Blog
How OM1 is advancing healthcare R&D insights with Hex and Snowflake
And a flexible self-serve data app
OM1’s fragmented, siloed analytics workflow was starting to break down at scale. A simple request from a business user — “How many patients do we have using this new drug?” — would turn into a days-long game of chutes and ladders across multiple teams and multiple tools. After a while, the data team noticed that less and less people were asking questions or requesting updates to reports.
But OM1 is a data company — they provide massive healthcare datasets of anonymized patient data to medical providers and researchers — so becoming less data driven was simply not an option.
Zach Bryant, Associate Director of Data & Analytics, had a bit of a crazy idea: instead of throwing money at the problem by hiring more clinical data engineers, what if they could turn their existing business users into clinical data engineers?
This is the story of how OM1 used Snowflake and Hex to build a flexible self-serve data app that unified their fragmented workflow and empowered business users to act like data engineers.
🔍 You can check out their data app which is open-source and embedded below.
Improving patient outcomes with healthcare datasets for clinicians, researchers, and scientists
OM1 provides healthcare datasets of anonymized patient data for scientists, clinicians, and researchers to advance research and precision medicine for chronic diseases. Their research-ready datasets are used to make gains in personalized medicine, evidence generation, and evidence research for immunology, mental health, dermatology, cardiology and more.
Imagine you need to get a knee replacement. Using data from OM1, your doctor can see a comprehensive view of your health and compare it to similar patients to estimate potential outcomes. Maybe they see that, based on your history and data, there is a 60% chance of success with the knee replacement and a 10% risk of severe complications, and walk you through what that means.
Researchers and clinicians can look at that same data to see gaps in patient care, find unmet needs in the healthcare system at large, and identify opportunities for medications to be used in better ways. These insights might even be used to drive new regulations in U.S. healthcare; for example, submitting drugs and devices to the FDA that weren’t able to be done through clinical trials.
The challenges of data management with nation-wide healthcare data
The main thing to know about comprehensive healthcare datasets is that they’re BIG. To create their research-ready datasets, OM1 collects hundreds of billions of data points from 330 million patient records — relying on healthcare systems, insurers, and other industry partners as sources.
Within all of that data, there are endless combinations of variables that their customers could be interested in. For example, a clinician might want to look at a heart failure dataset and see how many patients have experienced heart failure and are on an anti-coagulant drug and have an underlying condition of PTSD.
The other unique thing about healthcare data is that it’s constantly evolving in structure and scope; new practice guidelines emerge, new medications are constantly coming out, and new studies with updated trends are published all the time. OM1’s customers — clinicians, scientists, and researchers — need to be nimble and incorporate adjustments to their data as these updates happen to make sure their findings are up-to-date. In turn, OM1’s sales and marketing teams need easy, ad hoc access to best serve their customers and to provide best-in-class service about the data that they are known for.
These two factors — maintaining speed on the scale and frequency of updates of data that OM1 offers AND making sure sales and marketing teams had the information that they needed in a timely manner — were two separate challenges that OM1’s data team needed to solve.
1. Maintaining speed and scale
On the one hand, these massive datasets were just too large, complex, and changing too much, causing expensive aggregations that would need to constantly be updated. They were also too complex to be explored ad hoc in traditional BI tools without help from the data team, creating painful experiences for business users to ask their own questions of data. Data engineers could carefully craft dashboards that were fast and efficient, but as soon as users struck out on their own, they’d run into 10 or 20 minute query runtimes and, to quote Zach, “get bored waiting and move on to greener pastures.”
2. Keeping up with evolving requests from sales and marketing
On the other hand, the rapid pace of evolution on questions from business users also made it challenging for the data team to support updates to datasets, BI dashboards, and reports. Even if the data team tried to create reports for their sales and marketing teams, they could never keep up with the demand; the number of aggregations and mappings needed were endless. As all data people know, every report delivered winds up generating three more follow-up questions.
