Blog
Modernizing Jupyter workflows with Hex + Snowflake
A supercharged, collaborative, cloud-native way to notebook

Jupyter Notebooks have been the data scientist’s tool of choice for years. They’re the go-to workspace for pretty much any data science task, from manual cleaning to complex machine learning, and they’ve become famous for letting users move fast and iterate while keeping a self-documenting log of what’s being done. We are huge fans of Jupyter at Hex, and the entire industry owes the project a debt of gratitude for pushing us into a delightful new era of data work.
But traditional notebooks like Jupyter aren’t built for the kind of data workflows that are becoming the norm. Their architecture is based on outdated assumptions about scale and data size and they don’t operate well on large datasets. They also don’t mix well with the software engineering best practices that the data world is embracing, lacking real version control or integrations with the rest of the stack. And most importantly, they simply aren’t easy to use or accessible to less technical users, who are the vast majority of people who work with and consume data. In the era of the Modern Data Stack (or whatever you want to call it), people expect data tools to be:
- Easy to set up.
- Directly integrated with other tools.
- Collaborative and version controlled, ideally with git.
- Able to operate on large datasets.
- Able to generate easily shareable outputs.
Jupyter Notebooks, for all their single-player excellence, are simply not geared towards meeting these goals for modern data teams. Using Snowflake to power your data workloads but accessing it via a traditional notebook is like cutting a hole in the floor of your Lamborghini and shuffling it along with your feet.
Well, maybe not quite that bad. But you get the point. In this post, we’ll walk through exactly where Jupyter Notebooks fall short for Snowflake users, and explain how Hex is moving things forward to let your team operate with notebook efficiency on data of any size.
“I was content with Jupyter Notebooks and didn't know that there was something better out there, but got my hands on Hex and said, ‘Wow, this fills a huge hole that I didn't know that I had, but now I do. And I'm grateful to have it.’” — Adam Whitaker, GTM Analytics Lead, BlueCore
Ease of installation
Installing Jupyter locally requires knowledge of the command line, experience with pip or conda and homebrew, and the ability to debug verbose errors. True story: while installing Jupyter to test something for this post, I broke my local Python and had to start from scratch.
