Blog
A look under the hood of Snowpark
Dive into the workings of Snowpark and how it pertains to Hex's Snowpark integration

Snowpark has brought the world of data engineering pipelines and machine learning into Snowflake. Its initial release focused more so on data engineering pipelines and with the release of Snowpark ML we now have an end-to-end ML experience. This has provided capabilities down stream in terms of data ingestion up to the advanced use cases around ML development.
But, what about the work loads in between, such as ad-hoc analytics, visualizations, exploratory data analysis (EDA), and just getting answers to those pesky business questions? This blog will focus on those types of workloads and how we can harness the power of Snowpark in Hex. We will be exploring what Snowpark commands look like in Snowflake and how Hex’s integration tailors to not just the data engineering and machine learning use case, but also everything in between.
This blog assumes that you have a basic understanding of what Snowpark is. If you would like a refresher or an introduction to Snowpark give Snowpark Is Your Data Librarian a read. We’ll start by exploring Snowpark Queries and Hex’s Snowpark integration in detail.
Unwrapping Snowpark Queries:
If you are reading this blog, you probably have some familiarity or at least a desire to learn more about Snowpark dataframes. In this section, I want to dive deep into the query profile of a simple snowpark query and see how it is being processed in Snowflake.
Let’s start with a simple query using Hex and I’ll make sure to ask for a Snowpark dataframe:
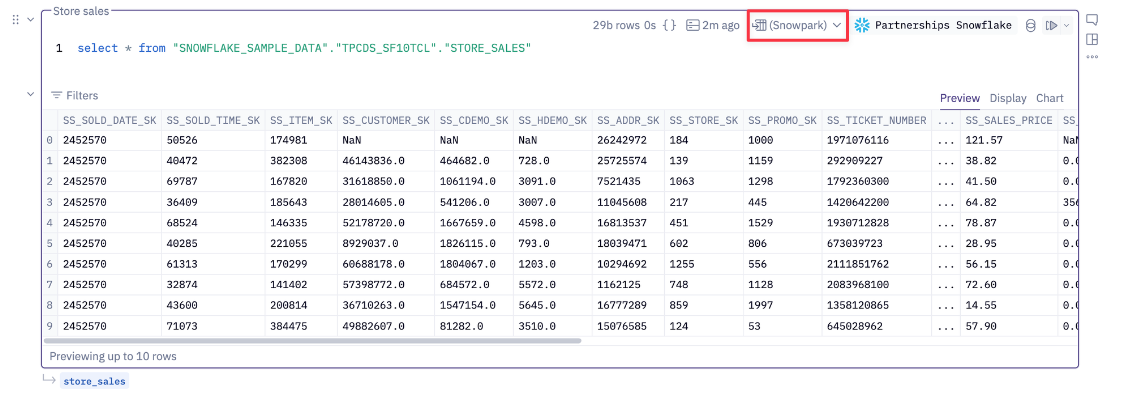
Under the hood Hex passes the following Snowpark query since I requested a Snowpark dataframe:
session.sql('select * from SNOWFLAKE_SAMPLE_DATA.TPCDS_SF10TCL.STORE_SALES').show()This is a glimpse at how Hex provides users the ability to use native SQL cells while still working with Snowpark dataframes. From a native SQL cell in Snowpark return mode, Hex will construct the Snowpark code on your behalf. I’ll also run the Snowpark code in a python cell just so we can see that the query is the same.