Here is an overview of OM1’s pipeline with the challenges mentioned above:
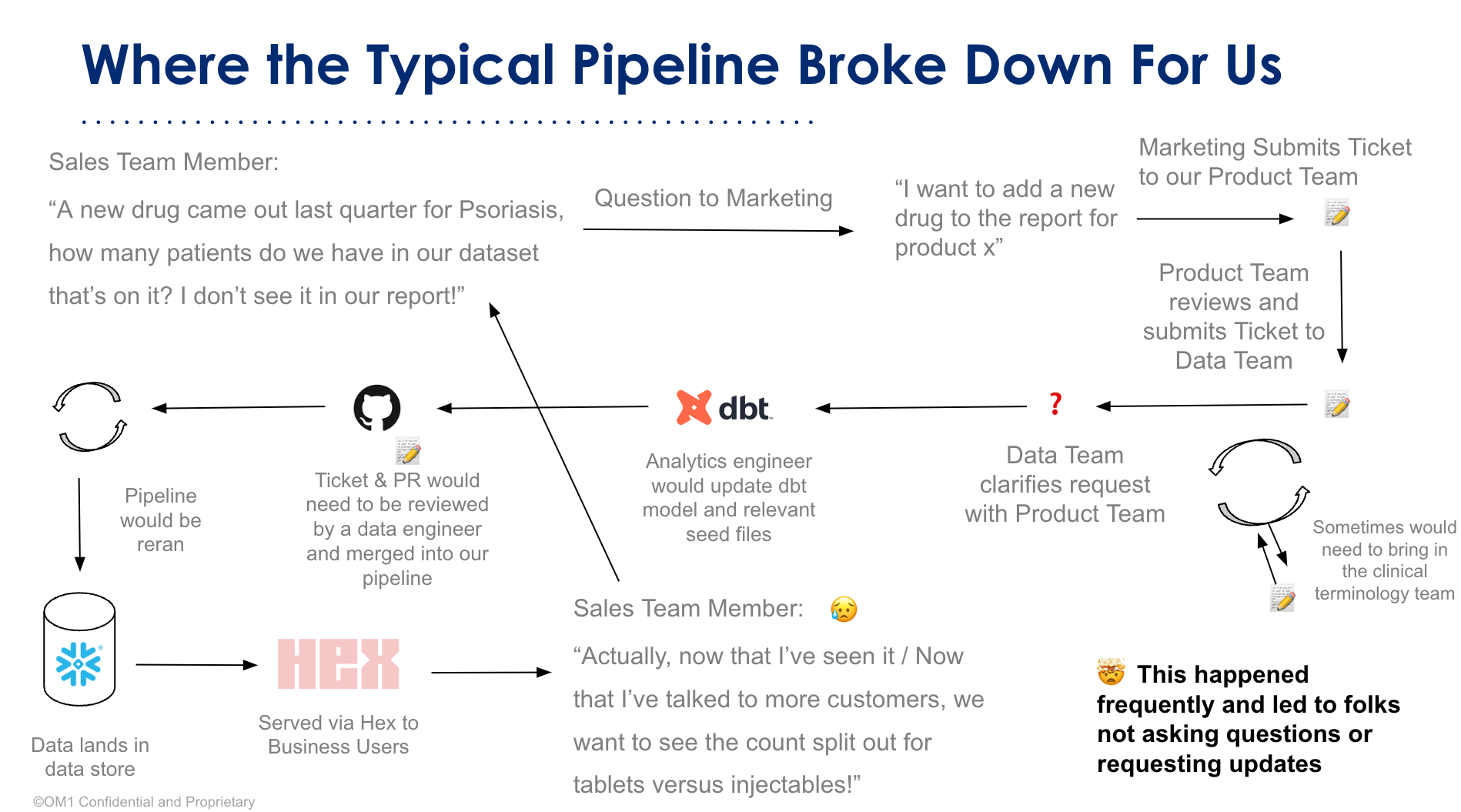
OM1 needed to upgrade its data tooling to something that let the data team move faster and gave business users better access to self serve, with some guardrails.
The solution: A data app that puts business users in the driver’s seat
After adding Hex to their existing stack with dbt and Snowflake, the next step was to empower trusted self-serve. OM1 built a data app in Hex that let business users not just explore data, but actually manage the mappings for data categories like medications and conditions without having to write any SQL or Python.
This data app sits right on top of Snowflake and was easy for the data team to build using multi-modal methods of working with data — combining intuitive UI-based features with SQL, Python, and Snowpark.
Business users interact with a custom point-and-click interface, and behind the scenes, their requests are handled by SQL queries and Snowpark code that reads and writes to the warehouse.
The Role of Snowflake in Scalable Analytics
Snowflake provides scalable data warehousing and analytics capabilities that supports OM1’s need for handling massive datasets while ensuring data integrity and performance. Learn about our integration with Snowflake.
This is saving the data team hours of time every week by empowering business users to be their own data engineers for ad hoc use cases directly within a user-friendly interface. With OM1’s Mapping Manager data app, business users dictate what they care about in the UI and the rest happens automatically.
➡️ Try the open-source mapping manager for yourself. OM1’s Mapping Manager data app is open-sourced.
Instead of adding head count, OM1 brought on tools to go further with their data
Before Hex and Snowflake, OM1’s data architecture of rigid BI tools made arriving at these data insights “a really long game of telephone” that left people to move forward without the data they needed.
Now, with a unified workspace for analytics and a flexible self-serve data app, OM1 is expanding internal knowledge throughout their company. Sales and marketing teams are helping clinicians, researchers, and scientists in faster ways by quickly understanding the full spectrum of data that OM1 can offer to them.
By empowering internal temas to manage data mappings independently, OM1 reduces dependency on IT and accelerates decision-making processes across the org.
If this is is interesting, click below to get started, or to check out opportunities to join our team.