Blog
Lazier and faster: under the hood of our new compute engine
Using DuckDB and Arrow to make multi-modal analytics fast



Hex’s multi-modal architecture comes with some unique engineering challenges. A Hex project can include SQL queries, Python code, charts, pivot cells, spreadsheet tables, maps, and more. Every time a project runs, every cell needs to query, store, transform, and pass data around to other cells — including datasets up to hundreds of millions of rows.
Handling all this data across multiple formats becomes a complex engineering problem! Until recently, we relied on Pandas dataframes as the common interchange format for data. This was fine at first, but comes with serious scaling and performance limitations, and we wanted to build something more advanced.
We recently finished migrating our cell backends to a new DuckDB-based architecture that directly queries Arrow data stored remotely in S3, instead of materializing dataframes into local memory. Performance improvements are variable based on project complexity, but we’ve seen on the order of 5-10x speedups in execution times for certain project types.
Here’s a brief history of dataframes at Hex, and a peek under the hood of our new architecture.
Building for multi-modality
Way back in the day, we were the first to add a polyglot SQL experience to a notebook interface when we released Dataframe SQL. The game-changing thing about Dataframe SQL was that it wasn't a one-way street: users could query data from Snowflake with SQL, manipulate it with pandas, then keep querying that pandas data using SQL. Under the hood we used DuckDB in the kernel, running queries on top of Pandas dataframes.
At the time, Pandas was an early and obvious choice for the common interchange format. It meant we could make every operation backwards compatible with Python by default, and DuckDB allowed for SQL querying where necessary.
This worked really well — perhaps even better than we could have imagined! Dataframe SQL became incredibly popular, and using pandas as a common interchange format let users seamlessly switch back and forth between SQL and Python with zero overhead.
As we introduced other modalities to Hex like spreadsheets, charts, maps, and more, we stayed with this system: every cell had a dataframe input, and materialized a dataframe output in the Python kernel’s memory. Users could use any of these cells, and they all worked well together, in one place, thanks to the use of dataframes as a standard interchange format.
But as any seasoned data scientist reading this knows… pandas dataframes are big and slow. Just like actual Pandas!

Our simple architecture made for a great UX, but had a major drawback: for every single cell, we had to load all the relevant data into the Python kernel and create a pandas dataframe — even if that data was not being used in Python anywhere in the project.
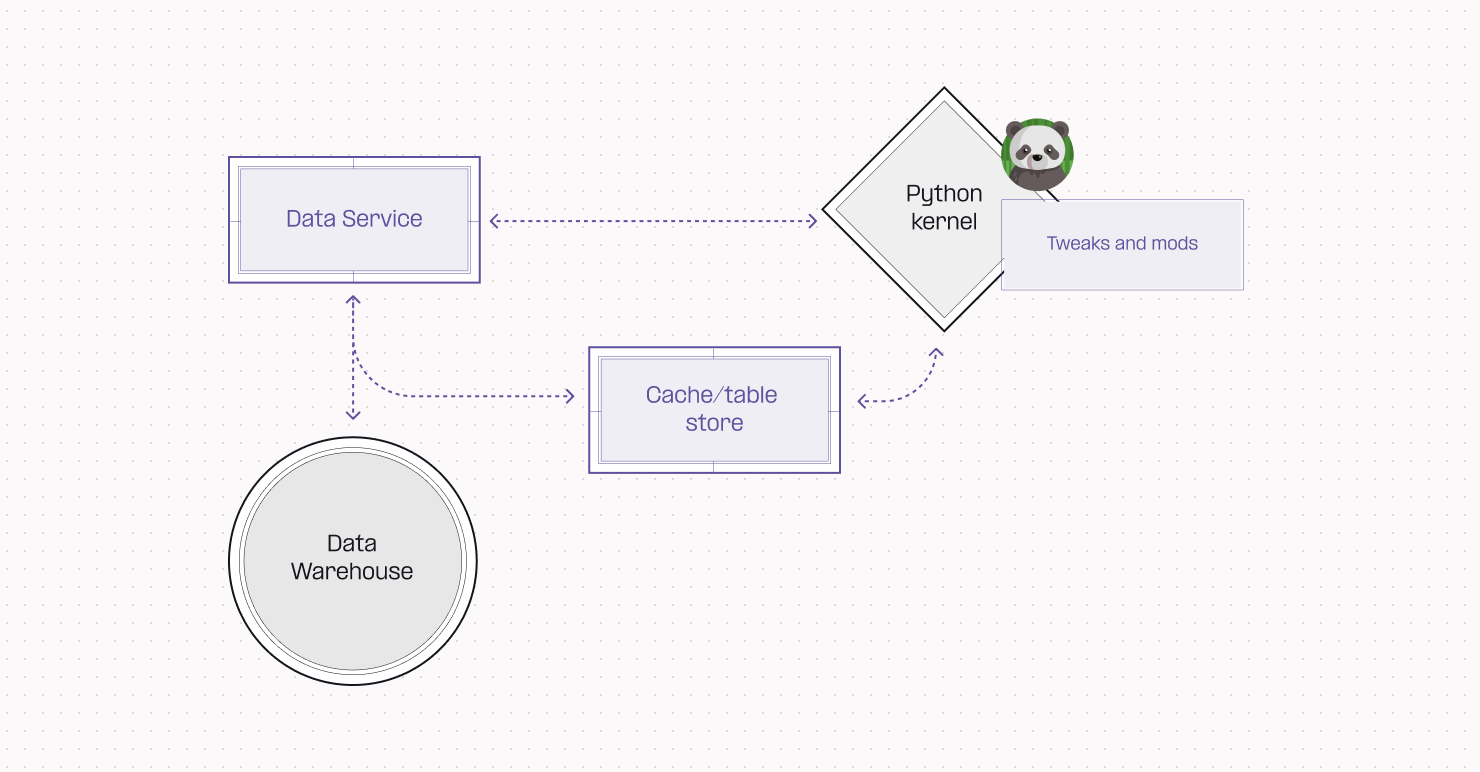
As usage of our custom cell types scaled, we began to see projects where this streaming and dataframe creation time was responsible for upwards of 90% of the total project runtime! It was obvious that this architecture was holding us back, and we had an idea: we realized that it was OK for dataframes to be big and slow… as long as they were lazy, too.

