
If you’re trying to go from this:
df.agg({
‘total_minutes’ : [‘sum’, ‘avg’],
‘night_minutes’ : [‘sum’, ‘min’]
})
.filter(state=’NY’)
.rename(columns={
"total_minutes_sum": "sum_minutes",
"total_minutes_avg": "avg_minutes",
"night_minutes_sum": "sum_night_minutes",
"night_minutes_min": "min_night_minutes"
}, errors=’raise’)To this:
SELECT
state,
SUM(total_minutes) AS sum_minutes,
AVG(total_minutes) AS avg_minutes,
SUM(night_minutes) AS sum_night_minutes,
MIN(night_minutes) AS min_night_minutes
FROM df
WHERE state = ‘NY’
GROUP BY 1Then you’re in the right place. We all love Python, but sometimes good old SQL is your best friend, even after you’ve gotten your data into a notebook: be it while you’re transforming data for a new training set or looking up the docs on matplotlib syntax for the 11th 4th time this week. This post will walk through 3 ways to query data in your Pandas DataFrame using SQL (well, technically 2.5, but trust us).
We’re assuming here that you’ve already got a Pandas DataFrame with your data ready to go.
Method 1: PandaSQL i.e. using SQLite to query Pandas DataFrames
Both major methods of querying your Pandas DF in SQL basically involve sneaking your Pandas data into a database (SQLite, in our case) and then using that DB’s flavor of SQL to query it. Our journey begins with the pandasql package, kindly developed by the now defunct Yhat team out of Brooklyn.
pandasql is a dead simple wrapper that ports your DataFrames into SQLite and lets you query them with SQL. You can install it via pip and import the sqldf function like so:
pip install pandasqlfrom pandasql import sqldf
From there, you just write your query as an argument to the sqldf() function. Results are automatically returned as a Pandas DataFrame, which is nice.
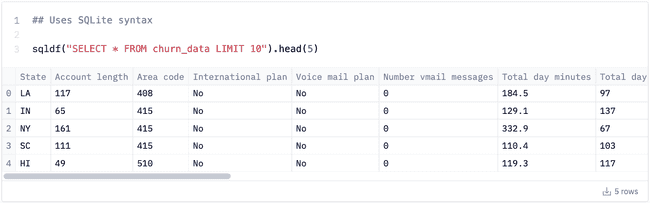
You’ll notice that our FROM clause references churn_data, which is actually just a variable (DataFrame) in memory. The neat work under the hood here is that pandasql is scanning variables to find DataFrames, and treating them like SQLite tables. That makes it very easy to get up and running, with literally no config.
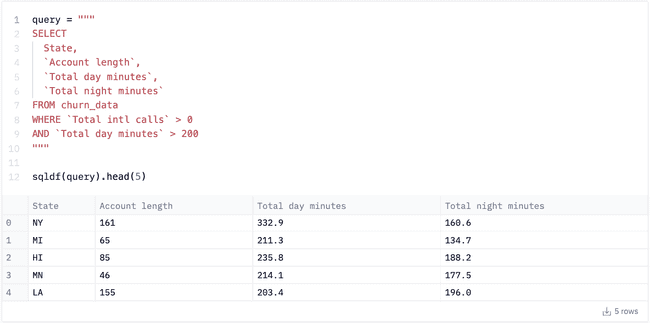
For longer queries, you’ll want to break them into their own variables:
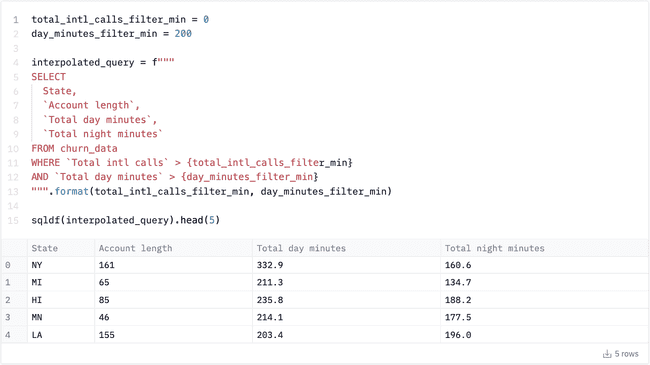
Which also allows you to use string templating:
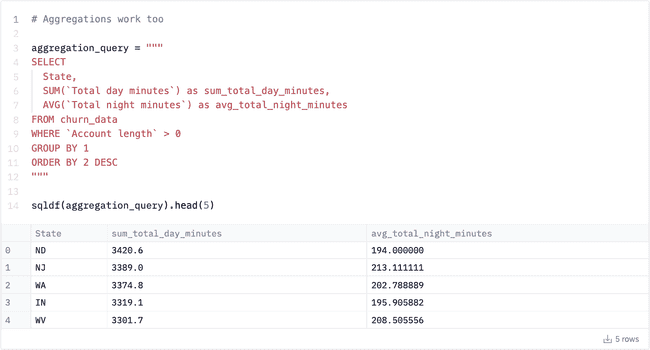
Because the engine is SQLite, you can write pretty much normal SQL, including aggregations:
This is just the tip of the iceberg: SQLite supports other Analyst Classics™ like window functions, generated columns, and of course, common table expressions. So have at it. 1
Note: the original post from Yhat talking about pandasql is sadly gone, but KDNuggets has archived it here if you’re curious.
Method 2: using DuckDB to query Pandas DataFrames
Unless you’ve been living under a rock (don’t tempt me), you have probably heard of DuckDB, the analytics / OLAP equivalent of SQLite. It’s an in-process OLAP system that’s incredibly easy to set up and use, optimized for analytics workloads, and conveniently for us, quite ergonomic for writing SQL against data in Pandas.
Unlike pandasql which is a 3rd party wrapper on top of SQLite, duckdb works natively with Pandas DataFrames. Start with the usual, and install it if you haven’t already (isn’t it nice to install a database via pip?):
pip install duckdb
import duckdbThe basic query syntax for duckdb is similar to pandasql:
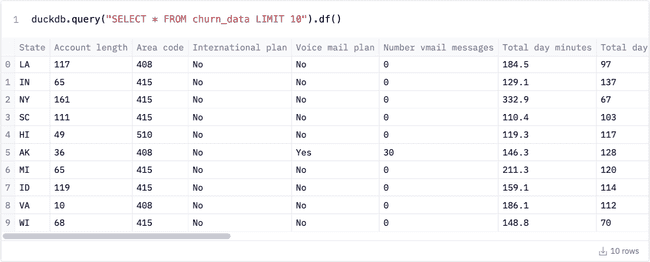
The main difference is that we need to coerce (or more accurately, convert) the results to a DataFrame explicitly. Similarly to pandasql, DuckDB automatically scans your kernel for variables that are DataFrames and lets you query them as if they’re tables. This scan happens at query runtime, though, so you can’t use things like DESCRIBE:
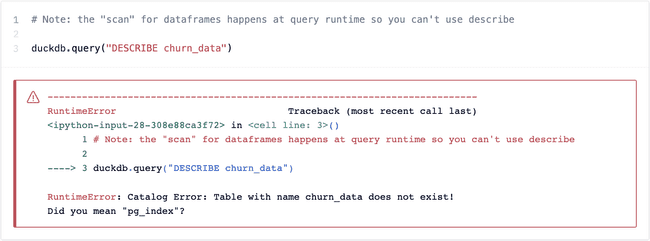
After a little tweeting, I was able to find a workaround from a DuckDB employee that involves creating a view on top of the DataFrame, but I digress.
DuckDB’s handling of whitespace is more difficult to work with than that of pandasql. Backticks don’t parse, so you’ll need to reference the table (DataFrame) name, followed by the column name in quotes. This totally did not take me 30 minutes to figure out, no sir.
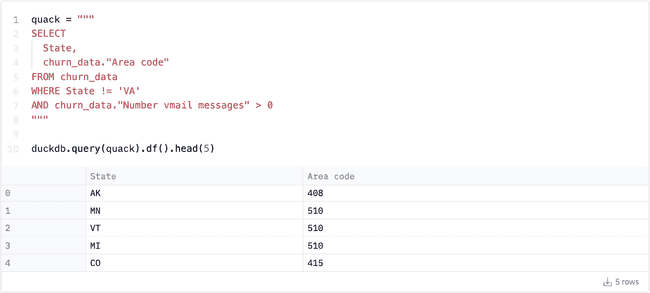
Because DuckDB is purpose built for OLAP use cases, you get a few nice functions that don’t exist in pandasql and SQLite. One example is the SAMPLE keyword, which allows you to easily sample your data, useful for aggregate functions over large datasets:

