Blog
A pragmatic approach to live collaboration
or: How I Learned to Stop Worrying and Love the Atomic Operation

At Hex, we're all about making data workflows more collaborative. Our product allows users to connect to data, build analyses with Python and SQL, and turn them into interactive apps anyone can use.
The backing "Logic View" of a Hex project is powered by a notebook-style interface, similar in spirit to products like Mathematica or Jupyter. From early on, we wanted to support live multi-user editing in this Logic View so users can review or assist each other with their work.
Our team evaluated several options, and wound up pursuing a pragmatic approach which we were able to implement for our entire application in less than six weeks. We are excited to share some details for others who might be thinking through similar decisions.
State of the Art
There are two dominant approaches to multi-user collaboration today: Operational Transforms and Conflict-free Replicated Data Types. Both are powerful, although they come with trade-offs that make implementation challenging, particularly for smaller teams like ours. There is also a lesser-known hybrid approach — originally pioneered by Figma — geared towards ease of implementation.
Operational Transforms
Operational Transforms (OT) has been around for years. This technology is famously used to back Google Docs, and there are a number of reference implementations available on the web.
The basic idea of OT is to decompose all state mutations to specific operations.
As an example, let's say we want two editors to simultaneously edit the string ello. Editor 1 sends an operation that inserts ! at position 4 (or [!, 4] for short) and Editor 2 sends another operation that inserts H at position 0 (or [H, 0]).
If received in this order, a client can process these operations as they are and get the desired text Hello!. However, if a client were to receive [H, 0] first and [!, 4] second, the resulting string would be the incorrect Hell!o. OT implementations need to account for this, and implement a transformation to correct or "transform" the second operation to [!, 5] in order to preserve the user's intent and get Hello!.
In order to properly broker operations between clients, OT requires a centralized server, which may not be acceptable for all use cases.
OT offers a lot of control to the developer over how user actions are de-conflicted, making it easy to preserve user intent and context.
The "transform" part, however, can be quite tricky and error-prone since an implementor needs to account for each pair of operations. The number of possible combinations grows quadratically with the number of operations, meaning even with extensive testing it's possible to miss an edge case. This combinatorial complexity means an application gets harder and harder to reason about over time. 1
Conflict-free Replicated Data Types
Conflict-free Replicated Data Types (CRDTs) are a newer alternative that sidesteps much of the complexity that burdens OT.
The basic idea of CRDT is to use data structures that are inherently (you guessed it) conflict-free.
There are several different CRDTs, each with their own implementation details. An example CRDT is a Grow Only Set, which can only have elements added to it, but never removed. Conflicts are avoided since it is impossible to add/remove an item at the same time.
A multiplayer application can compose different types of CRDTs to create more complex structures for modeling its state.
CRDTs avoid the combinatorial complexity that comes along with OT, and also enable direct client-to-client communication, removing the need for a central server. Despite these advantages, they still have major trade-offs.
While CRDTs are correct from a mathematical standpoint, they might not have the correct semantics for a specific application. For example, the result of a state mutation is always consistent, but it may not be exactly what was expected since it's possible to lose user intent. 2
CRDTs also trade off the complexity of resolving conflicts for a more challenging initial implementation, due to their reliance on algorithms like vector clocks. They also incur a fair amount of storage overhead — while there is progress being made, avoiding this problem requires foresight and cleverness. And since CRDTs are newer, there are fewer reference implementations. 3
Figma's Hybrid Approach
While at first we considered OT and CRDTs as our two main options, we were intrigued by the pragmatic approach taken by Figma. They borrowed some ideas from CRDTs, like a last-writer-wins data register. Instead of using vector clocks to provide an ordering guarantee, however, they used a central authority, similar to OT.
By using the best parts of both OT and CRDTs, Figma avoided challenges with de-conflicting operations and difficulty of implementation. The main trade-off is that certain functionality, such as multi-user editable text strings, is not easily supported.
Figma's hybrid technique resonated with us as being both practical and elegant, although it was surprising that we couldn't find examples of others pursuing a similar approach. 4
Choosing a Path
As we assessed our options, we weighed a few key factors:
Taking it step by step
It was important to us that our solution was shippable incrementally and completable within a reasonable time frame. Any solution that required rewriting significant parts of our code base all at once, or a "big bang" cutover, would have not been acceptable.
Our current stack
Some existing multiplayer frameworks, such as ShareDB, require storing the model in a specific format and shape, or that the frontend connects to the model in a particular way.
We wanted to avoid major changes like this. An ideal solution would need to work well with our current tools, including:
- Apollo + GraphQL to build an API schema shared by our frontend and backend services
- GraphQL Code Generator and Typescript to ensure type safety across the entire stack
- Apollo Client on the frontend to store requested data in a normalized object cache that allows React to intelligently subscribe to changes
- PostgreSQL and relational database patterns/features like normalization, constraints, and transactions to help guarantee data consistency and correctness
This stack strikes a good balance between feature velocity and stability, and we wanted to build on top of it — not replace it.