Lazy loading Dataframes
If you've ever used Google Maps, you've seen this concept in action. When you first open the app, it loads quickly, displaying just the area you're currently viewing. As you zoom in or pan around, you’ll notice brief stutters as new map sections and higher-resolution images load on-demand. This is a kind of lazy loading, a common tactic to improve performance by deferring the complete loading of certain objects until they’re actually needed.
We’ve implemented something similar in Hex, but instead of map tiles, we’re lazy loading dataframes! Now, when a SQL or any other non-Python cell runs, it doesn’t actually construct a memory-intensive pandas dataframe. Instead, it returns a lightweight “LazyDF” object that can be passed between cells as if it were a full dataframe.
LazyDFs pretend to be dataframes, but they have one crucial difference. They don’t actually contain any data at first — that’s the lazy part — but they come with an API that allows any cell to run SQL queries against their underlying dataset using DuckDB. For most cell operations, this means no data ever needs to be materialized into the kernel. LazyDFs can process everything using DuckDB queries in our backend data service, and only the final results and previews are sent to the frontend, sidestepping the kernel entirely.
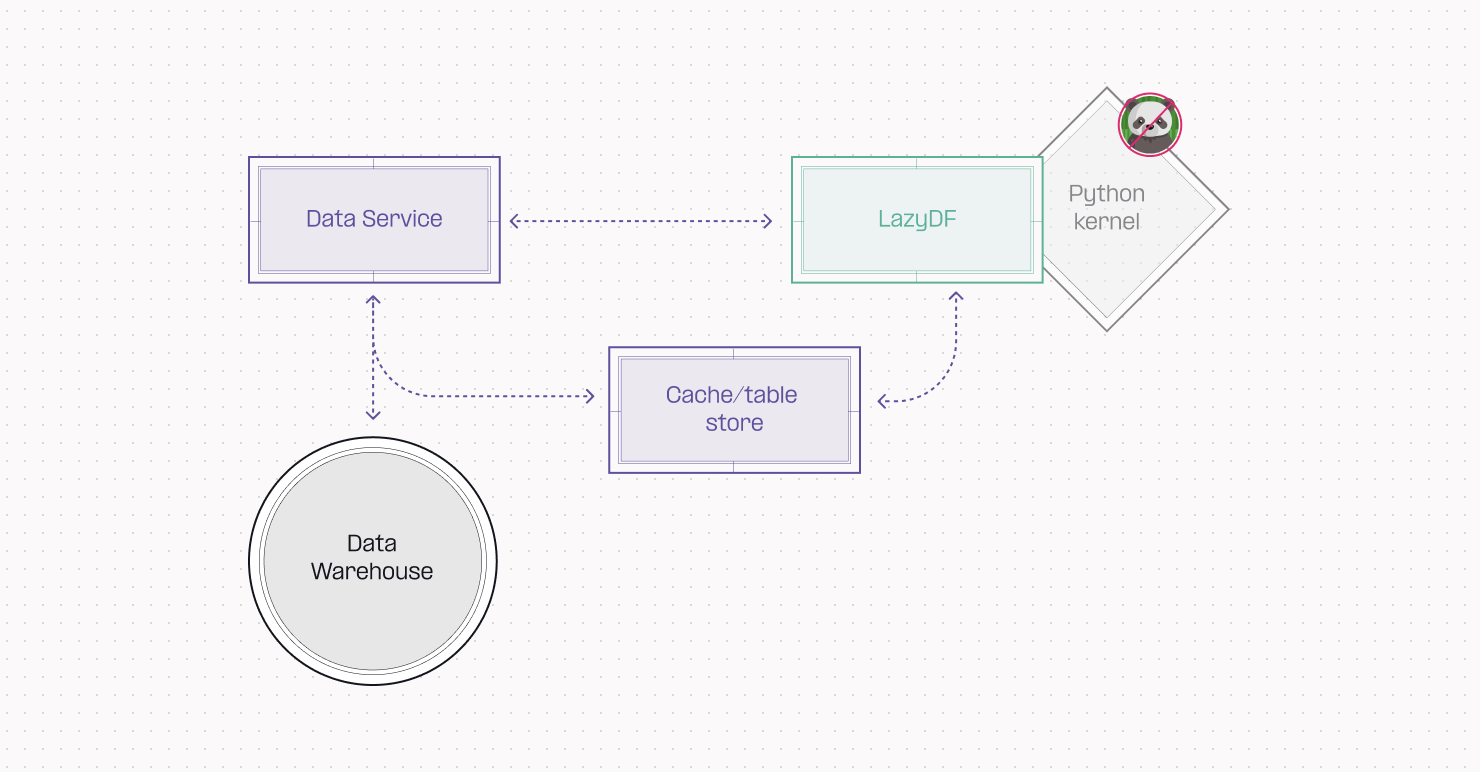
But laziness has its limits! If you reference a LazyDF in a Python cell, it’s magically converted into a real pandas dataframe and sent to the kernel — the same slow old process we used to do for every single cell. Because this happens only upon request now, it might look like some Python cells are taking a little longer than they should. But really, they’re just processing a lot of data for the first time — we promise that the savings from all the other cells in your project not doing that are tremendous.
The most important thing is that the user experience remains unchanged from our old architecture — LazyDFs work exactly the same as normal dataframes. It was a critical requirement of this project that users would never need to run ".collect()" or ".convert()" or anything to bring a LazyDF into Python. We've done a ton of work on this behind the scenes to make sure you don't ever need to think about what's going on under the hood. In fact, if you didn't read this post, you probably wouldn't have even known that Lazy Dataframes exist!
The trio of speed: DuckDB, Arrow, and S3
Building on this kernel-less approach, we made even bigger optimizations to the way we store and reference datasets, by expanding and deepening our use of DuckDB 🦆.
Instead of constructing dataframes in memory and passing those around, cells now write data as Arrow tables directly to a cache in S3 for later DuckDB querying. The lightweight LazyDF stub they return can be passed between cells and operated on with effectively zero performance overhead, while any actual data operations take place in super fast DuckDB queries against Feather files (a format for storing Arrow data).