I won’t belabor the point with dozens of examples, but any Pythonista knows that the package and dependency prerequisites to a local Jupyter install are a complete dealbreaker for less technical users— and often a real roadblock even for technical users.
Hex is a cloud-hosted service, so there’s nothing to install and no Python command line woes. You’ll never need to worry about Anaconda or pip errors. And everything is immediately accessible to any member of your organization at the same URL— so you can share a notebook with anyone just by sending them the link.
Speaking of pip, you can easily import libraries from our preinstalled list without having to use pip, or install new ones using pip without having to touch the command line. You will never need to deal with another virtual environment or misconfigured installation.
Data Access and SQL
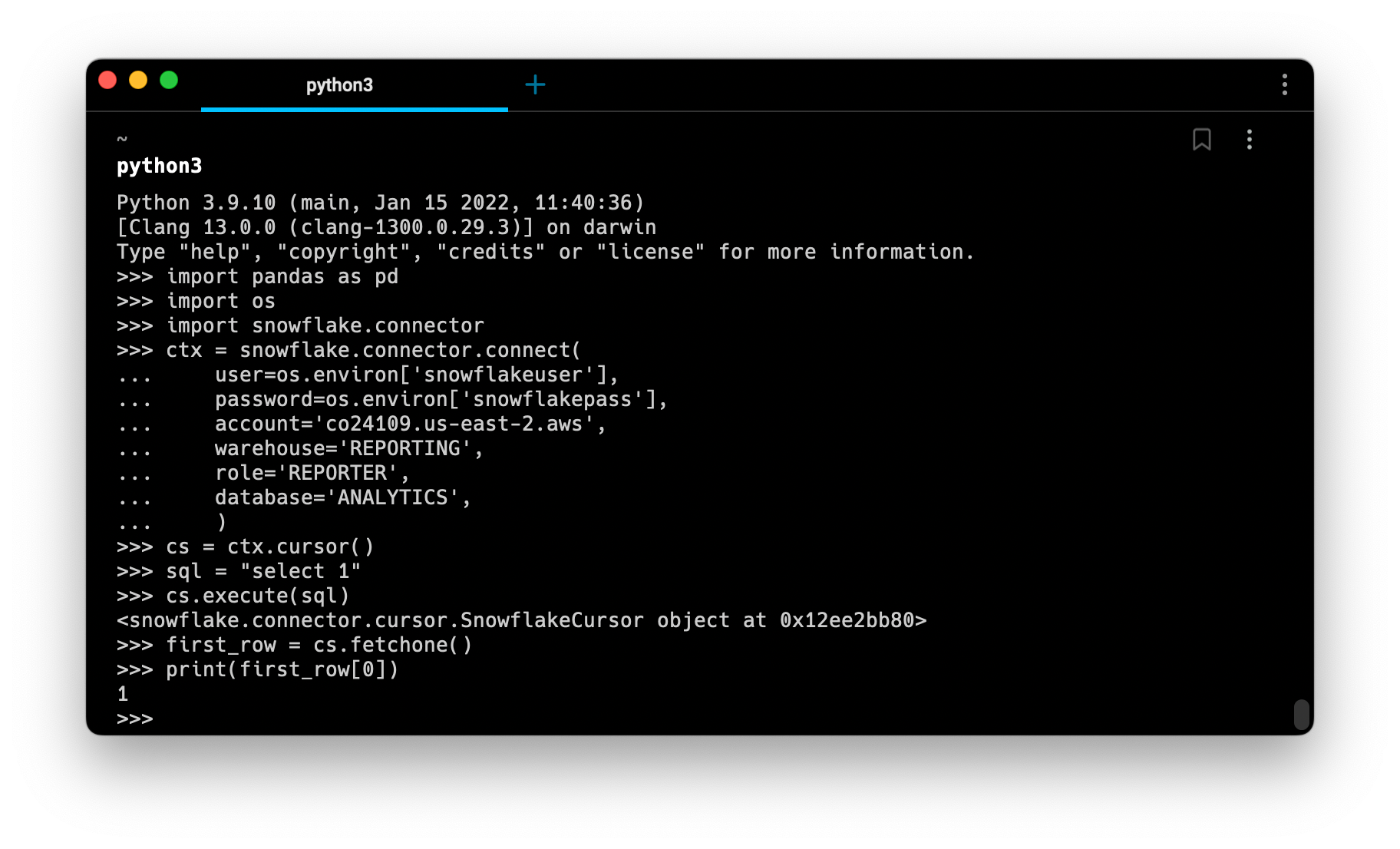
Traditional notebooks run Python. This is fine for Python experts, but Python users represent just a subset of data users. And if your data is in a Snowflake warehouse, you’ll have to write SQL to get it out anyway.
In a Jupyter Notebook, this flow is pretty clunky:
- Install the Snowflake connector for Python
- Get Snowflake credentials from a database administrator (securely)
- Load these credentials into your notebook environment (securely)
- Write some Python code to open a connection and establish a cursor to your warehouse
- Write SQL as a Python string, without any of the quality-of-life features that are traditionally found in a proper SQL IDE like autocomplete, auto-formatting. autocompletion, syntax highlighting, etc.
- a. Or let’s be honest, probably: Write SQL in the Snowflake IDE and then copy/paste it into the notebook to execute
Security concerns of handling credentials aside, this flow just isn’t ergonomic. It’s cumbersome, time consuming, and you wind up switching between windows to copy/paste code or writing SQL without any autocompletion or assistance.
This also means that you need to know Python to get any value from a Jupyter Notebook. SQL-only or SQL-first users can’t take advantage of all the benefits of working in a notebook, because everything is wrapped in Python.
Hex treats SQL as a first class citizen. An administrator can easily configure a Snowflake data connection once and share it with users (or the entire workspace). These users can write SQL in full-featured SQL cells, taking advantage of autocompletion, syntax highlighting, caching, and more. No sketchy credential storage or copying/pasting SQL. Just quick and easy queries.
