Blog
How to build a sentiment analysis model in Python
Learn how to classify the sentiment in a body of text

What is sentiment analysis 🤔
Sentiment analysis is a natural language processing (NLP) technique that aims to detect/extract the tone or feeling from a body of text. Usually, sentiment is classified as being positive, negative, or neutral which gives us a measure of "the level of satisfaction." However, it can easily be used to classify emotion, intention, and even predict user ratings.
Say you're an analyst for a company called Apricot™ that sells high end computers. It's a Monday and your boss tells you to go through every review ever written about the company and wants you to create a report that showcases the overall satisfaction of your customer base. Having over 50k customer reviews, you wonder how you will ever be able to achieve such a feat! Luckily, you have plenty of data scientist friends to go to for guidance and most of them suggest that you use a sentiment analysis model, however, you have no idea what that is or how it works.
Your lovely data scientist friends wrote you a tutorial to walk you through all of the conceptual and technical aspects of using a sentiment analysis model so that you can make your boss happy. Let's get started!
from transformers import pipeline
import pandas as pd
import numpy as np
import re
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from wordcloud import WordCloud
from wordcloud import STOPWORDS
from collections import Counter
from sklearn.metrics import accuracy_scorePretrained models with Huggingface 🤗
In machine learning there is a concept called transfer learning -- which in short, means using a pre-trained model as the starting point for another task. Huggingface is a platform that provides access to thousands of these models so that you don't need to spend time and resources creating models from scratch. They provide over 200 sentiment analysis models that you can download from the hub and getting started with them only takes a few lines of code.
model = pipeline(model = "nlptown/bert-base-multilingual-uncased-sentiment")The model that we're using is a BERT model finetuned for sentiment analysis tasks. For context, BERT is a model that achieves state of the art results on most language tasks. Being a transformer (no, not the car 😔 ), its structure is fundamentally different from the neural networks previously used for language modeling by adding what's known as attention. Without getting to deep into it, attention allows the model to give more weight to the parts of text that are most relevant/important. How does it do this, you ask?? Math.
Dataset 📊
The data comes from Kaggle and consists of over 65k cell phone reviews from different companies. The dataset is split into two tables so we will load both of them and join them together to get our "main" dataset.
reviews = pd.read_csv('reviews.csv')
# rename body to reviews
reviews.rename({'body':'review'}, axis = 1, inplace = True)
items = pd.read_csv('items.csv')
select brand, R.rating, review from reviews as R
join items as I on R.asin = I.asinPreprocess data 🔄
Now that we've got our full dataset, some preprocessing is required to prepare our review data for our sentiment analysis model.
The first thing we're going to do is drop all of the rows where there isn't a valid review or company name present.
dataset = df.dropna(subset = ['brand', 'review'])The model expects each body of text to be at most 128 characters, so we'll reduce our dataset to only include reviews with a word count of 128 or less. We also find that there are a lot of rows where the brand name is repeated multiple times before observing a different brand. This may lead to selecting reviews from only a few brands and not the others. Therefore, we'll shuffle our dataset to introduce a bit of randomness.
# filter the dataset to reviews with 128 characters or less
dataset['token_count'] = dataset['review'].apply(lambda review: len(review.split()))
mask = dataset['token_count'] < 128
dataset = dataset.loc[mask]
subset = shuffle(dataset, random_state = 444)[1000:1500]
Predicting sentiment 😄😐🙁
Now that we've got our dataset in a good state, all we need to do is pass our list of reviews to our sentiment model to obtain our predicted ratings.
reviews = subset['review'].tolist()
# ratings = model(reviews, truncation = True) # This can take up to 2 minutes so we are going to load the predicted ratings from a file
ratings = pd.read_csv('ratings.csv').to_dict(orient = 'records')The predicted ratings returned from our model are given to us as a list of dictionaries, like the following:
[{'label': '2 stars', 'score': 0.4741453528404236}]The following cell will extract both the label and the score for each prediction which we can use to add new columns to our dataframe.
predicted_rating = [int(r['label'][0]) for r in ratings]
rating_confidence = [round(r['score'] * 100, 2) for r in ratings]
subset['predicted_rating'] = predicted_rating
subset['rating_confidence'] = rating_confidence
subset = subset[['brand', 'review', 'rating', 'predicted_rating','rating_confidence']]Results ✅
Let's see how well our model does at predicting sentiment as well as how we can use the predictions to learn something about customer satisfaction for each company.
Since our original dataset contains the actual rating for each review, we can calculate an accuracy score to get an idea of how well our model performed. We have also created a way to convert our star ratings into sentiment labels.
- Negative: A rating of 1 or 2
- Neutral: A rating of 3
- Positive: A rating of 4 or 5
labeler = {
1: 'negative',
2: 'negative',
3: 'neutral',
4: 'positive',
5: 'positive'
}
subset['sentiment'] = subset['predicted_rating'].apply(lambda rating: labeler[rating])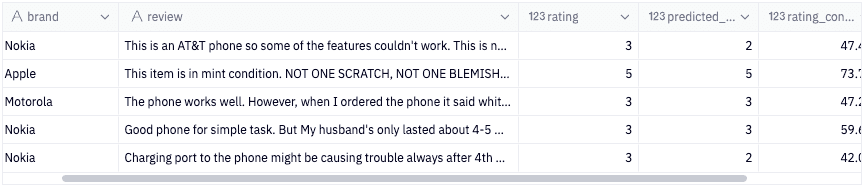
In terms of model performance, the score on the top is the model's accuracy score for predicting the actual review rating. The score on the bottom is the model's accuracy score for predicting overall sentiment.

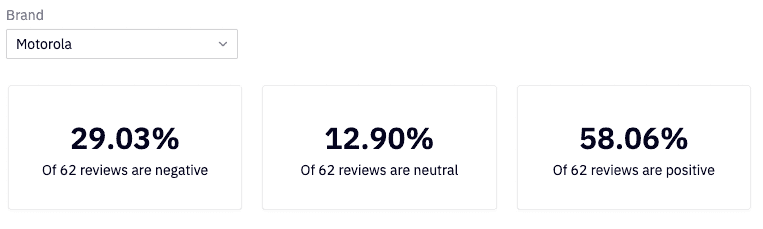
Now, we can use the results of our model to create a report that showcases the percentage of each sentiment category for all reviews for each company.
Note: Although this is a good way to measure performance per company, it is not a good method for understanding how one company may compare to others as there aren't an equal number of observations for each.
Lastly, we can create a word cloud visualization to give us and idea of the words commonly associated with each sentiment of category.

Conclusion 😌
Congratulations for making it to the end of this tutorial! Here's a cookie as a token of our appreciation 🍪. Today you learned:
- What sentiment analysis is
- What a pre-trained model is
- How to use a pre-trained model for sentiment analysis
We just barely scratched the surface with what pre-trained models can do as well as the applications for sentiment analysis. If interested in going deeper, we suggest looking more into the following topics.
- Fine-tuning pre-trained models (to re-train your own models with less data!)
- Emotion detection
This article was influenced by the sentiment analysis article on the Huggingface website.