Blog
Managing Magic
Using the Data Browser to improve and customize Hex Magic for your organization’s data.

Update: The Data Manager is now referred to as the Data Browser. To catch up on even more new developments on Hex's Magic AI and no-code features, read our Spring Release 2024.
For the past year, we’ve been releasing features that bring the latest AI capabilities right into the notebook you’re already working in, so you can work faster without switching contexts. Together, we call these AI enabled features Hex Magic. There’s automatic error fixing, Python code completion, auto-documentation… but the bread and butter of Magic is SQL generation: going from a natural language question to a SQL query that answers the question correctly.
SQL generation is the most impactful and time saving Magic tool, and it has also been the most technically challenging to perfect. If you’ve used Magic a lot, you’ve probably experienced some incredible moments where it wrote amazingly complex queries for you… and probably a few less incredible moments— maybe it tried to filter on a category that didn’t exist, or use some weird staging table that didn’t make sense.
Today we’re opening public beta access to the Data Browser (formally called Data Manager), a metadata tool that’s purpose-built to let you enhance Hex Magic’s SQL skills by custom tuning them to your organization’s data. It’s designed to take Magic SQL generation from “pretty good” to “excellent” for your specific tables and columns, and it works fantastically well.
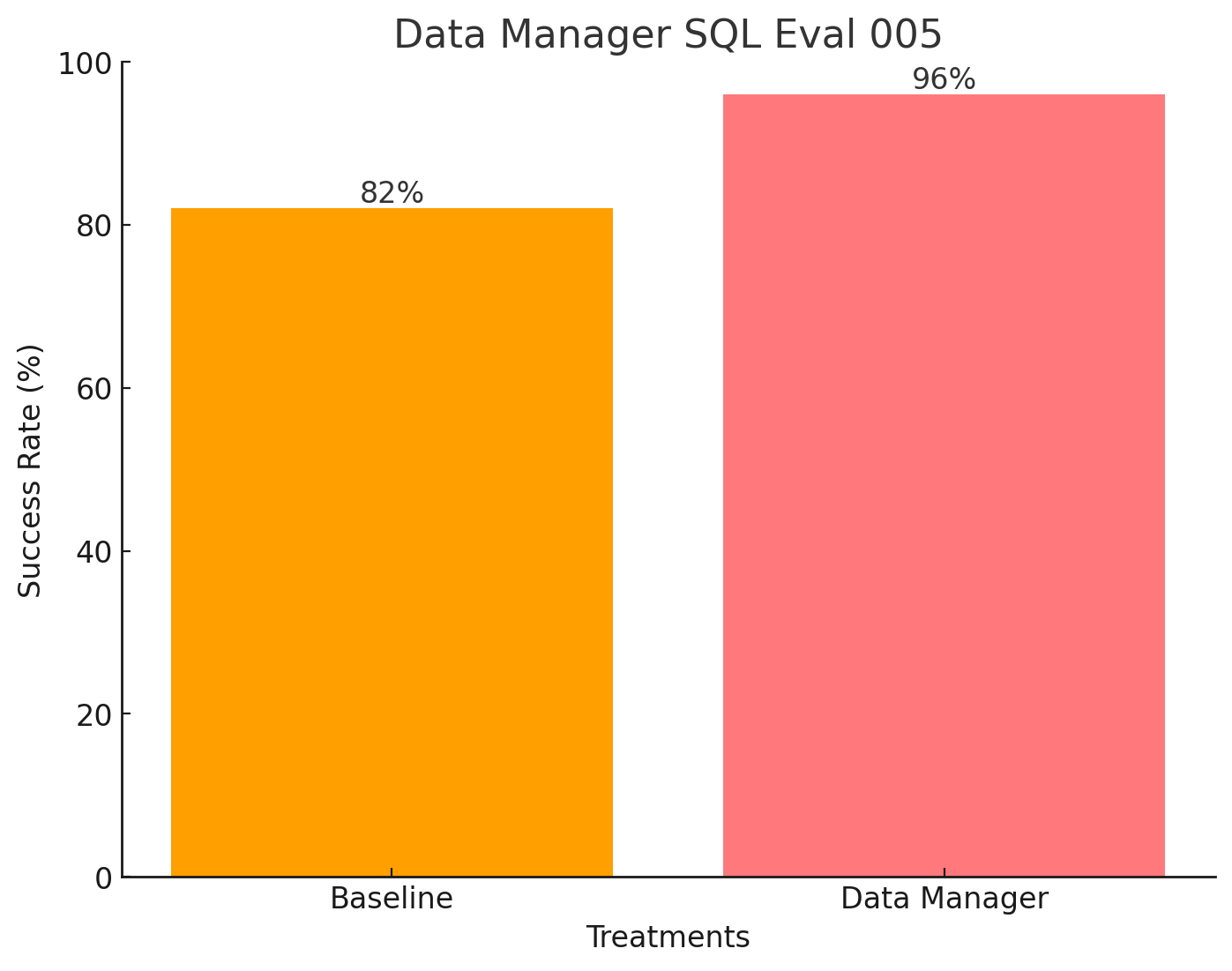
After about 10 minutes curating the Data Browser on an internal connection, I was able to improve SQL generation success rates from 82% (pretty good) to a dazzling 96% (excellent!) on our evaluation suite of test prompts.
In the coming weeks, we'll be publishing more technical deep-dives into our evaluation framework and how we think about benchmarks and performance for AI text-to-SQL. Stay tuned!
Data Browser Basics
The Data Browser itself is nice and simple, since most of the magic happens under the hood. It provides a straightforward interface for you to access and edit four different kinds of metadata about your data connections:
- Schema, table, and column information from your data warehouse.
- All your dbt documentation, live synced from dbt Cloud or manually added from dbt Core.
- Endorsed Statuses can determine which schemas, tables, and columns should be included, excluded, or prioritized for Magic AI.
- Any additional descriptions or custom metadata you want to provide.
*7/31/24 update: Priorities — have been replaced with Endorsed Statuses. This screen video will be updated soon.
