
When I started my career, data analysis was mostly done in spreadsheets, and it was a mess.
Our "data team" didn't have real tools for extraction, transformation, quality, and storage. I remember vividly how we got source data updates: every Monday Alex, the only one with database access, would dump tables to CSVs and distribute them on a passed-around thumb drive with a tests.xls file to check for quality issues (this felt sophisticated for the time).
Models were all built in Excel, using lots of nested functions across many tabs with some VBA sprinkled on top. The logic was brittle, tough to debug, and crushed our CPUs every time we re-ran.
Sharing our work was equally clunky: we could email our spreadsheets (if under the attachment size limit!) but had to be careful not to link workbooks. Our team built a lot of slide decks and reports, but the charts and tables were static screenshots, severed from the underlying data.
We archived everything in a networked share drive with cryptic filenames like MXFleet_Model_01_24_2011_v3_JG_edits.xlsm 1. Versioning and finding your work – much less anyone else's – was tough.

In the 10 years since, some things have changed
Data teams have gone from the back-office (or non-existent) to a critical function, often reporting to the CEO. There are thousands of professional Data Scientists, Analysts, and Engineers working within organizations that are looking to them to drive results.
Pipelining and access have gotten way better. A wave of new platforms for data extraction, transformation, quality, metrics and warehousing have made it easier to serve up timely, reliable data. Modern BI tools have made it possible for business users to self-serve and build dashboards – no more going to Alex to get the share drive!
For more intensive work, languages like SQL and Python, alongside applications like Jupyter, have become wide-spread on Data teams. These offer a massive improvement in power and flexibility over spreadsheet logic.
And yet, when I see how these teams collaborate on and communicate their work, I have
flashbacks to the old days. Static slide decks? Cluttered share drives? Pasting updated_chart_2.png into a chat window? Are we really still doing this?
It doesn't feel like data sharing workflows have kept pace with the rest of the stack.
Back to the future
I felt this pain not-so-long ago, when a Data team I worked with replaced a brittle, multi-tab, macro'd-to-death forecast spreadsheet with a Python notebook. It was way better, technically. The code queried directly from the database, ran super fast, and had really nice charts.
But, unlike with the spreadsheet, no one in the business could use this wonderful notebook. So, every time a stakeholder wanted to see a different scenario, it fell on an analyst to re-run the logic, export the results to a PDF, and send via email. Not only was this more work for the Data team, but each iteration of the model was locked in a one-off file, adrift in a share drive. The move from Excel to Python actually made it worse for everyone involved.
This is an under-appreciated reason spreadsheets are so sticky, despite a wealth of resources and evangelism for transitioning to code-based workflows. Even for those curious and motivated enough to learn something like Python, it's hard to see the end game of embracing it at work. You can build something powerful, but is it useful if no one can use it?
The Sharing Gap
At least things were simpler in 2010. Then as now, spreadsheets are the true universal format for data: anyone can open them, look at the logic, comment on cells, etc. If you do your work in a .xls, you can be confident that everyone can use it.
The same is not true if you work in a .ipynb, though. A minority of people in an organization know how to open a notebook file, and those that do aren't guaranteed to have the right environment, database credentials, or package versions. So if you're doing intensive data analysis work, you find yourself back to sending static screenshots and slides.
This is a shame, because sharing is more important than ever. Data teams are being asked to do a lot, from building forecasts to structuring experiments. Being able to communicate their work with stakeholders, leadership, and customers is critical to feeling valuable.
