
What's a CTE anyway?
First, a bit of background: CTE stands for “Common Table Expression.” It’s the feature in SQL that lets you create a temporary, named result set that you can reference within the same query, usually used for creating conveniently organized intermediate data sets. In the below query, customer_orders and joined are CTEs.
with customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1),
joined as (
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id))
select * from joinedCTEs were introduced into the SQL standard in 2005, but SQL writers avoided them for a long time since they were often slower than their counterpart, the good old subquery. These days, most data warehouses are pretty good at figuring out how to run these queries efficiently, making them as performant as subqueries.
In general, CTEs let analysts write queries that are more modular — breaking up complex logic into readable chunks. You’d be hard pressed to find someone using the modern data stack who isn’t pro-CTEs (myself included!), thanks to their reusability, readability, recursion, and referenceability.
The catch with CTEs
CTEs can only be referenced in the same query where you created the CTE. On the surface this isn’t such a huge problem, especially if you’re writing a smaller query with only 1 or 2 CTEs. But where CTEs start to fall apart is when you need to debug them.
Let’s say you’ve just written a 200-line query with several CTEs, with the final query aggregating the values for a report. The query works, but the aggregated results look… off. You find yourself trying to figure out: “Did something go wrong in an earlier CTE? Which one? I better check the results of each part of my SQL.”
To debug, you’ll have to comment out chunks of your SQL CTE-by-CTE – I hope you know the keyboard shortcut to comment code (it’s cmd + / by the way). Along the way, you’ll have to make sure you didn’t introduce syntax errors like extra commas, and most frustratingly, while you’re debugging that earlier CTE in a query, you can’t keep the context of the aggregated result that first let you know something was wrong on the screen. When it’s time to figure out whether your change fixed things, you’ll have to uncomment all that code. Repeat x3 if that wasn’t actually the cause of the issue.
So if the catch with CTEs is that they can only be referenced in the same query where you created the CTE, what if you instead created the result set so that it could be referenced in any query? You could use a view to achieve this, but you’d have to futz with create and drop statements (and have the right database permissions to do so), and would likely clutter your data warehouse with objects where no one knows who made them, why, when, and whether they’re still being used or should have been dropped long ago.
So if CTEs are out, and views are out, what’s left?
A better way to explore and debug queries: Introducing Chained SQL