Under the hood, all this metadata is recombined, enriched, and then used to create vector embeddings for all the tables and columns in your warehouses. We store these embeddings in a vector database that runs securely on the same servers as Hex (not some third party tool!) and use them to power the semantic search algorithms that are the secret sauce of Magic’s SQL generation engine.
What the heck are vector embeddings? They're a way to numerically represent a piece of content in a way that makes it very easy to identify similar pieces of content— without having to explicitly define what you mean by "similar".
They're crucial to doing meaning-based similarity search over data. If curious for more depth, Simon Willison has a great explanation post.
Adding detailed metadata to the Data Browser improves the quality of these embeddings, which improves Magic SQL generation in two main ways:
- Increased table retrieval accuracy: Improving Magic’s ability to choose the right tables and columns to answer a natural language question.
- Reduced string hallucinations: Keeping Magic accurate when actually writing joins, filters, and case statements that require specific string matches to the underlying data.
Potentially the coolest part? You can provide really nuanced guidance using just natural language. Magic is incredibly responsive to metadata like “only use this table if the prompt explicitly requires raw stripe data, otherwise use fct_orders”, or “this column contains a stringified array of items”. You can essentially educate it as you would a human member of your data team!
When we realized that, we decided to also make custom descriptions from the Data Browser visible to humans working in Hex via the data browser, so you never have to worry about needing to repeat yourself in multiple places. If it’s useful for the AI, it’s probably useful for people too!
That’s the Data Browser! It’s deceptively simple, and we’re proud of how much oomph we’ve packed into such an easy to use interface. Workspace admins can find the Data Browser in the bottom left of the homepage sidebar, or at https://app.hex.tech/your-workspace-id/data.
To help you get started, the rest of this blog post will detail specific examples and guidance for using the Data Browser to improve your organization’s Magic SQL experience.
Using the Data Browser to increase table retrieval accuracy
When you ask Hex Magic a question, the first thing it does is use metadata from the Data Browser to perform a semantic similarity search for tables and columns that might be important for answering that question. We call this Table Retrieval, and it’s by far the most important part of the SQL generation process.
