Blog
Intro to cohort analysis in Python
Analyze groups of customers to understand retention, predict churn, and find other patterns

What is cohort analysis?
Say you own an online clothing store and you want to learn more about the behavior of your customers. One way you can do this is to define metrics that summarize and capture how customers engage with your store. Of the many metrics that you could define to summarize engagement, a common one is customer retention. Customer retention is derived by tracking how and when people first engage with a product compared to their subsequent engagement.
Keeping this metric in mind, we need to split your customers up into groups or cohorts. A cohort is a group of people who share something in common. In this case, we'll define a cohort as customers who have made their first purchase within the same month. This means that everyone who made an initial purchase in May belongs to the May cohort, everyone who made a first purchase in June belongs to the June cohort, and so on.
In this tutorial, you will learn how you can use these cohorts to ask more specific, targeted questions about how different sets of customer behave after they've started shopping with you. Without further ado, let's get started!
First, we'll import all of the packages required for this analysis.
import pandas as pd
import matplotlib.pyplot as pltimport warnings
import seaborn as snsfrom operator
import attrgetter
import matplotlib.colors as mcolors
import numpy as np
import calendar
The dataset 📊
The data we will be using is e-commerce data that can be downloaded from Kaggle. The original dataset can be found here, but the version that we'll be using has updated dates and no null values.
data = pd.read_csv('retail.csv',
parse_dates=['InvoiceDate'],
dtype={'CustomerID': str,
'InvoiceID': str})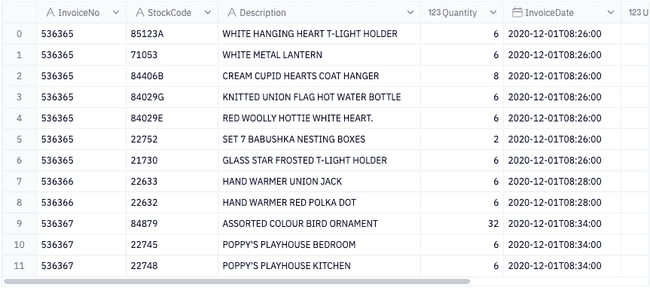
Exploratory data analysis 🗺
Next, we'll do some light exploratory data analysis (EDA) by calculating the number of orders per customer and the rate at which customers make more than a single purchase.
# get the total number of ordersn_orders = data.groupby("CustomerID").nunique()
# count the customers who've made more than one ordermore_than_one_order = int( np.sum(n_orders["InvoiceNo"] > 1) / data["CustomerID"].nunique() * 100)
# count the customers who've made more than 2 ordersmultiple_orders = int( np.sum(n_orders["InvoiceNo"] > 2) / data["CustomerID"].nunique() * 100)Here we find that 65% of customers ordered more than once and 46% have ordered more than twice. This is useful to know because it indicates that there will be noticeable retention across cohorts given that the majority of users are placing multiple orders. Let's visualize the distribution of orders using a histogram.
Creating cohorts 👥
Now we can start forming our cohorts. Remember, a cohort is just a way to group customers that share something in common. In this case, we're using the month of their first purchase. First, let's reduce our dataset to only include the most relevant columns.
data = data[['CustomerID', 'InvoiceNo', 'InvoiceDate', 'UnitPrice']].drop_duplicates()Next, we can create our cohorts by using the minimum (first) invoice date for each customer. Once we know the date of their first purchase, we can add another column that tells us the month of each of their subsequent purchases. This will tell us at which periods they make more purchases after their initial one.
For example, if I make the purchases on these dates:
- 04/02/2022
- 04/04/2022
- 05/03/2022
- 06/21/2022
Then my cohort month is 04/2022, however, my order months are 04/2022, 05/2022, and 06/2022. So I've made 4 purchases across 3 different periods.