Let’s continue this exploration and find the two queries above from the SQL cell in Snowflake find this
From Hex’s Native SQL Cell:
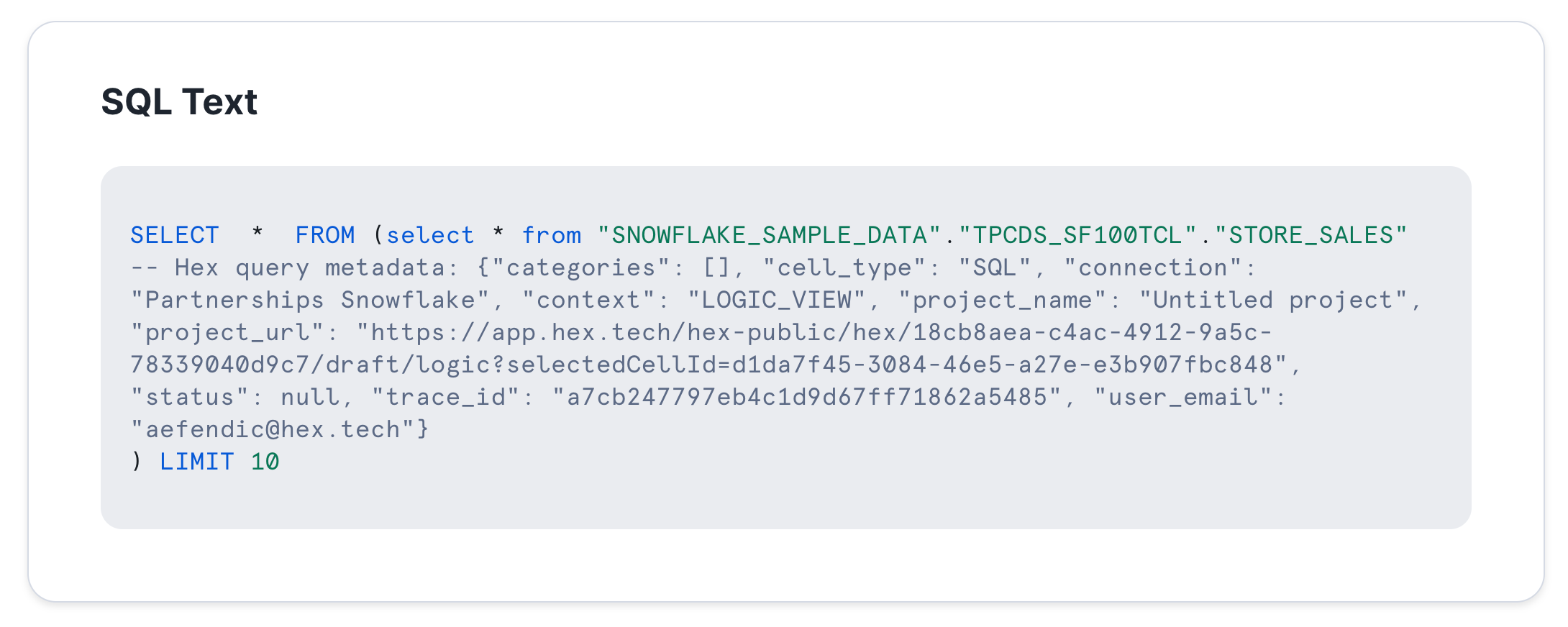
Hex adds metadata for queries coming from a SQL cell so its easy for me to identify where the query is coming from.
From the Python cell using pure Snowpark code:
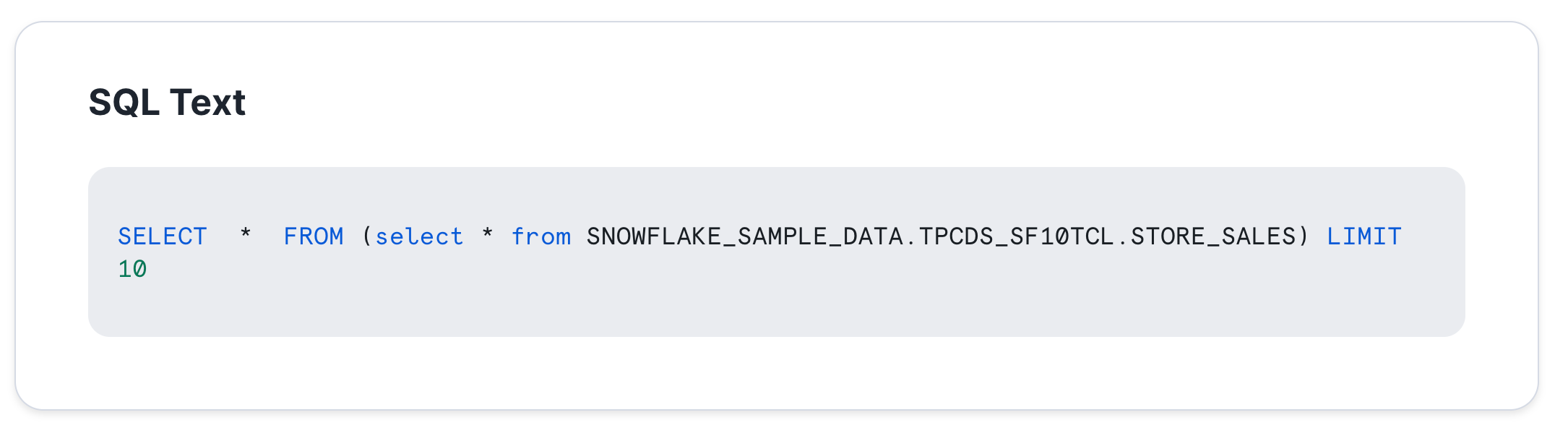
Notice it is the exact same query just without the metadata.