Controlling our destiny
As we considered these approaches, we evaluated a number of open source libraries. We're generally enthusiastic about adopting and contributing to OSS, and originally thought to do so here.
While there are some great projects out there, like Automerge and Y.js, it can be risky to outsource something as core as our application state. Even really promising projects can lose momentum: ot.js, for example, is an Operational Transform library with over 1.2k stars on GitHub, but is no longer under active development and is looking for a maintainer.
Atomic Operations
After considering our options, we pursued an approach inspired by Figma's hybrid solution. We call it Atomic Operations (AO), as all edits to application state are broken down to their smallest atomic parts.
For us, this technique struck the right balance between ease of implementation, compatibility with our stack, and control over the application foundations.
Splitting the Atom
AO mutations exist at the single property update level, such that two operations of different types cannot conflict with each other.
It is, however, still possible for two operations of the same type to conflict. This is determined by an operation's conflictId, which is a concatenation of its type and the ID of the object being edited. 5 Since we use last-writer-wins semantics, we don't merge conflicts, we just pick a winner.
For determining which operation is "last", the server keeps track of a monotonically increasing counter per object that increments with each write. Upon acknowledging an operation, the server includes the latest value of this counter. To determine which operation is a winner, the client simply chooses the operation with the higher value. A central authority is required to implement this monotonic counter, prohibiting any distributed implementations.
As an example, take a hypothetical object type "foobar":
interface Foobar {
id: string;
name: string;
color: string;
}Here are some examples of atomic operations for creating and editing a foobar:
{
type: "CREATE_FOOBAR",
conflictId: "CREATE_FOOBAR-123ABC",
payload: {
id: "123ABC",
name: "My new foobar",
color: "#DE1738"
}
}
{
type: "SET_FOOBAR_COLOR",
conflictId: "SET_FOOBAR_COLOR-123ABC",
creationId: "CREATE_FOOBAR-123ABC",
payload: {
id: "123ABC",
newColor: "#0B6623"
}
}Again: by breaking down all edits to a foobar object to changing individual properties, we remove the need to worry about how different operations might merge — at this level of granularity, only one write can win.
A nice benefit of this decomposition is that all mutations to state are described by plain objects. A keen eye might note some parallels with how Redux defines actions, and indeed AO similarly benefits from making state mutations predictable, transparent, and easily testable.
Finally, we implemented undo / redo by requiring all atomic operation to include an additional operation that can undo the change. As an example:
{
type: "SET_FOOBAR_NAME",
conflictId: "SET_FOOBAR_NAME-123ABC",
creationId: "CREATE_FOOBAR-123ABC",
payload: {
id: "123ABC",
newName: "My slightly less new foobar"
},
undo: {
type: "SET_FOOBAR_NAME",
conflictId: "SET_FOOBAR_NAME-123ABC",
creationId: "CREATE_FOOBAR-123ABC",
payload: {
id: "123ABC",
newName: "My new foobar" // The original name
},
}
}Getting fractional
A drawback of AO is that certain types of mutations can be difficult to express as simple last-writer-wins operations.
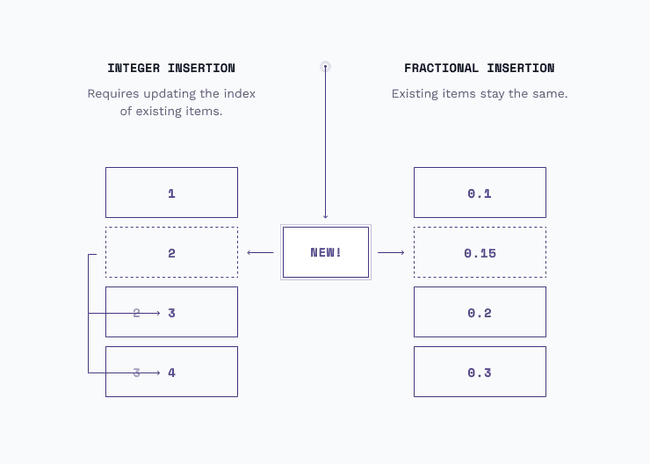
One such case is ordered collections. With classic integer indexing of a collection, rearranging members can easily create tricky conflicts. For example, if someone inserts a new item between positions 1 and 2, and someone else inserts a new item between positions 3 and 4, each newly-created item's index value is dependent on insert order, which requires updating the index of all existing items.