The more information you add to the Data Browser, the more likely it is that Magic will be able to successfully map your natural language question to the right tables and columns, even if you’ve phrased your question imprecisely. Let’s look at some real examples from our demo workspace of prompts that should be working, but aren’t— and how we can fix them..
Example #1: Which customers bought something recently that was a previous best seller?
This should have been easy for Magic, but there’s a complication: A few years back, someone created a one off RAW.SALES.BEST_SELLER_LIST table. It actually hasn’t been updated in years, but it sounds like a great option and the title obviously matches the semantic search criteria of the prompt. This query winds up failing, as a result of joining in that bad table.
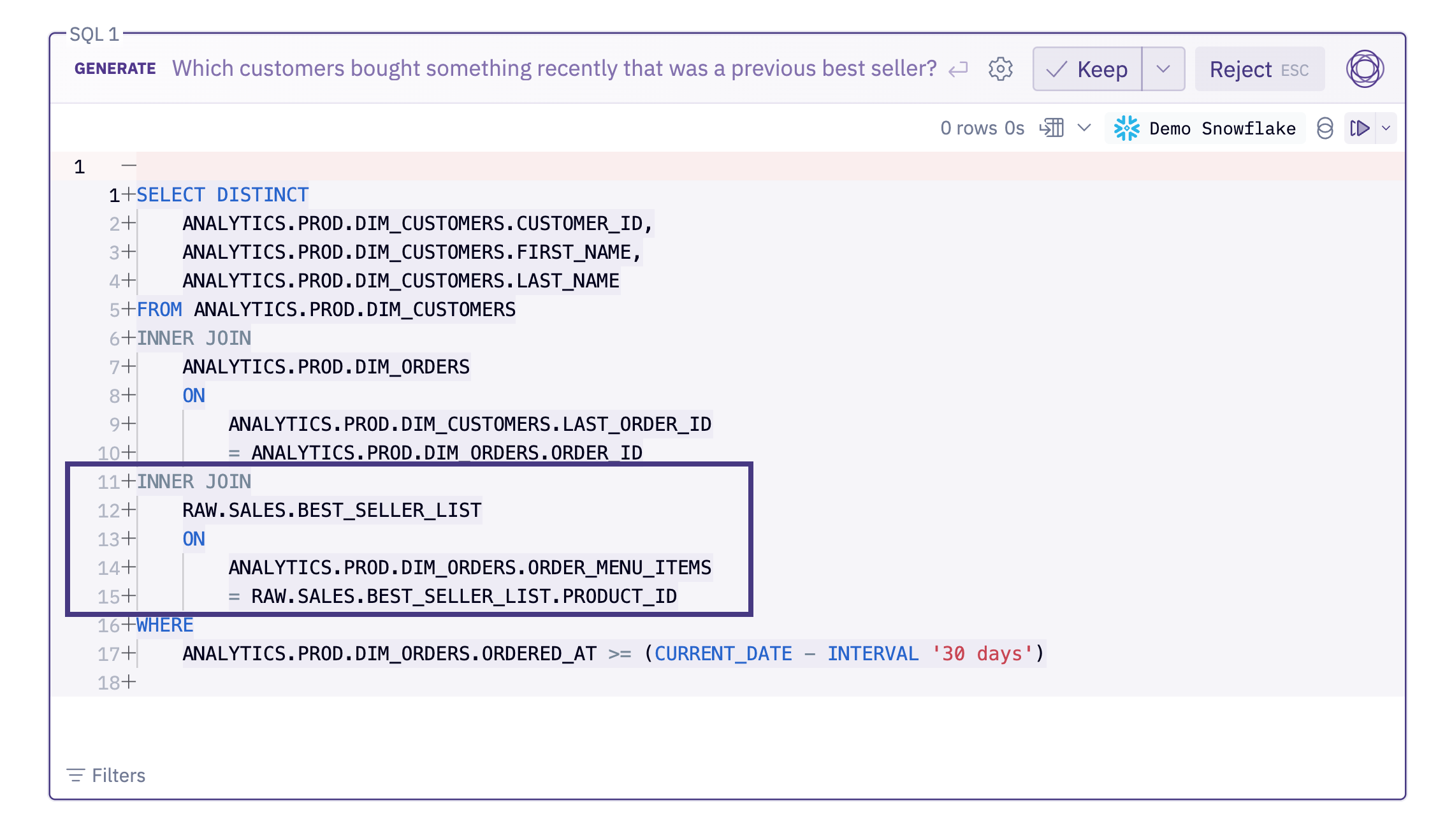
This is a ubiquitous and frustrating AI SQL problem. Our warehouses are invariably less tidy than we’d like them to be, and there’s inevitably leftover scratchpad tables, dev schemas, and other common hazards that humans either know instinctively to avoid or have cultural knowledge about, but LLMs will naively opt for.