Both queries above employ lazy evaluation and show a preview of the data via the LIMIT 10 clause. .show() can also be referred to as an action call. I take the reference to the query and ask that an action takes place, meaning the query is run. In this case, only 10 rows are scanned. You can run .collect() and this brings the entire dataset to memory and performs as a regular select * query would. Use caution with this as it can cause an expensive query and even use all of your memory in a Hex project.
Let's explore the Query Profile of the query made from the Hex native SQL cell from above:
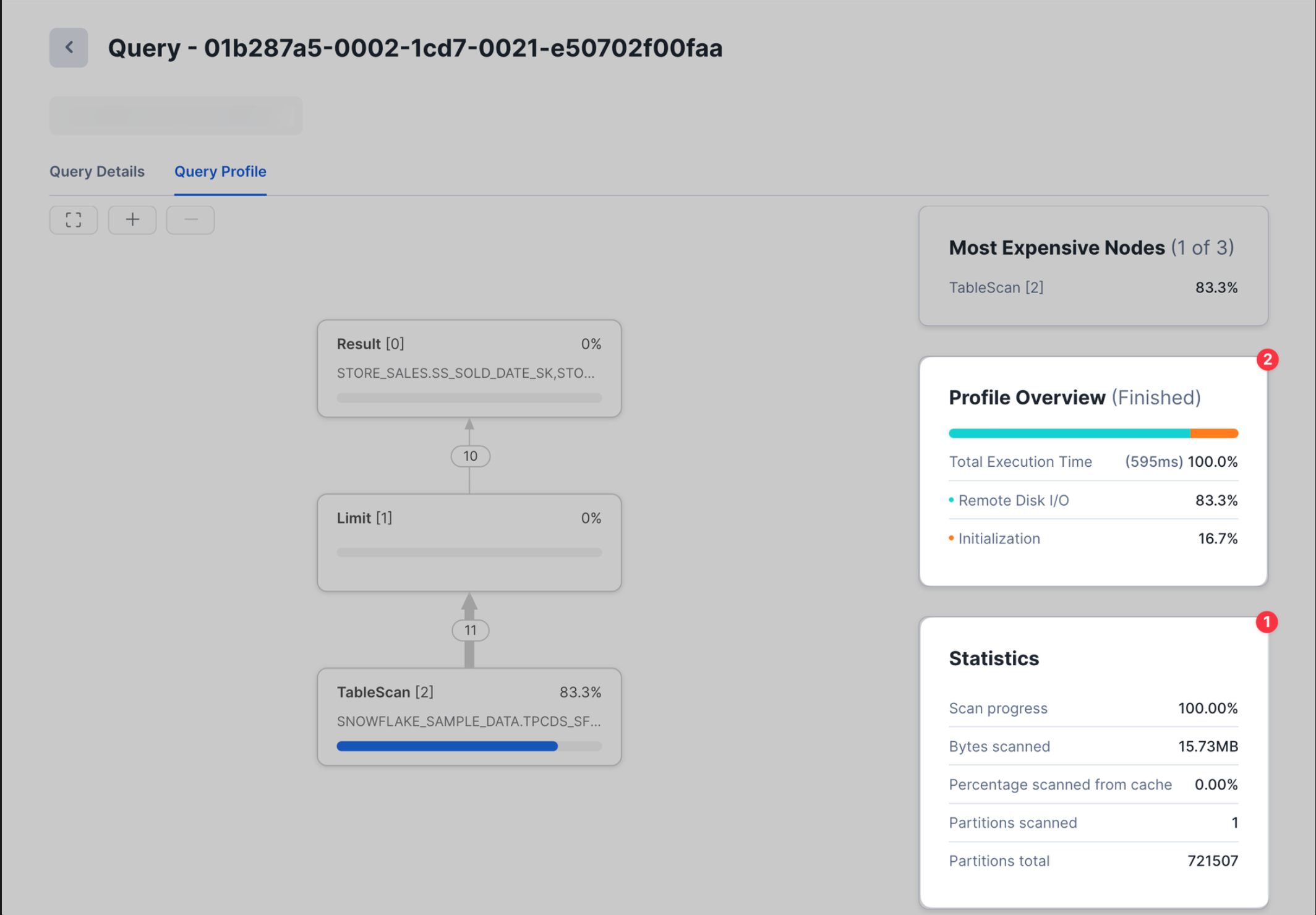
- Notice that with the Snowpark query only 1 partition is scanned even though our query performed a select star with no limit clause in Hex. Under the hood, Hex constructs the appropriate Snowpark query like we saw above.