What if instead, you could break up long CTE-based queries into separate chunks that could reference each other? What if they magically re-ran when you updated an upstream chunk? You wouldn’t have to comment code in and out, and could easily tell how changes to one part affects the others.
Well, this is exactly what we built ⛓️ Chained SQL ⛓️ to do!
Each SQL cell in Hex creates a named result (a “dataframe” if we’re being technical). Now, if you use the name of that dataframe in another SQL cell using the same data connection, you can query it as though it were an object in your warehouse. It Just Works™.
Working with large datasets? Chained SQL is built to work seamlessly with Query Mode, allowing you to work with large data without pulling each intermediate result into memory.
Wait, it’s all CTEs?
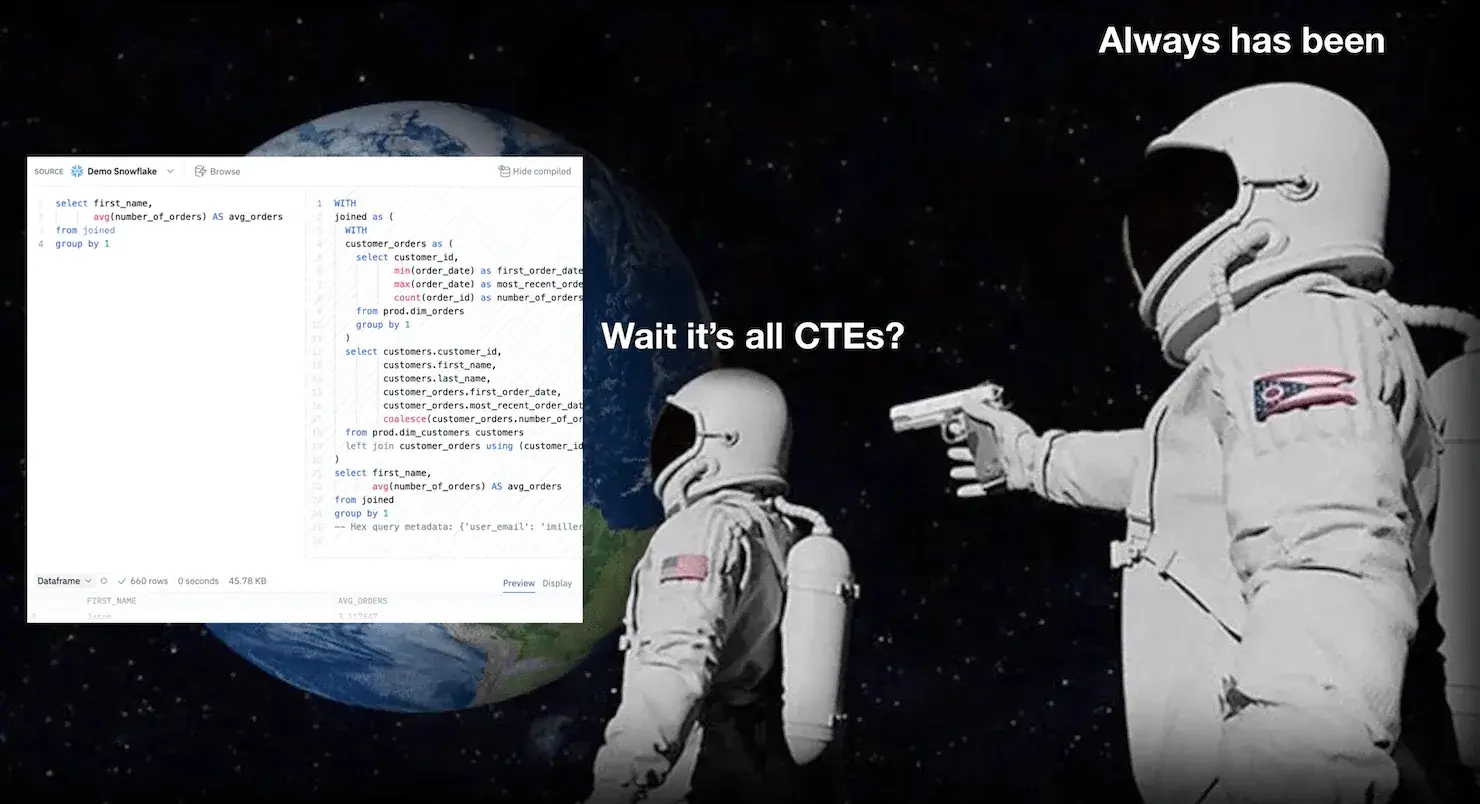
Here’s the big reveal: when you use Chained SQL, behind the scenes Hex is actually turning that reference to the upstream result into a CTE for you. The special sauce of your favorite warehouses (caching) will make sure these queries are run performantly.
On the surface, this is one of those features that feels so simple to use, that it’s tempting to think it was easy to build. But like most things that feel simple, it was actually pretty challenging to build. Often, software teams resort to using special characters like curly braces or dollar signs to identify when your reference to a table actually means “this other query I’ve already written”, but we wanted this to feel as seamless as possible in Hex. Behind the scenes, Hex is parsing your query to identify:
- When you’re selecting from a table (or a table-like object, like a view or CTE), and
- When the name of that table matches a previously named result
Then, Hex draws a dependency between those two cells (as you’re typing), and upon execution, seamlessly inserts the upstream query as a CTE.
ℹ️ For those who have been using Hex for a while, you might be familiar with Dataframe SQL. Dataframe SQL unlocks many of the same workflow benefits, however, it does require you to switch SQL dialects to the DuckDB syntax.
You can learn more about when to use Dataframe SQL vs. Chained SQL in the docs.
Chained SQL: CTEs, but better
While the title of this article may be “stop using so many CTEs”, what we really mean is “let Hex write your CTEs for you instead”. CTEs are great, but can be a pain to debug and make it difficult to understand the flow of data through a query. By letting Hex write your CTEs for you with Chained SQL, you’ll write queries that are easier to debug and inspect the results of, and most importantly, Just Work™.
If you're already a Hex user, chained SQL is available for all plans. Check out the docs and have at it. If you’re not on Hex yet, get started with a free trial.
We can’t wait to hear what you think of chained SQL! Send us your feedback at [email protected].