# Indicates the cohort that a customer belongs to based on initial purchase date (using the transform method will return all of the original indices with the applied transformation)data['cohort'] = data.groupby('CustomerID')['InvoiceDate'].transform('min').dt.to_period('M')# Indicates the month that each customer has made a purchasedata['order_month'] = data['InvoiceDate'].dt.to_period('M')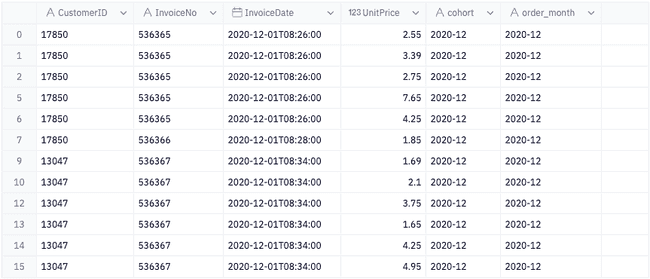
Now that we have a table with the initial purchase date and the month of each customer's order, we can aggregate the data for each cohort and order_month and count the number of unique customers in each group. Additionally, we add the period_number , which indicates the difference between the cohort date and the month of each individual purchase.
cohorts = (
data.groupby(["cohort", "order_month"])
.agg(n_customers=("CustomerID", "nunique"), total_spent=("UnitPrice", "sum"))
.reset_index(drop=False))cohorts["period_number"] = (cohorts["order_month"] - cohorts["cohort"])
.apply(attrgetter("n"))# Converts timestamps into calendar datescohorts["cohort"] = cohorts["cohort"].apply( lambda row: f"{calendar.month_abbr[int(str(row).split('-')[1])]} {str(row).split('-')[0]}")cohorts["order_month"] = cohorts["order_month"].apply( lambda row: f"{calendar.month_abbr[int(str(row).split('-')[1])]} {str(row).split('-')[0]}")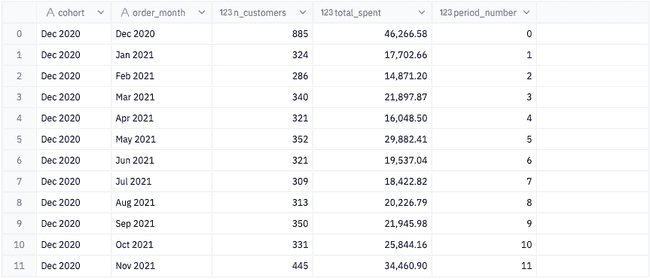
Now that we have our cohort data in long format, we can pivot our data to create our retention matrices. A retention matrix will show us how user activity changes over time for each of our cohorts.
retention_relative = cohorts.pivot_table( index="cohort", columns="period_number", values="n_customers", sort=False)# so that we preserve column ordercolumns = cohorts["order_month"].unique().tolist()retention_absolute = cohorts.pivot_table( index="cohort", columns="order_month", values="n_customers", sort=False)[columns]retention_price = cohorts.pivot_table( index="cohort", columns="period_number", values="total_spent", sort=False)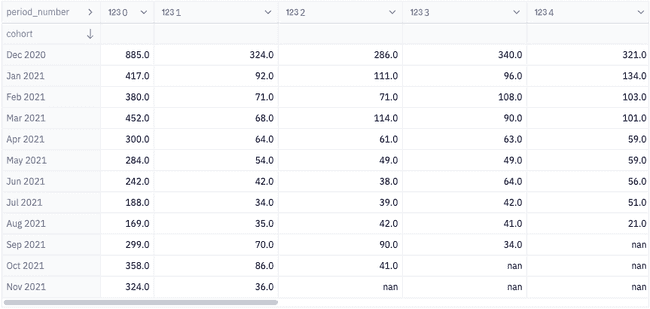
Visualizing cohorts 👀
In this last section, we will visualize each retention matrix to get an understanding of the overall retention for each cohort, patterns that may appear, and how each cohort compares to the other cohorts.
Below we've defined a function that will plot each matrix and format it for the metric we're hoping to understand.
