


Recursion Pharmaceuticals’ mission is to decode biology to radically improve lives. Their multi-disciplinary teams are working to bring safe and effective new medicine for cancer and other diseases by challenging assumptions and convention.
One of Recursion’s differentiators is its emphasis on bringing efficiency to the drug discovery process. To go from an idea to a molecule that’s actually helping patients usually takes about seven years — and that’s if there’s no mishaps. A tagline on their website reads, “Drug discovery should be about helping patients, not developing patience,” and the data team is central to this mindset. Their efficiency with data directly increases efficiency with drug discovery.
They paused and noticed that data output was being slowed down due to tooling, like static Jupyter notebooks and Excel spreadsheets. So they entirely reconstructed their process and tooling (adding Hex) which helped Recursion go from a huge world of drug discovery to faster testing for success. Here’s how they did it.
Scientists, engineers, and leadership all need access to different types of data
Recursion manages fifty petabytes(!) of data. It all sits in a data backend referred to as the Comprehensive Map of Biology, and it houses approximately 6 trillion+ relationships between biological entities.
To discover new drugs, many multi-disciplinary teams all need to be able to access data from this backend. The idea is that chemists, software engineers, biologists, and leadership can all query different types of data (pictures of cells, cell types, different genes, proteins, chemical perturbations) from the same place to make new insights that could turn into novel drug discovery programs.