DuckDB SQL syntax is more or less built to mirror PostgreSQL, but there are a few differences – check out the docs to see what works / what doesn’t.
The main reason you’d use DuckDB over SQLite for querying Pandas data though – and perhaps we’ve buried the lead here – is speed. DuckDB claims to be significantly faster than SQLite for analytical queries, and reasonable benchmarks on their site seem to back this up. The basic gist is that Pandas’s built in to_sql and from_sql functions work painfully slowly with SQLite, but they’re pretty quick with DuckDB. The speed difference is pretty significant on their aggregate benchmark query:

By the way, the same work that DuckDB is doing under the hood to identify DataFrames works for local CSV files, which is quite nifty.
More broadly, we are a bit biased here but DuckDB is getting a lot of new traction among the data community and is worth checking out. A good place to start is DuckDB founder Hannes Mühleisen’s talk here.
Method 2.5: the Pandas .query() method
OK, technically this isn’t SQL, and it’s limited in scope – but still worth covering. You may already be familiar with the .query() function in Pandas. It’s not exactly SQL, but it can make some basic queries a bit easier. It’s a simple WHERE or .filter() equivalent:
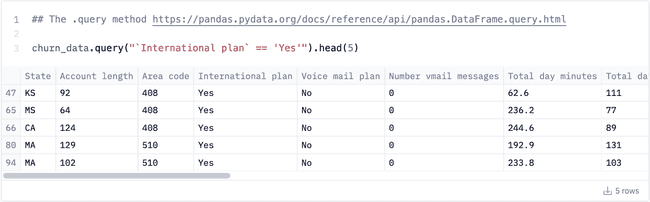
Our dataset has whitespace in column names (curse the source) which makes the formatting here a bit annoying. The documentation for the .query() method is on the sparse side: I had to basically guess that you can use the & operator to chain filters:

The docs note that the query syntax is modified Python (without many specifics), but you can change the parser to use standard Python syntax (e.g. and instead of &). I wasn’t able to get that parser keyword to work though, as of Pandas 1.4.2. It went straight to evaluating the expression and noted (correctly) that and is not a valid numexpr keyword.
For more detailed information on Pandas parsers, and numexpr in particular, check out the parent level eval() docs here. You can read more about numexpr (which was originally a numpy thing) on GitHub.
Are we missing any other ways to query your Pandas DataFrame with SQL? Let us know!
- ↩ If you are creating a CTE inside SQL inside Python…you should probably just make a new DataFrame.