- Relative retention
- Absolute retention
- Spending retention
You can easily translate between visualizing relative and absolute retention, just keep in mind that:
- The columns in the relative table map to the diagonals in the absolute table
- The diagonals in the relative table map to the columns in the absolute table
plot_retention(retention_relative, 'relative')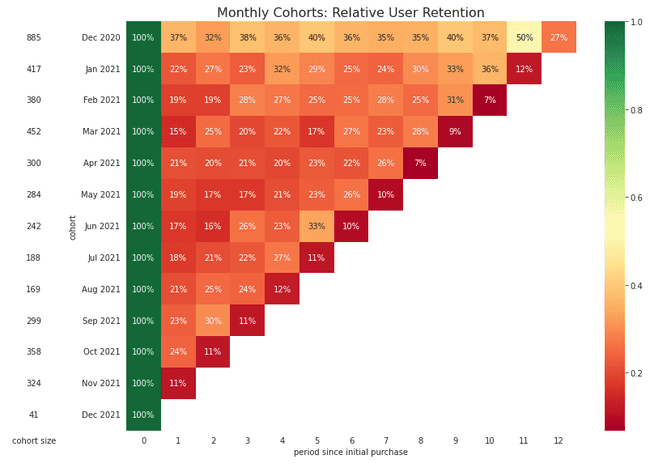
When looking at a relative retention matrix, each dimension represents something different. The rows show us how the activity of the cohort has changed as they all age from the period of their first purchase. The columns tell us how different cohorts compare to each other at the same relative "age" (e.g. periods since their first purchase). Finally, the diagonals on a relative retention matrix highlights each cohort's behavior in the same calendar month.
In the table above, we see an average retention of 20.62% in the first period across all cohorts. Also, if you look at the diagonal that represents the month of November 2021, we can see that there seems to be a slight uptick in purchases across cohorts. This could possibly be caused by customers coming back to do some holiday shopping.
The chart below is a slight variation, instead, showing how each cohort stacks up in the same calendar month. In this chart, the columns represent the activity for all cohorts in a given calendar month, which makes it easier to see how a specific time of year may impact the cohort. Only the oldest cohorts will have complete data for all months in this chart, as newer cohorts have not yet made their first purchase in the earliest months. For absolute cohort retention charts, the diagonals give us an idea of cohort activity at the same cohort age.
plot_retention(retention_absolute, 'absolute')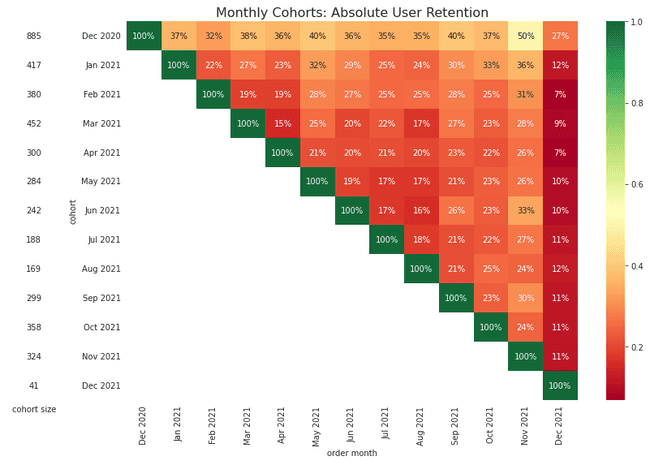
Next, we can visualize the activity of each cohort using line charts to get an alternate view of how the retention of one cohort compares to the others. Notice how there's a significant gap between the December cohort and all other cohorts. This shows that customers in the December cohort are retained at a much higher rate than any other cohort!
Conclusion
Welcome to the end and congrats on making it this far 🎉 ! Today you learned what cohort analysis is and how it can be useful for understanding the behavior of your customers. With your new understanding, you can easily tweak this tutorial to analyze cohorts based on different metrics or for different time periods.