Snowpark return mode.
- Notice how we get back our preview but our total row count is 2B rows that took 1 second!
When we make this query we get back a Snowpark dataframe - you don’t need to know what exactly this is but it is essentially a reference to the query you made. Snowflake does not process the entire query, it only processes enough data to give you a preview. And the best part is, Hex manages all that for you - you just need to write SQL like you regularly would. - We will call the Snowpark dataframe
orders. This is essentially just a variable.
Great, now let’s continue our analysis:
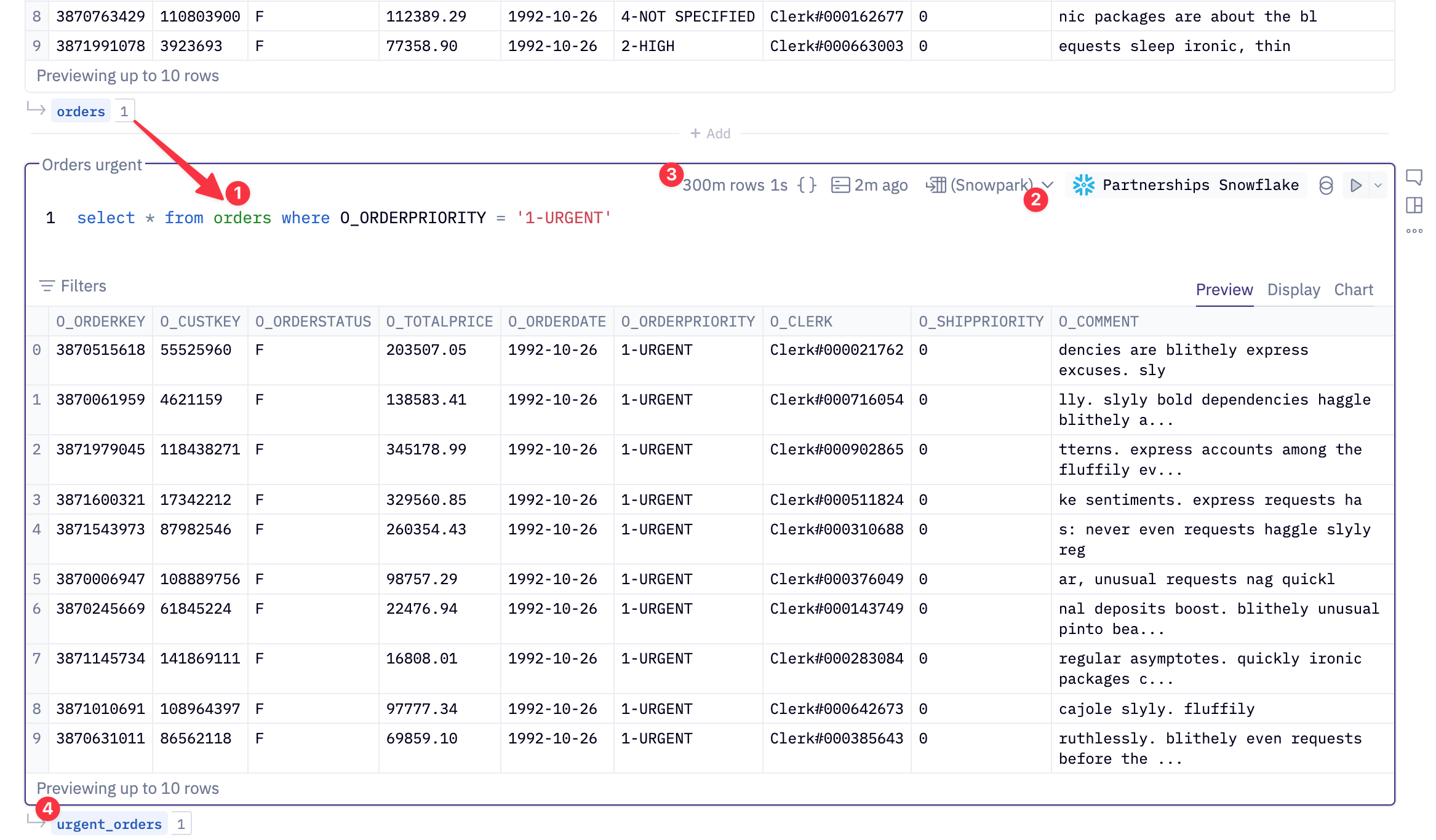
- Notice how we call the Snowpark dataframe that was returned in cell one - Hex offers you this chaining ability and correctly passes queries to Snowflake so you can just focus on your work. You can think of this as working with CTEs.
- We will make sure we are requesting a Snowpark return mode again.
- We get back 300m rows extremely quickly, ~1s. But remember, at this point Hex has constructed queries on our behalf to Snowflake so that we only operate on a limited number of rows. We then get back a preview of 10 rows so we can see if our filtering has done what we expected.
- We will call this Snowpark dataframe
urgent_orders.
Perfect, now I want to make an aggregated visual of the 300m rows:
No problem, just throw the Snowpark dataframe into a Hex chart and Hex will handle the rest!