Having the data all in one place was working, but the workflow of accessing this data to build experiments and then reports for decisions, was slowing down. Recursion's data team was getting too in-the-weeds on specialized information and data tools were being stretched to execute on tasks that they weren’t built for.
Before: Original data delivery required data scientists to be intermediaries
In Recursion's original data process, data scientists found themselves caught between scientists and leadership. Biologists and chemists generated experiments and data on one side, while leadership received reports on the other to make key decisions.
Data scientists acted as intermediaries, interpreting complex experimental data from scientists (which required a deep understanding of biological systems) and transforming it into reports for business leaders to make crucial decisions.
In this flow however, the data team was getting pulled in to participate in the idea-and-experiment part of the process driven by science teams and then responding to report iterations from leadership. The time and expertise required to deliver on bespoke requests began to be directly at odds with scaling.
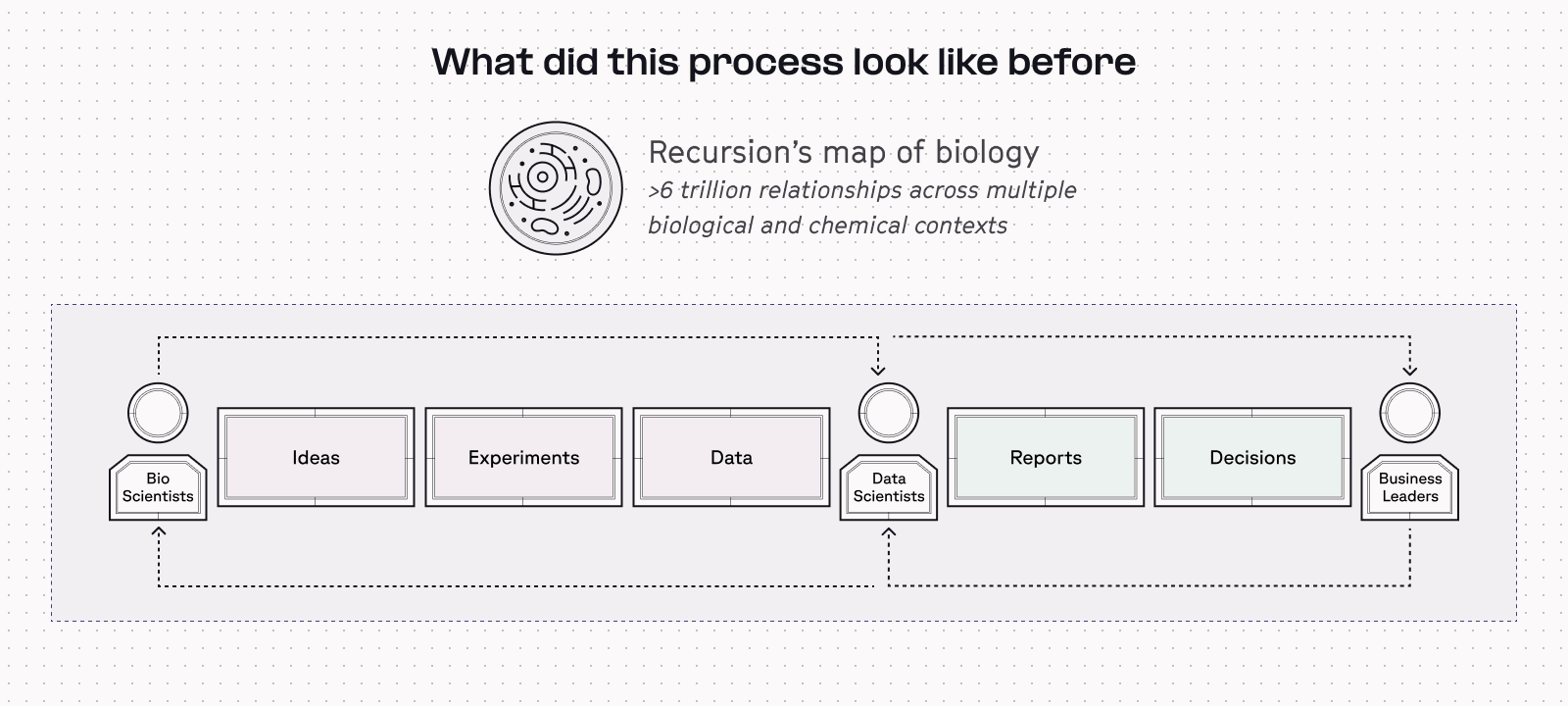
Last year, these types of pipelines (as pictured in the image above) began to multiply across Recursion. And although each disease program's data process looked similar, no two were exactly the same. Each specific program created more convoluted processes, which meant that data scientists were gaining more expertise in interacting with specific forms of data, rather than data more broadly at the company.
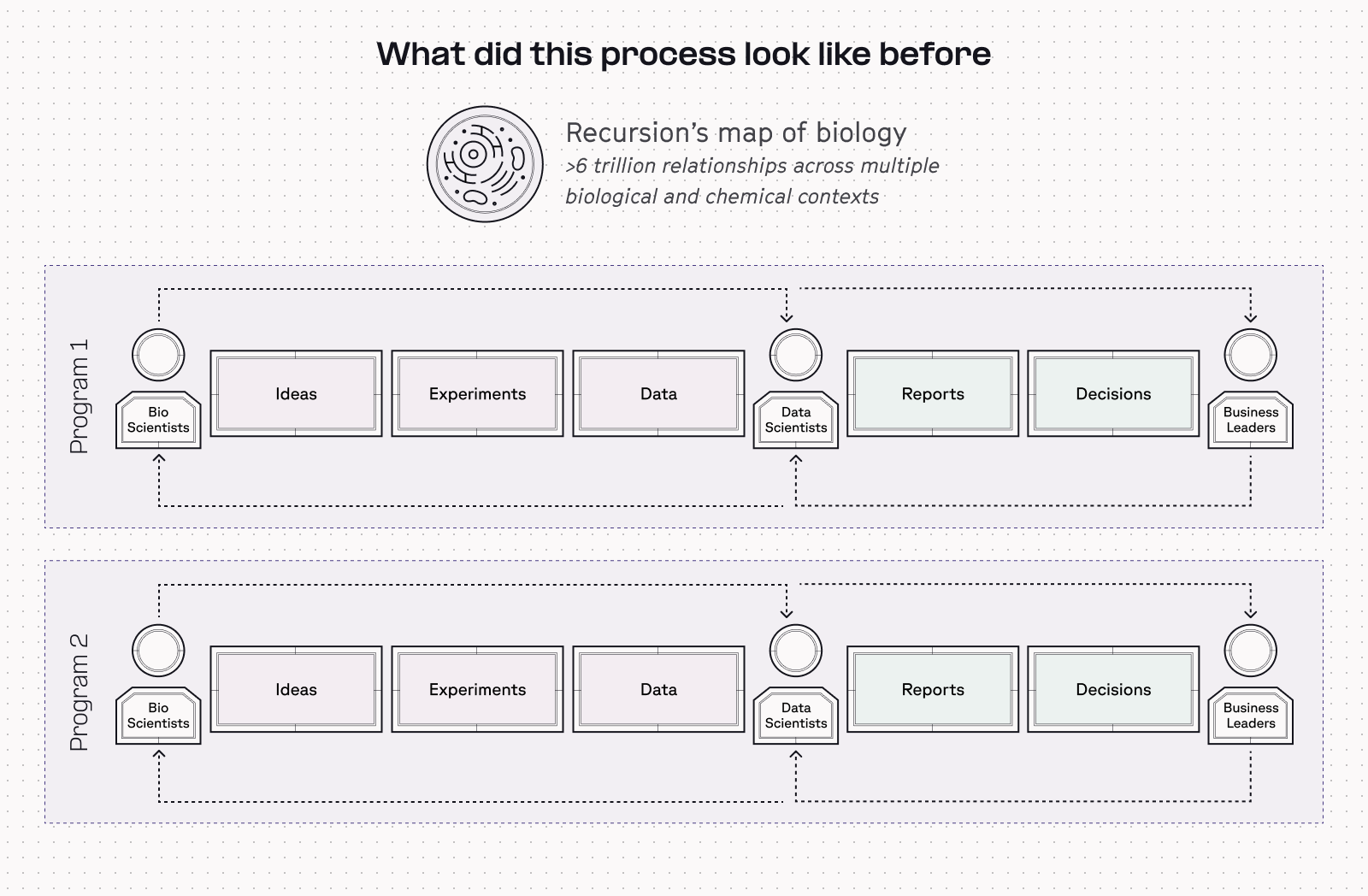
“Last year, we really sat down and said, this isn't going to work if we want to continue to drive drug discovery,” Jacob Cooper, Senior Data Scientist at Recursion, remembers.