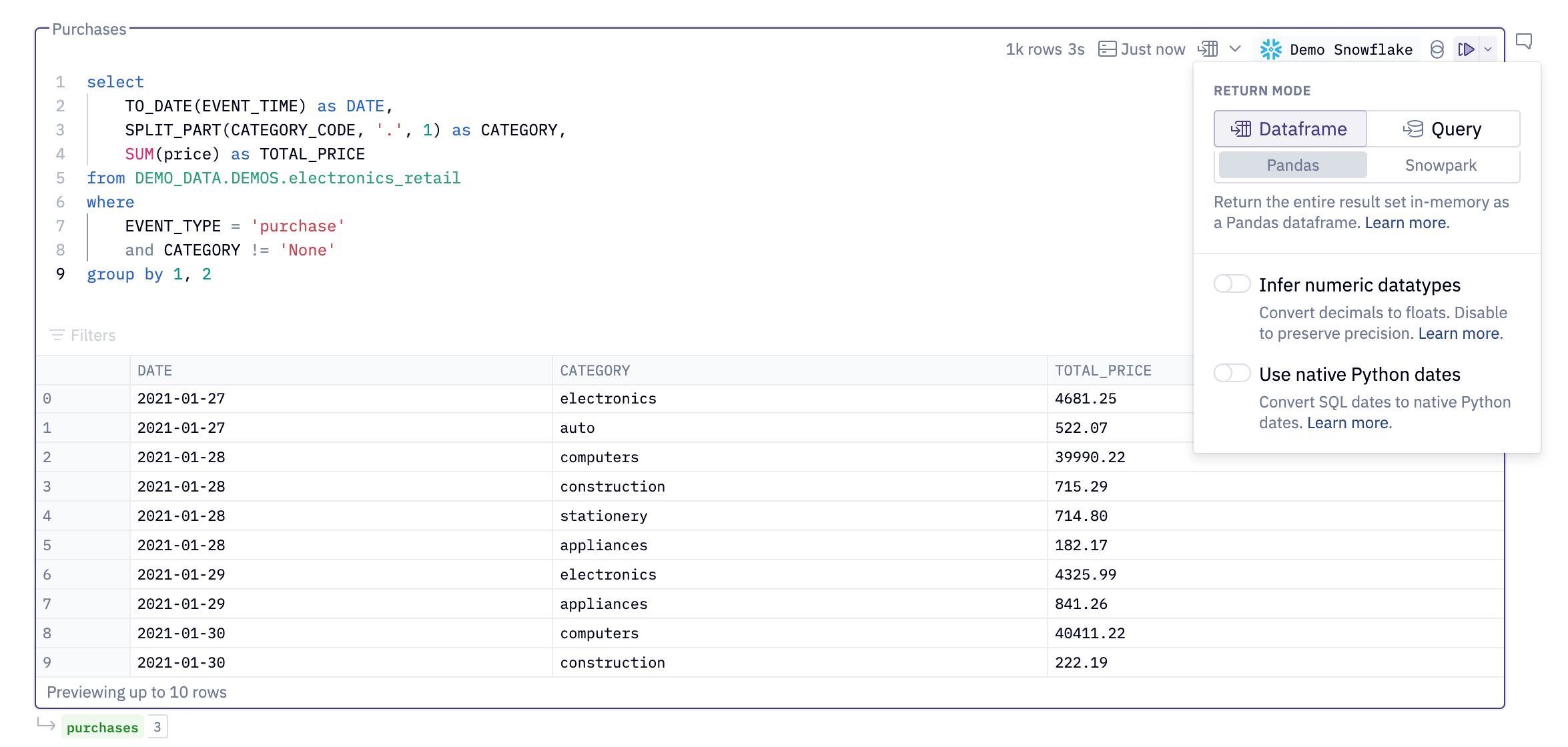
The results of any SQL query are returned as a DataFrame that can be referenced in any other Python or SQL cell in the notebook. Hex notebooks are fully polyglot, and users get value out of them via SQL, Python, or most commonly: a blend of the two.
Bonus: It’s super easy to connect to Snowpark with Hex. Users who prefer Python can create a Snowpark session with one click instead of having to deal with bulky configuration boilerplate— or sketchy shared credentials.
Data Scale
Jupyter Notebooks run using a “kernel”, a persistent process that executes all the Python code in a notebook. This kernel has a limited amount of memory in which it can store data, usually on the order of a couple of gigabytes.
Snowflake is designed to store and operate on tremendous amounts of data. Their benchmark blog post coyly notes that “The 5XL warehouse size would be useful for higher data volumes, such as 300 TB or 1 PB”. I don’t have a petabyte of data lying around, but I do have a few hundred gigabytes, and you simply cannot work with data even approaching that scale with a Jupyter Notebook— it will run out of memory and crash.