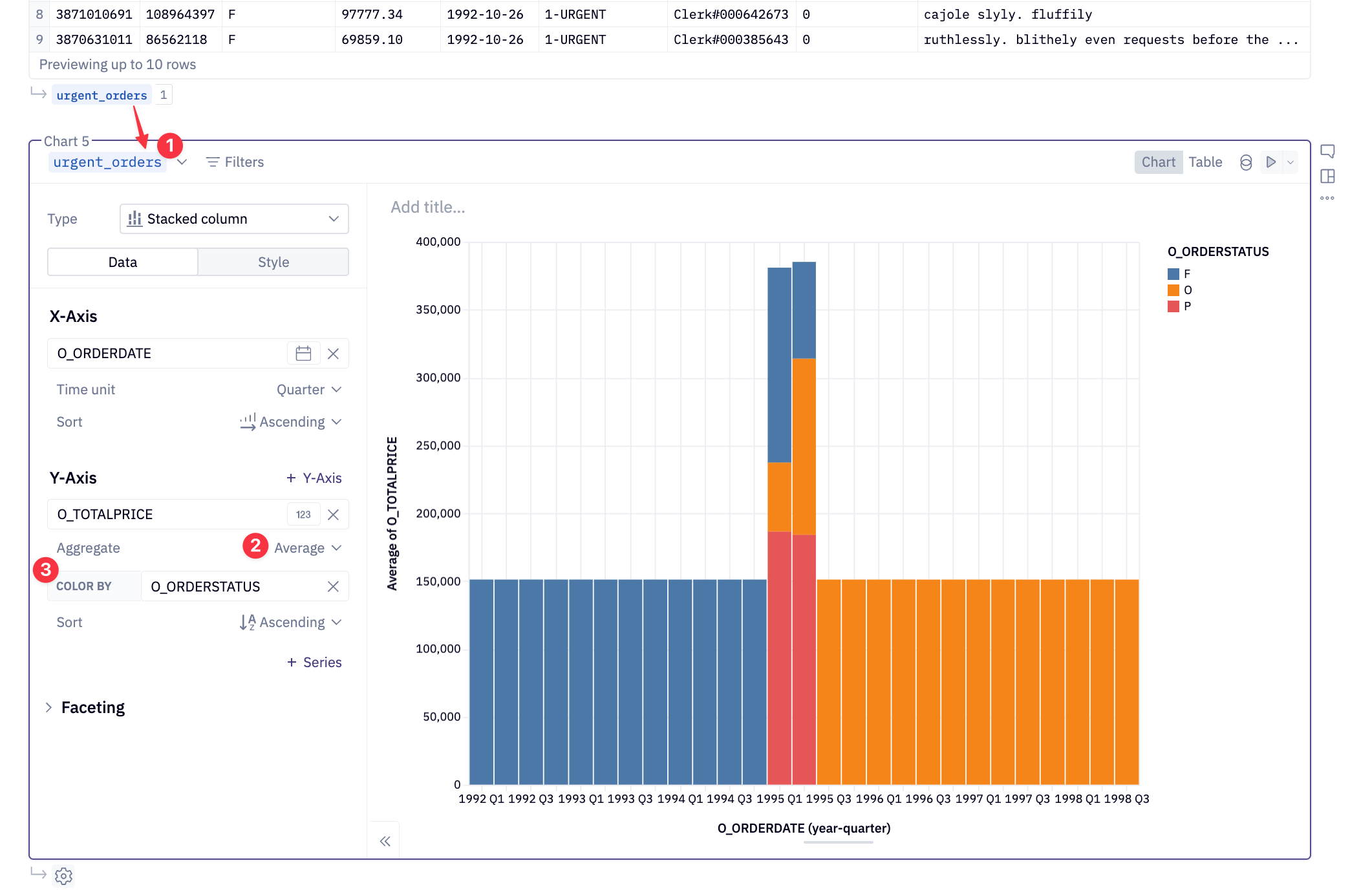
- Pass the
urgent_ordersSnowpark dataframe into the Hex chart - Calculate the average of
O_TOTALPRICE - Color By (Group By)
O_ORDER_STATUS
Hex realizes you are working with a Snowpark dataframe and will only bring back the results of the aggregation for the visualization! At this point, Hex leverages the reference to urgent_orders which references orders. This ensures that the query is operating on all the rows and not just the previews when calculating the aggregation.
The best part, all of the heavy computing is done by a Snowflake warehouse and Hex only brings back the result set of data for the visualization. For reference the above query used an X-Large warehouse and took about 4 seconds to complete. With caching after the initial query, this naturally improves.
The simple analysis above allowed us to work with just samples of data until we needed to operate on the entire Snowpark dataframe (our chart which Hex handled for us). Since the compute is powered by our Snowflake warehouse, we can quickly scale our warehouse for our big data needs.
Conclusion
In this modern era of data exploration, to get the most return out of our data infrastructure we need tooling that does not limit us when it comes to making the decisions that move the business forward. This tooling should not require an immense learning curve and should be as flexible as we need it to be. Hex’s Snowpark integration provides users a way to work with big data while getting the benefits of native visuals, SQL cells with Magic, and one-click Snowpark access, thus eliminating memory constraints!