With this workflow, Recursion would need to add more headcount to increase data delivery at scale. Instead, they entirely rethought their end-to-end data process.
They did this with two major initiatives: 1) making drug discovery steps into a scalable data loop (instead of a horizontal pipeline) and 2) decoupling data processing from the last-mile delivery of data work.
After: A new data workflow for drug discovery at scale
Over the last year, Recursion’s data team has been building a new workflow that they call the “Industrialized Workflow Platform,” which brings together multi-disciplinary data in ways that couldn't be scaled without adding more headcount.
Specifically, this new process and architecture allows:
- Many multi-disciplinary teams access to the specific data they need
- A centralized way to link the data to drive decisions
Moving from pipelines to a scalable loop
This structure transforms the data-to-answer workflow from a horizontal, back-and-forth process to a scalable loop, removing data teams from being in the middle of science and leadership teams. This new data workflow drives decisions that are much more holistic and much less team specific, across the entire company.
How it works
On one side, there is now a collaborative effort between all the human parts of the system.
Bioscientists, data scientists, and business leaders come together to ask the broader program questions: What makes a good drug discovery program abstractly? What are the things that we need to look for within our data? What are the things we need to look for in the wider medical literature?
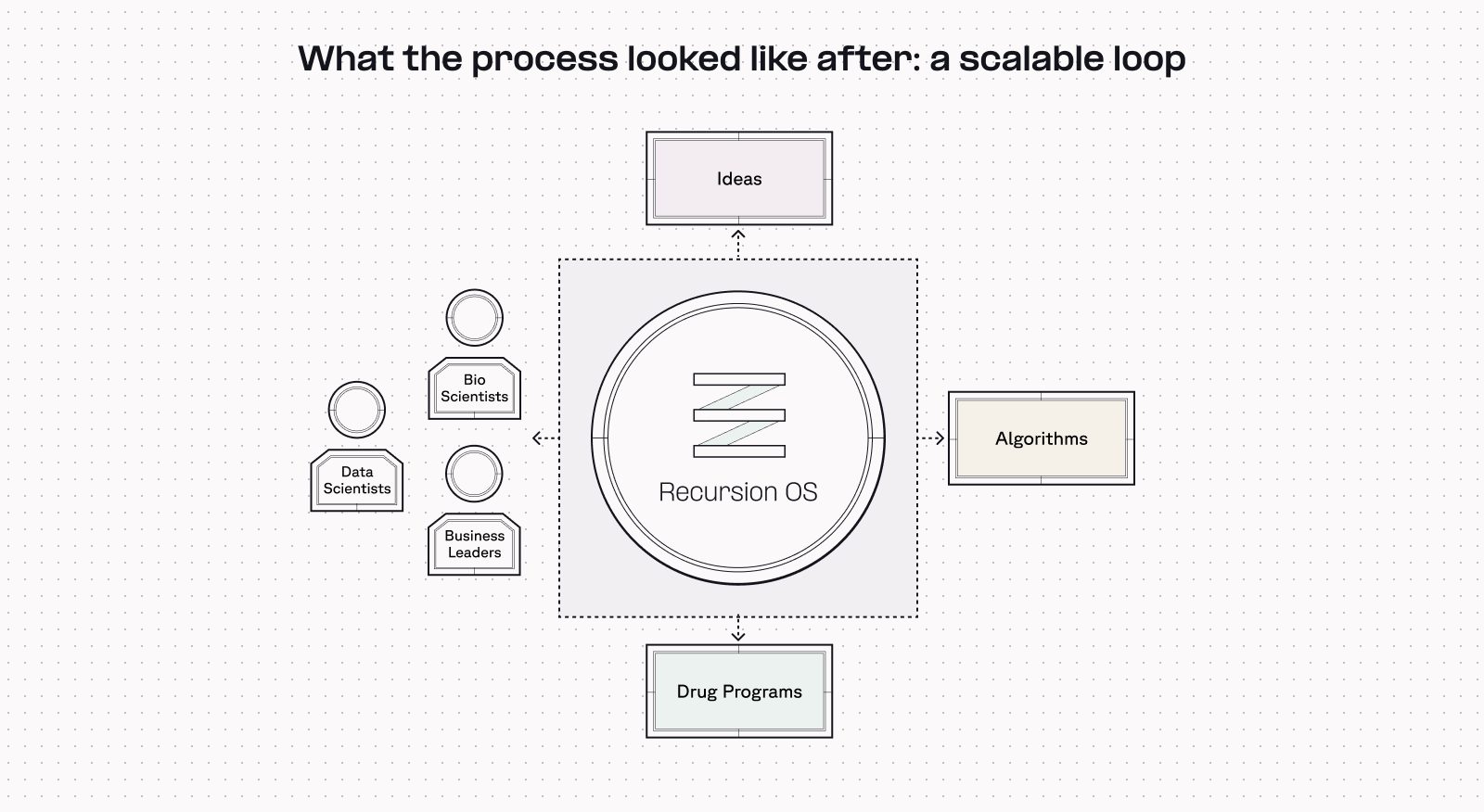
Recursion’s data and science teams then test ideas from those discussions, which in turn, generates drug programs that they evaluate for quality.
“This cycle is much more scalable because now you're able to deploy this process against any problem rather than needing to scale individual teams in order to solve new drug discovery problems,” Jacob said.
What does the architecture look like behind the scalable loop?