Luckily, it’s really easy to tidy these things up with the Data Browser. All we have to do is exclude the offending table, or perhaps even the entire RAW database. In the absence of that tricky table, Magic will realize it has to calculate best sellers itself, and the query will work great.
Try it yourself! This is the easiest and quickest improvement you can make to your workspace’s Magic SQL generation: take 10 minutes and add some Endorsed Statuses in the Data Browser! Start at the database level, excluding anything that’s obviously unneeded, and work your way down towards the table level.
I recommend spending no more than 10-15 minutes initially to give yourself a foundation, and then do this on an ad-hoc basis as you bump into issues.
Example #2: Do customers with food allergies cancel orders at a higher rate than those without?
This query is almost great. It’s impressive that Magic was able to semantically map “allergies” to things like has_gluten, but it’s using analytics.prod.stg_menu_items, which is a staging model. There’s a nice, modeled is_allergen_free field in the final order tables that’s a better choice here.
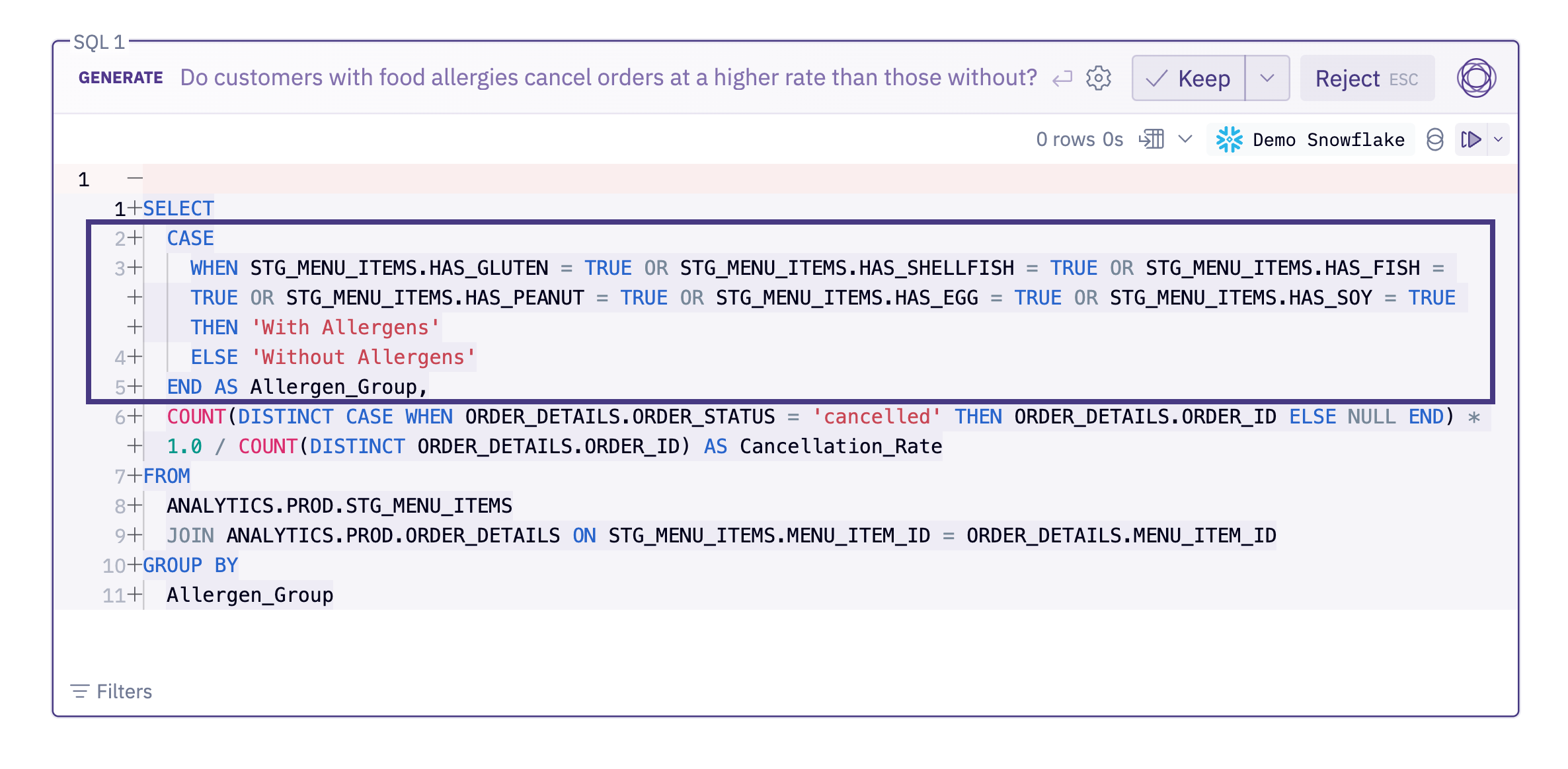
We could completely exclude the table like in Example #1, but it might be useful some day to ask Magic about a specific allergy or something else from the raw data. Instead, we’ll add some custom metadata to it that tells Magic when it should and shouldn’t use it, and select the right Endorsed Status for the non-staging tables in that schema.