- We didn’t hit any Snowflake result cache as this was our first query but this still only took ~600ms
- The vast majority of the query was the Remote Disk I/O which was the reading of data
- Since this result will now be cached as our result cache, subsequent runs will hit the result cache, otherwise known as Query Result Reuse
This is at the core of what makes working with Snowpark dataframes so powerful and is a concept called lazy evaluation. Hex utilizes this, by providing previews of your data in a native experience without actually bringing all the data into Hex. We only bring in a preview of the data, and in most cases its just 10 rows.
You might ask, why is this helpful - particularly with those use cases in between data engineering and machine learning. Let’s revisit the example query from above, the table contains 29 billion rows of data. Performing any sort of analysis on that size of data in traditional notebooks, let alone in a SQL cell, is impossible and requires other tooling like Spark. This means your entire data set now has to be moved to another platform just to start analyzing it. With Hex’s Snowpark integration this becomes incredibly easy.
Let’s take a simple example of a null check of our customer column, SS_CUSTOMER_SK from store_sales. Better yet, I will use Hex Magic to write the Snowpark query for me in Python:
Let’s see what this query translates to in Snowflake:
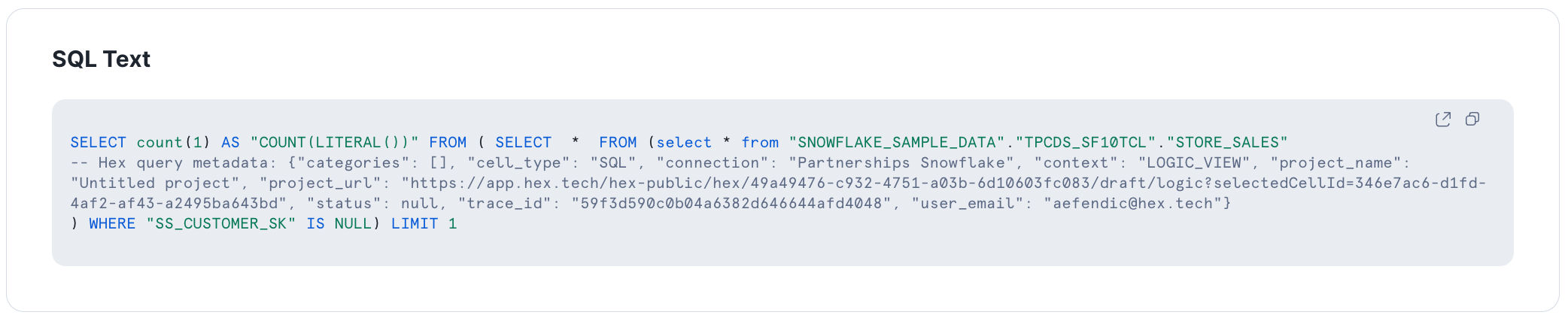
Notice the same metadata is passed to the snowflake query since we called store_sales. This ability to switch between different cell types is all managed for you by Hex. We even support visual cells like charts, where the aggregation is completed in Snowflake and only the result set is brought back to Hex.
Conclusion:
In summary, Snowpark frees data scientists from memory constraints. Hex’s integration enables users of all skill levels to work with Snowpark. Whether you want to join tables with SQL, calculate a moving average with Python, and then visualize the result - all can be done in Hex while seamlessly leveraging a Snowpark dataframe! You can also rely on using Hex Magic in Python and SQL cells to help fix pesky bugs and even self-train on Snowpark syntax.
At the end of the day, its all about getting value out of your data and here at Hex we believe the tools used should never limit you but rather accelerate the work that you can do.
If this is is interesting, click below to get started, or to check out opportunities to join our team.