Recursion’s drug discovery platform is powered by a supercomputer called BioHive — an in-house, custom-built computing solution built with Prefect and Google Kubernetes Engine.
Various data types are sent to centralized locations such as buckets or Postgres tables and then pulled together using BigQuery. Hex sits on top and is used for complex analysis, visualization, and last-mile delivery of multi-disciplinary data.
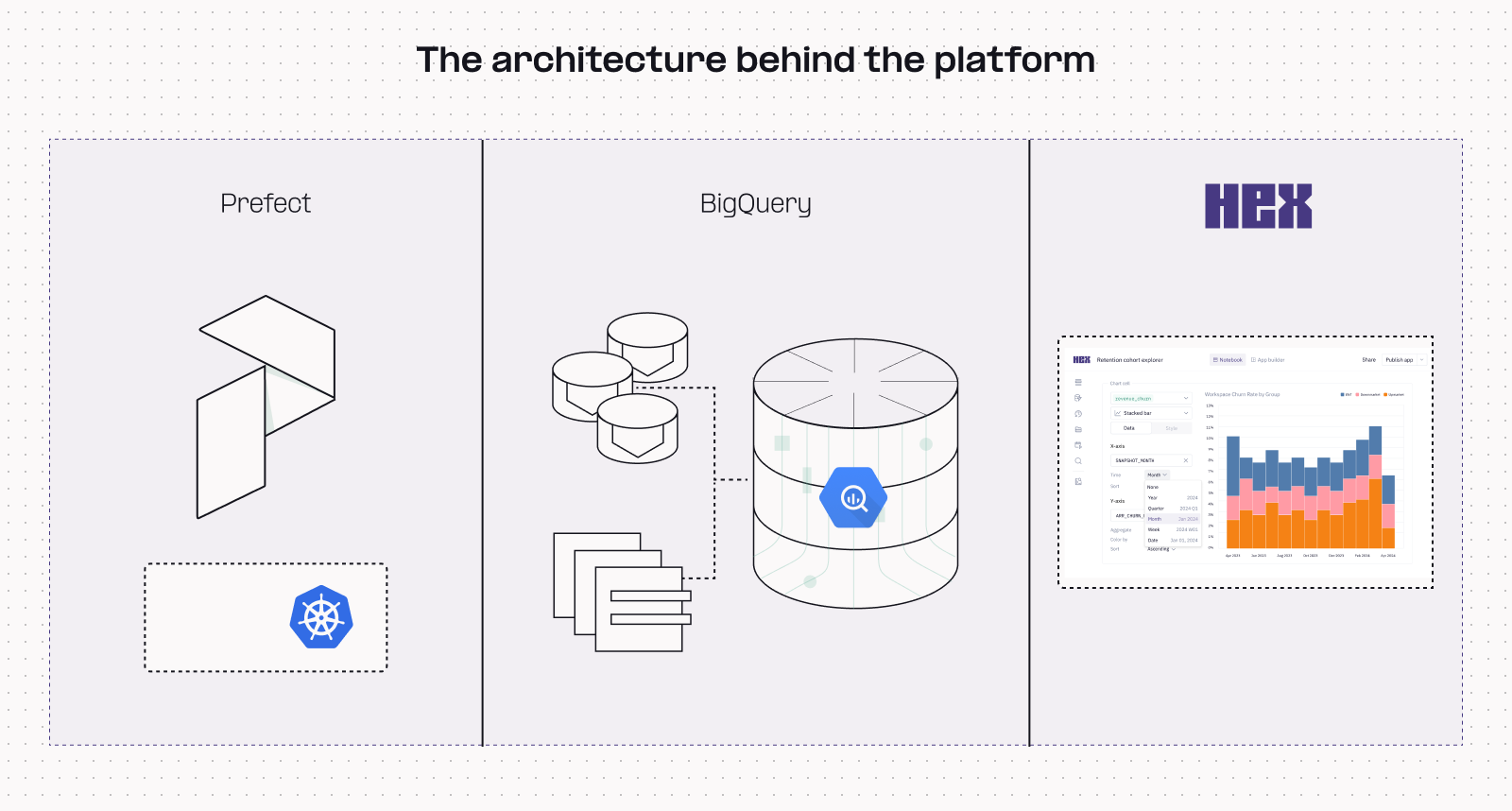
This hybrid architecture has two key components:
- It decouples processing from storage.
- It centralizes all different data types in BigQuery,
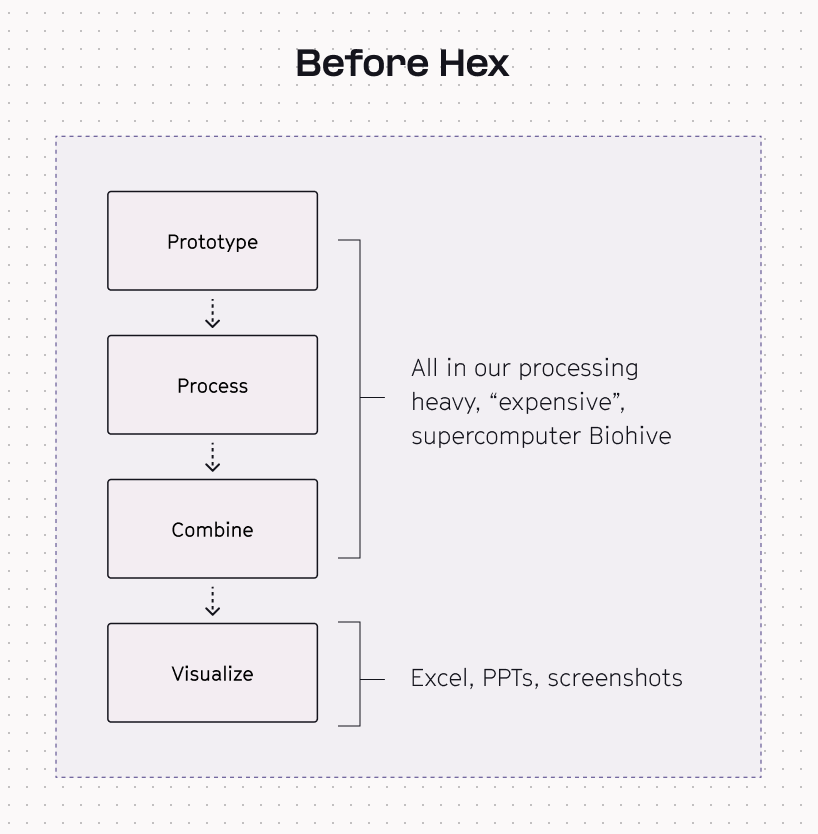
Before Hex, the end-to-end data process ran out of Recursion’s supercomputer
Originally, all of the steps of prototyping, processing, combining and visualization had to happen in messy notebooks and random scripts that they would deploy to the supercomputer. The problem is that the supercomputer is hard to use which limits the number of people who know how to use it and it’s computationally expensive for tasks like prototyping and combining.