This ensures we get the default behavior we’d expect, but leaves the door open to explicitly ask for AI generated queries against the staging tables.
And just to make sure: if I ask for something that can only be answered using the staging table, it will heed the custom guidance and still use it. Perfect!
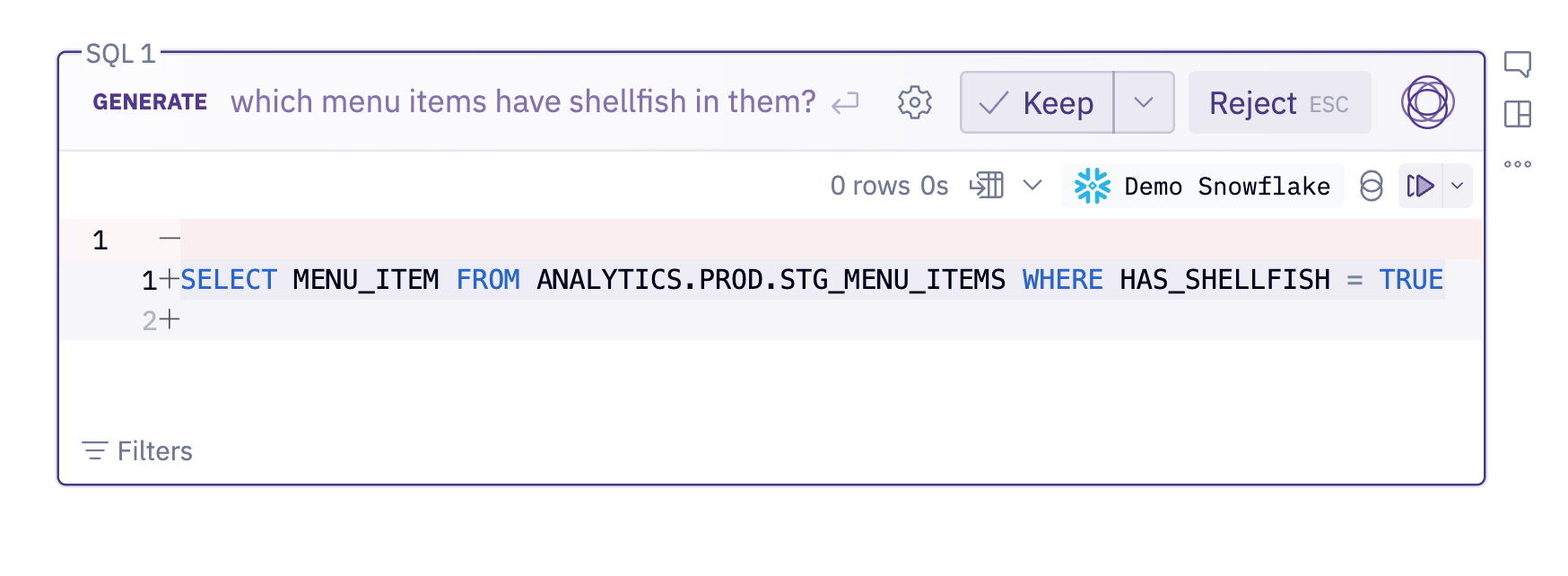
This is a great example of the simplicity, power, and flexibility of the Data Browser— you can just describe in plain language how your data should be used. Behind the scenes, Hex is doing a bunch of freaky, top secret alchemy with those natural language descriptions to make sure that they’re properly considered when generating SQL. But you don’t have to think about any of that!
Try it yourself! If Magic keeps using an incorrect table, but it’s one you might occasionally need in other contexts, instead of excluding it try instead applying an endorsed status to the right table that you’d rather use and adding custom guidance to the lesser-used table that makes it clear when, and only when, it should be used.
In this example, I added a custom description that said “only use this staging model if the prompt specifically requests a staging table, or a specific field only present in this table.”
Using the Data Browser to reduce string hallucinations
LLMs generate SQL based on statistical patterns learned from their training data and encoded in their weights. This means that without specific guidance and context in their prompt, they’ll just spit out whatever “feels right” based on the queries in their training set— these random inconsistencies are called ‘hallucinations’.
If you ask an AI to write a SQL query that gets all recently shipped orders without providing any further context, it will just make something up, maybe where order_status = 'shipped'. Or maybe it will opt for SHIPPED, or where is_shipped = True.
And it might still produce the most syntactically perfect SQL query in the world, and use all the right tables and columns, but it still returns 0 rows because it filtered on order_status = 'shipped' instead of the correct order_status = 'Shipped'.
These string hallucinations are nitpicky, tough to debug, and come in a million equally frustrating flavors. They’re actually the most common cause of text-to-SQL failures!
Maybe you didn’t want either of those filters, and instead it should have used where shipped_date is not null. Or maybe it’s happening in a case statement, and the data you’re getting back is wrong because the when department = 'Swim' should have been when department = 'Swimwear'. The list of mistakes is potentially very, very long.
Explicitly enumerating, or even just describing options for these fields in the Data Browser can reduce hallucination rates down to near 0. Let’s look at some real examples.
Example #1: How many orders have shipped but not yet been delivered?
This is a very basic query that Magic generates with syntactical perfection, but is still failing due to a string hallucination. If it filtered on the correct STATUS = ‘Shipped’ instead of ‘SHIPPED’, it would have worked great. There were 9 different prompts in my test set failing because of this one string match issue!