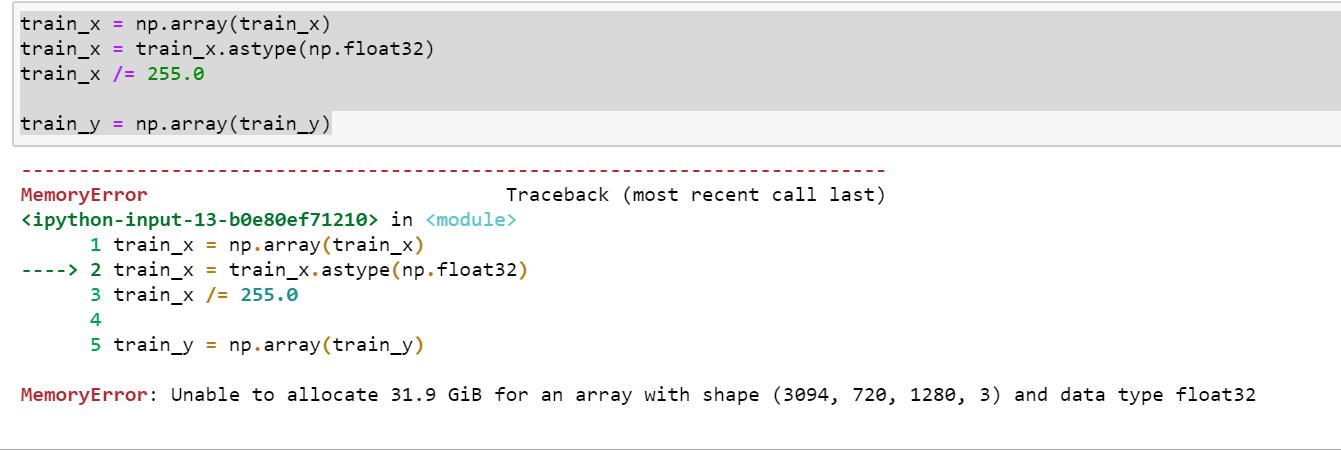
So analysts usually work outside of the notebook to prototype rollup queries and filters that reduce the size of their data. Once they’ve generated a small enough subset of data, they bring it into memory and work in the notebook. Sometimes, an analysis just can’t be done because the data required would be too big to work with.
Because Hex runs in the cloud, you can dynamically increase the amount of memory and processing power allocated to your notebook— just like you might turn a Snowflake warehouse from a Small up to a Medium to run some heavier workloads.
Hex also enables you to work with data at any scale using Query Mode, a unique feature that executes queries in Snowflake but leaves most of the data in the warehouse, only loading a 100-row preview into the notebook.

Because you can “chain” SQL queries in Hex, you can rapidly and iteratively explore datasets of any size without having to stream millions of rows of data out of Snowflake.
Even if you do have petabytes of data, you can still explore, transform, and visualize it using Hex.
For more on Query mode and Chained SQL, check out the full blog.
Version Control
Software engineering best practices are sweeping through the data world. dbt has helped with this, creating an entire new discipline of Analytics Engineers who aren’t just SQL users but are also familiar with the command line and Git.
Jupyter Notebooks have not ridden this wave into the version-controlled future. Checking a .ipynb into Git is useful for keeping a backup, but good luck trying to parse through the diff to see what’s changed version-to-version. Pull requests and code reviews can be painful.
There is no magic bullet to solve version control issues with traditional notebooks. Users need to import a handful of packages, manage the majority of the process on their own, and say a prayer to avoid the dreaded Jupyter disaster.
Hex has built-in autosaving and versioning, with a rich visual diff explorer. It’s easy to save a new version of a notebook, see exactly what’s changed from version to version, and roll back to a previous version if necessary.
Hex also integrates with GitHub and GitLab to allow for pull request workflows on your production data artifacts. These practices have probably already made it to the rest of your data stack, and it’s just the “wild west” of notebooks that haven’t caught up.
You can always back up and export your Hex projects, so there’s no vendor lock-in.