To solve this problem, we again borrowed a page from Figma and employed fractional indexing. The basic idea is to use fractional values (from 0 to 1) instead of natural numbers (0, 1, 2...) to describe the order of a collection. 5.5
When inserting an item into a collection, one doesn't need to update the index of existing items, since there are an infinite number of fractions between any two indices to choose from. The base-95 string representation we chose can also be compared lexicographically, avoiding issues around serializing/deserializing to a number to properly sort a collection. 6
Cell Locking
Another type of challenging mutation is live multi-user editing of text strings, which is largely impractical to implement with AO. Using last-writer-wins for the body text could result losing entire paragraphs of user work.
While this could be a deal-breaker for certain applications, it's acceptable for Hex since our product uses a cell-based, notebook-style logic UI. When a user is editing an individual cell, they display their presence, acquire a lock, and are the only ones who can edit it until they release the lock or have it taken over by another user. This limitation is actually desirable from a workflow perspective, ensuring users can't step on each other's work.
Implementing AO
The Apollo Program
To properly update the multiplayer state, AO requires both a server-side and client-side handler for each operation.
We used the Apollo Client cache for client-side model storage and mutation. Model changes happen via direct cache writes. Operations are applied locally before being sent to the remote server. Since edits are applied immediately after they are performed, the UI feels snappy.
While waiting for acknowledgment from the server, the client queues any updates from the remote that share a conflictId with the inflight operation to avoid "flicker" from rapid changes. Upon response from the server, the client applies any upstream operations that are deemed more recent.
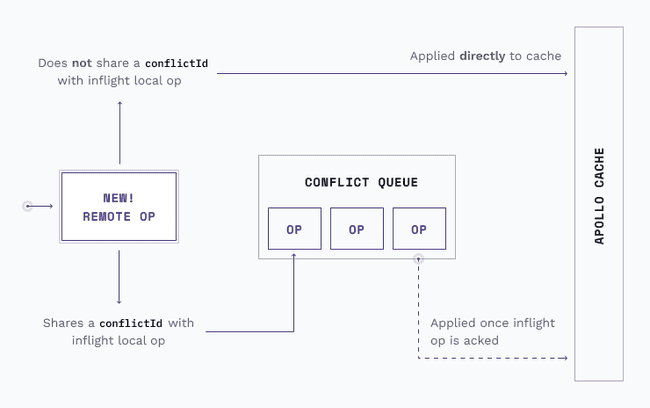
To prevent any GraphQL query responses from accidentally overwriting changes, we used client-side resolvers to query anything inside of the multiplayer model. 7 While sharing the Apollo Cache introduces a risk of a GraphQL mutation editing the same piece of state as an atomic operation, we ensure safe changes through testing all our cache mutations.
On the backend, we normalized the model and stored each separate entity in Postgres across several tables. In addition to guaranteeing data consistency and correctness, this allows a client to connect to any server, rather than a specific host with the model in-memory, allowing for better load-balancing.
Leveraging our existing tooling in this way cut down on how long it took to implement the framework itself, allowing us to jump into actually writing operations and handlers.
Incrementalism FTW
For initial development and experimentation, we made a test app that only creates and edits simple shapes of various types. We ran it through a gauntlet using both automated and manual tests, including having the whole team use it concurrently.
When we were sure we had ironed out any kinks, we moved to start implementing AO in our main app.
On the frontend, many of our components didn't need to change at all since we still used Apollo Client under the hood. Most of our components even kept their original GraphQL queries. This reduced the surface area of changes, and meant AO was live in the hands of users before we formally announced support for real-time collaboration.
By using our existing technology in this way, we were able to take an incremental approach to adding live collaboration. We moved our application over piece-by-piece, mutation-by-mutation, over the course of several weeks as a part of our normal, rapid release cadence.
The net result is that we were able to quickly see how it behaved in the wild, and avoided a long-lived feature branch blocking development on the rest of the frontend.
Next steps
We're happy with AO, and have already built several additional new features on top of it without issue.
We also have flexibility in the future. As an example, we could always adopt OT or CRDTs for simultaneous text editing if we choose to support it, and leave the rest as last-writer-wins atomic operations.
We will also be keeping an eye on new libraries and projects. Automerge and Y.js are exciting new CRDT frameworks that promise live collaboration out-of-the-box. Room Service (still in "early access" at time of this writing) could eventually be a good option for those looking to get started quickly. And we expect a lot more innovation in this space as real-time collaboration becomes standard for more applications.
Conclusion
OT and CRDT are very powerful tools, and might be the right way to add multiplayer to your application. They can, however, be challenging to implement yourself, and complex to use correctly.
If the application you are building can rely on last-writer-wins semantics, Atomic Operations might provide a more pragmatic approach.
We would be happy to hear from you if you're planning on (or already have) implemented similar technology! Drop us a line.
And, of course, we're hiring!