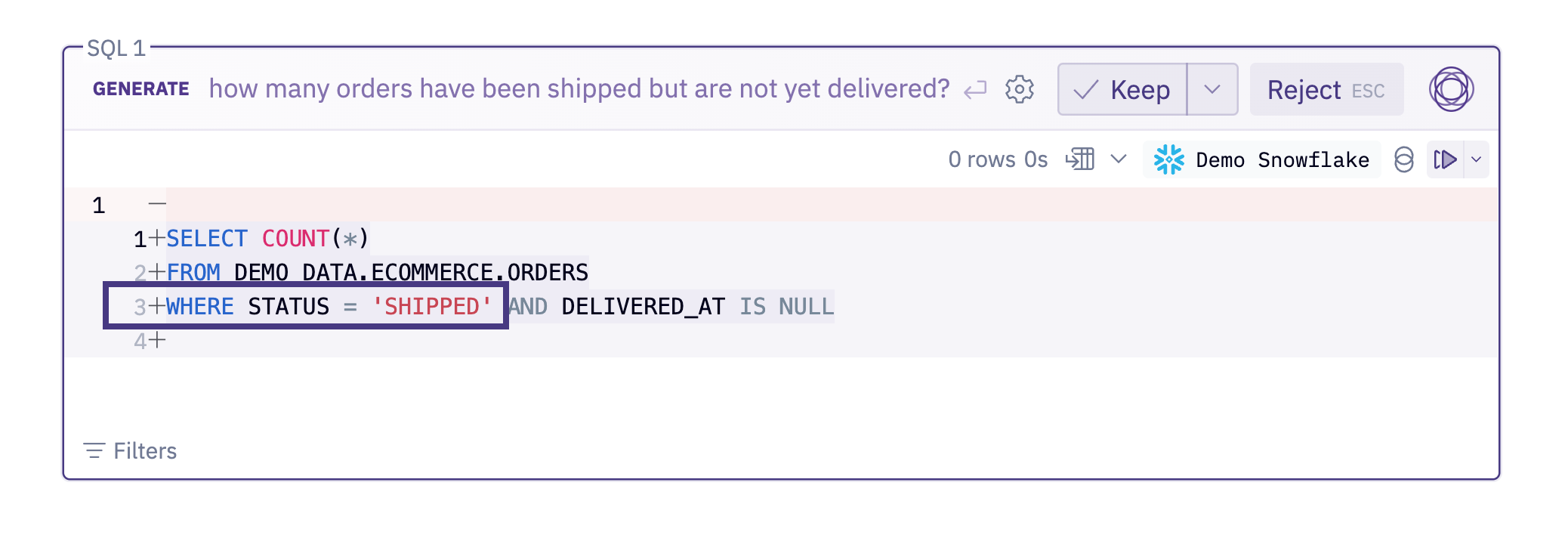
The fix here is really simple. Status is a low cardinality column, with only 5 options. They’re not likely to change, there’s only a few of them, and they’re frequently used in filters. Because of this, it actually makes sense to copy/paste them all directly into the Data Browser, or add them to your dbt documentation and let it automatically sync over.
We’ll make this change, and instantly see the prompt start working as expected. This’ll probably be a helpful addition for any humans who work with this table in the future too!
Try it yourself! For low cardinality string columns that are often filtered on or used in case statements, it’s usually worth it to paste the entire list of values into that column’s description in the Data Browser.
This is a great thing to spend 5 or 10 minutes on in your initial Data Browser setup!
Example #2: How many orders are shipped from the houston distribution center each week?
This is another very simple question, and everything about the generated query looks great— except it’s filtering on NAME = 'houston'. Distribution centers follow the naming convention ‘City ST’, like ‘Houston TX’.