This is an order of magnitude faster than streaming tons of data down into the Python kernel and creating memory-heavy dataframes for every cell. It also greatly reduces memory pressure, which means you have more freedom to work with larger datasets.
The results: 5-10x project runtime improvements
This has been the most fundamental performance change we’ve ever made, on par with our graph execution engine from Hex 2.0. We’ve seen improvements to project runtimes in the ballpark of 5-10x speedups, fluctuating based on project complexity and data size. Some of the internal projects we use every day have gone from 30+ second runtimes to just a handful of seconds!
Across three test projects, we saw average runtimes go from:
- Project 1 (specific performance test) runtime: 12s → 1s
- Project 2 runtime (an important internal project): 15-20s → 3-5s
- Project 3 runtime (a critical customer workload): >2min → <30s
It's important to note that these benefits are most pronounced in projects that primarily use SQL and no-code cells. Projects that include a lot of Python references will see less dramatic improvements, as LazyDFs still need to be converted to real dataframes for Python operations (for now 😈).
Again, we’ve been incredibly careful to make these improvements while maintaining the seamless interoperability between modalities that makes Hex so powerful. Whether you’re writing SQL queries, building charts, or scripting in Python, everything still just works together without you having to think about the underlying data handling — it’s all just a lot faster now!
Postscript: Moving Beyond Python
These performance gains are a really nice immediate benefit of our new architecture, but we’re even more excited by the future possibilities it unlocks.
By moving most of our data processing out of the Python kernel and into our backend data service (and into the land of DuckDB and Arrow), we're no longer constrained by the limitations of pandas formats or even the Python runtime. This opens up a world of possibilities for faster, more efficient data processing.
This also lays the foundation for the future. To make lazy loading work, we had to convert the backends of all our no-code cells from Python to SQL so they could issue DuckDB queries. All our cells now have their operations written in HexQL, an internal DSL that we can translate to DuckDB and other SQL dialects at runtime using sqlglot. This allows us to represent complex operations in a way that can be efficiently executed by our system, even skipping DuckDB entirely and pushing operations down into customer warehouses where appropriate.
We're excited for what's next – and can't wait to see what you do (and how fast you do it!) with Hex.