Collaboration
Jupyter Notebooks were built as a single-player tool. You run them on your machine, work on a project, and then somehow send that finished project to others (we’ll get back to this). Some collaboration features are being built into experimental versions of Jupyter and JupyterHub, but they’re still a far cry from the Google Docs benchmark of real-time editing.
Hex natively supports real-time multiplayer collaboration. Any number of users can work together to solve a data problem within a project. Users can see other edits in real time, leave comments, and lock cells they’re working in to prevent any confusion or overwriting. And any number of stakeholders can freely (quite literally — we don’t charge for viewers!) see the outputs of that project (more on this below).
Sharing and Publishing
The most important part of any data project is how you get it in front of stakeholders to impact the business. If you do the world’s most important analysis but no one ends up seeing it or understanding it, you may as well not have done anything at all. When you’re done with an epic notebook, your magnum opus complete, what do you do?
- Email the .ipynb to people. This only works for technical viewers, though, and some may not be able to open it.
- Turn it into a static pdf. The artifact is capturing a point-in-time view of the data, which can quickly become out of date without any interactivity. Any requests to tweak a filter or see a different segment means more work for you.
- Take screenshots and put them into a doc or deck for context. This suffers from the same staleness and lack of interactivity.
Moral of the story: It’s really hard to share the output of data projects if the results are locked up in a notebook that only technical users can open.
“We recognized that while Python-driven analysis workflows were an extremely powerful paradigm, they created a high barrier to entry since users needed to know how to code. We’ve made some solid progress despite this learning curve by combining low/no-code solutions and our in-house data capture and analytics system, but we often found that key results would get ‘stuck’ in notebooks.”- Harneet Singh Rishi, Novome Biotechnologies
Hex lets you drag and drop notebooks into beautiful, polished data apps that can be published and shared with anyone, no knowledge of code required. Each cell from a notebook becomes a building block of an app, complete with user interactivity, query parameterization, and powerful caching.
Bonus: State and Reproducibility
The way traditional notebooks like Jupyter, Colab, and Deepnote handle compute and memory state is a massive source of frustration— especially for beginners. This angst is most infamously documented by Joel Grus's "I don't like notebooks" talk at JupyterCon (video, slides).
The issue, in short: Most notebooks let you run individual cells out of order, which makes it very difficult to figure out what the current state of any variable or dataframe is. As notebooks grow more complex, it’s very easy to tie yourself in awful state knots. You run a few cells out of order to test some things, or avoid running an expensive chunk of logic, and suddenly you’re seeing weird, inconsistent outputs. There isn’t a great solution to this, other than building up a complex state map in your head, or frequently restarting your kernel and running everything from scratch.

This causes three major issues:
- Interpretability: it’s hard to reason about what’s happening in a data notebook, whether it's your own or someone else’s.
- Reproducibility: because cells can be run in any arbitrary order, reproducing a current state can be difficult without frequently re-running all the logic from scratch.
- Performance: re-running everything from scratch can be wasteful and time-consuming.
Hex uses a reactive, graph-based execution model to automatically keep cell state in sync. Every time you run a cell, Hex computes the upstream and downstream dependencies of that cell and executes them as well, making for a fast, reproducible, and easy to understand state model.
Final verdict
Traditional notebooks are flexible and capable of handling a wide variety of data tasks, but when you’re dealing with cloud-scale data workloads in Snowflake, they simply aren’t powerful enough.
On the flip side, you can spin up a Hex notebook with zero installation process, connect it directly to your Snowflake warehouse without any code configuration, and collaboratively query or chart data without fear of running out of memory. When you’re done working, you can auto-generate and customize a curated, beautiful, and interactive version of your project— and share it with just one click.
Alex Sacco, Senior Director of DataOps and Analytics at BlueCore, said it best:
“We wanted a tool as powerful and flexible as Jupyter Notebooks, as shareable and collaborative as Google Sheets, and as scalable as an enterprise BI platform. It’s a little on-the-nose, but that’s how I view Hex. We can create powerful reporting and analysis that’s fully shareable and replicable. We can prototype transforms and even UI analytics features at incredible velocity, with potential for deep collaboration. There’s even a customer experience win, where live apps can be shared with clients to answer key analytics questions.”
So, the next time you think about popping open your trusty Jupyter Notebook, why not try Hex instead?