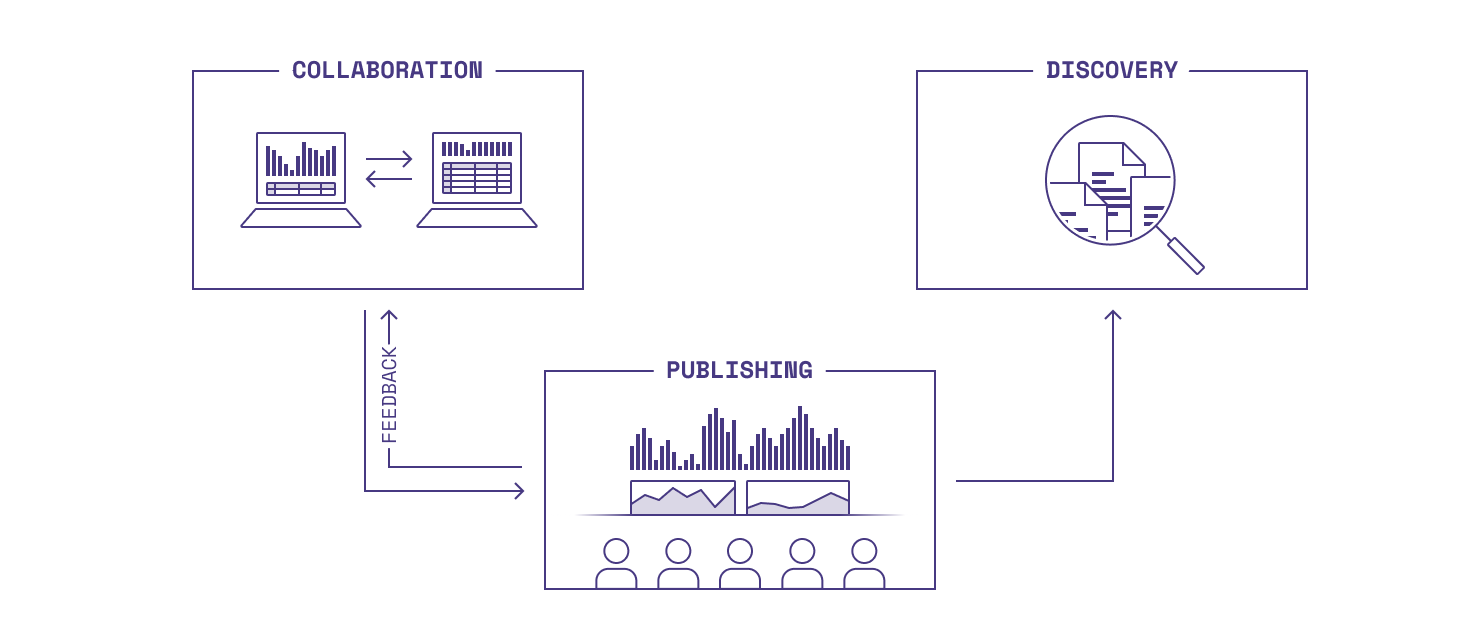
The "sharing gap" exists across all three modes of sharing for analytical work:
Collaboration: creator ←→ creator workflows, e.g., multiple Data Scientists partnering on a model or reviewing each other's work. Modern data tools address this through real-time multiplayer, integrated version control, and portable file formats.
Publishing: creator → consumer workflows, e.g., an analyst sharing a report with the marketing team. There's lots of room for improvement here. Today, publishing is mainly done through static, severed artifacts like PDFs and decks. Most data tools also ignore the consumer ↺ creator feedback loop, but products in other spaces, like Figma, illustrate interesting possibilities.
Discovery: knowledge organization workflows, i.e., an analyst searching to find results of previous experiments. This, too is an under-invested space; most teams I know just throw stuff in Google Drive (or use GitHub in basically the same way).
Where this is going
There has been a lot of progress in the last 10 years, but in many ways it feels like just the beginning. While no one knows what the next decade holds, we believe that closing the Sharing Gap will be a critical step to unlock the value of data and data teams.
This is why we are building Hex, a platform that makes sharing your work easier, more powerful, and fun. With Hex, you can import or build Python and SQL-powered notebooks, collaborate with colleagues, publish your work as an interactive app, and discover existing analyses from across your organization.
If this is interesting for you, sign up below to get early access, or reach out directly at the email below. We're going to be sharing much more soon.