More specifically, this led to:
- suboptimal processing pipelines because the data had to be output in very specific formats for consumption in brittle BI tools
- extra expensive supercompute to pivot and reshape the raw outputs to a shape that Excel or Powerpoint or their dashboarding tools could consume.
Now, Recursion prototypes easily in Hex, offloads processing to the Biohive supercompter or Kubernetes, and then switches back to Hex to easily combine and visualize the messy results back in Hex.
Hex is flexible and powerful enough to work on top of the raw data outputs from the supercomputer no matter what they look like. Visualization can also live in Hex, which is a cheaper, multidisciplinary tool that provides democratized access.
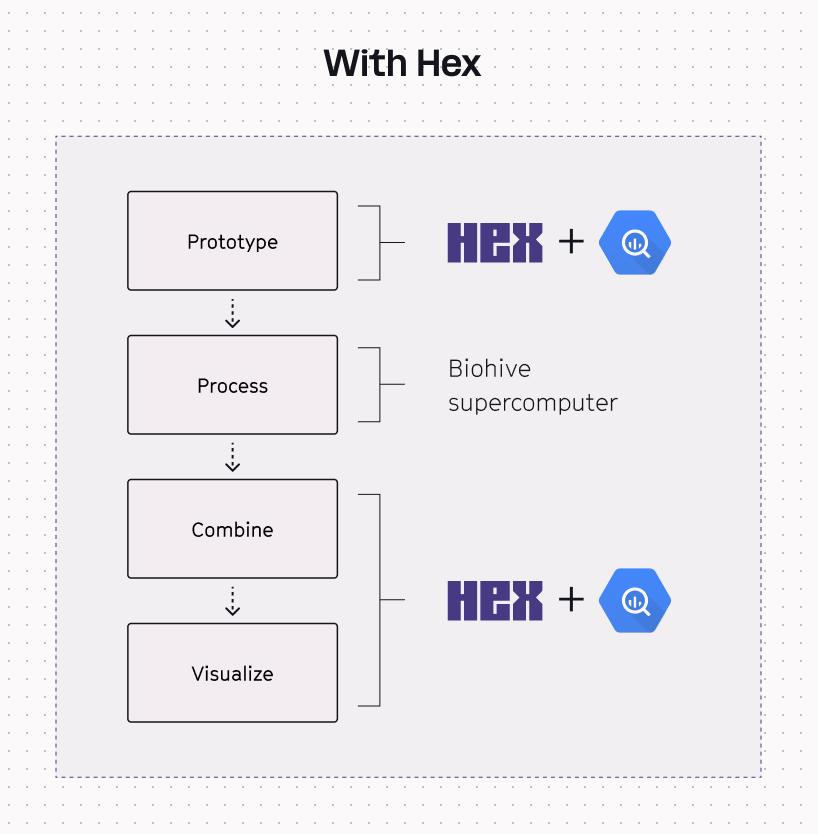
By offloading just the data processing into the Biohive supercomputer, Recursion can then have specialized teams that focus solely on making the prototyping efficient, on making data processing efficient, and on the data visualization efficient. This specialization boosts overall operations.
And Recursion’s leadership team now uses interactive data apps and reports built in Hex, which gives them the ability to explore and answer more questions for themselves — short circuiting and entirely preventing the need to re-run slow, expensive data pipelines.
“This ends up being a lot more efficient than the system that we had before, because it accommodates for scale of teams,” Jacob said.
Recursion is now able to make more holistic decisions, more efficiently
With this new system, Recursion has developed a new culture of collaboration across data scientists, chemists, software engineers, and leadership. The shared understanding of data processes and unified data architecture allow different experts to work together smoothly, helping the company make better progress in drug discovery.
“We now have a centralized platform for our scientists, data scientists, and technical leaders to look across all of these different modules and start to drive decisions that are much more holistic.”
They also refocused their tools to perform the tasks they excel at: the supercomputer handles its large-scale data processing and Hex makes it easy to visualize and analyze messy data and create interactive data assets and reports in a central place.
When you’re operating at this level of scale both at the raw data level (50PB!) and the team level (lots of diseases to cure!) you can’t afford to have tools and processes that slow things down.
With Hex, the steps of prototyping, combination and visualization became much more efficient, cost-effective, and more centralized.
If this is is interesting, click below to get started, or to check out opportunities to join our team.