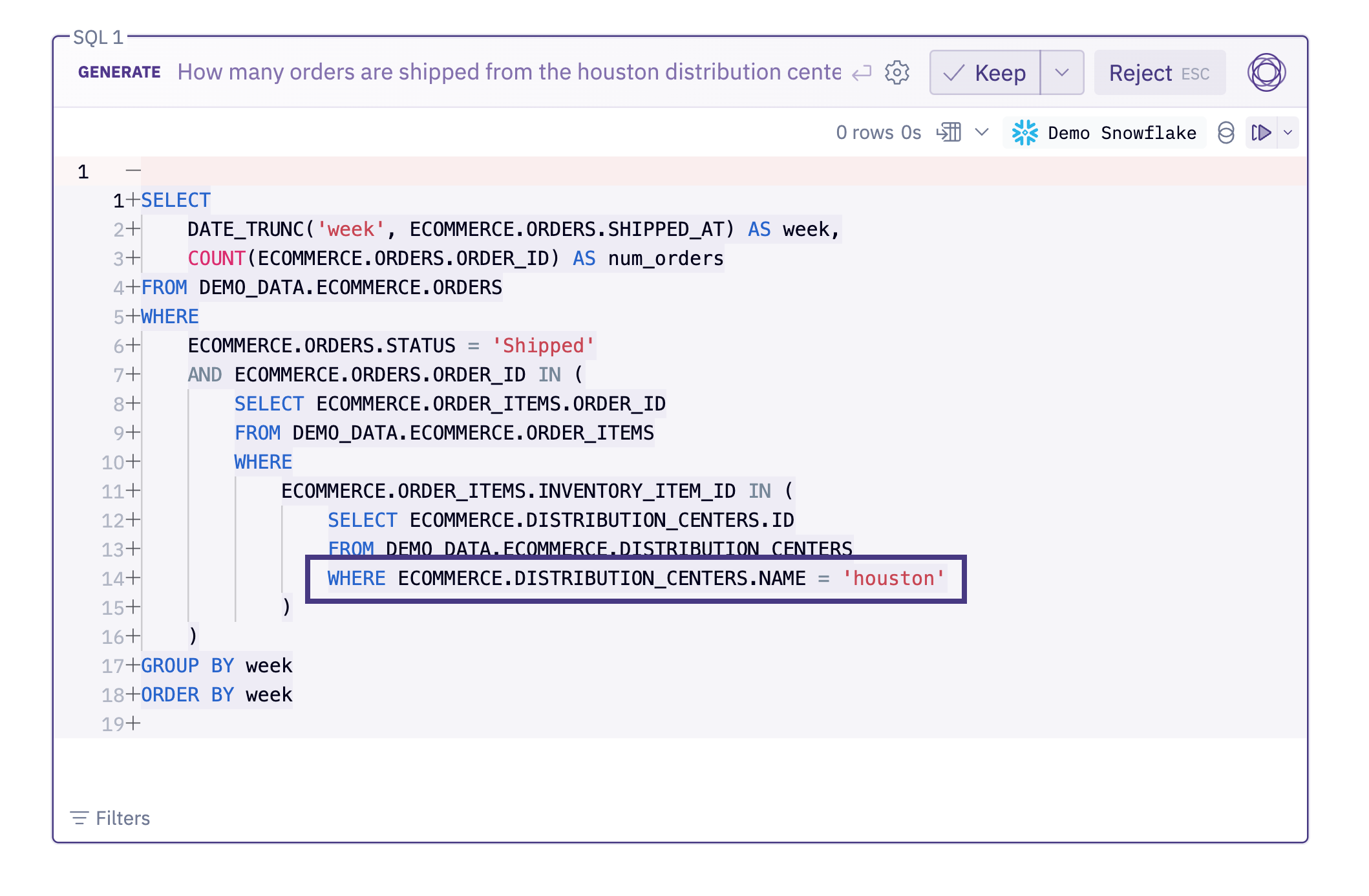
This one is a little different from the first example because of a difference in cardinality. There’s a ton of distribution centers, so instead of enumerating all possible options in the Data Browser, we’ll just describe the pattern of the column in the Data Browser. A few seconds later we try the same prompt again and get a perfect query back.
Try it yourself! For high cardinality string columns that have too many options to list but follow a consistent pattern (like a City / State combo or a [email protected] email), try explaining the pattern in natural language in the Data Browser.
In this example, I added the custom description: “City State pairs, like 'Memphis TN’”.
It’s always amazing to me that this works as well as it does, but Magic really seems to pay attention to even my strangest explanations and caveats.
In our internal testing, even small investments in adding additional metadata have resulted in tremendous boosts to Magic’s accuracy and semantic knowledge of our data. We can’t wait for you to use it, and are really eager to hear how Magic is performing for you after a bit of Data Browser tuning. Please reach out and let us know at [email protected].