Blog
How Overfitting Ruins Your Feature Selection
Learn how to prevent overfitting from impacting your model.

Machine learning models work on the principle of “Garbage In Garbage Out” which means if you provide poor quality, noisy data, the results produced by ML models will also be poor.
But all real-world data comprises relevant data and noisy data, inaccurate data, outliers, and redundant features. These irregularities in any dataset impact negatively on the model’s performance. Also, if you have a lot of features in your data, the model training time will be huge while the model will not learn any relevant information.
This is where feature selection helps. Feature selection is a component of feature engineering that helps in choosing the most relevant features from a dataset for a specific ML use case. Feature selection works by excluding redundant and irrelevant features and selecting the best features that can enhance the performance of your model. Let’s go through how overfitting can ruin your feature selection leading to lower model performance.
The Role of Feature Selection
Feature selection is a prominent part of feature engineering that is needed for the following reasons:
- Reduced Model Training Time: A higher number of features always results in a higher training time for the model. If we only use the relevant set of features then the training time can be significantly reduced.
- Explainable Models: Having too many features to process makes the ML model complex and unexplainable. Due to this, stakeholders and customers find it difficult to trust the model results. Feature selection resolves this issue as the model has to focus on a lower-selected set of features.
- Increased Precision: Removing the redundant and irrelevant features reduces the variance and leads to the high precision of the estimates.
- Cure to Curse of Dimensionality: When you deal with high dimensional data (higher number of features), a set of problems arise, this phenomenon is known as the
- curse of dimensionality. As feature selection reduces the dimensionality of the data, this problem is solved effectively.
The methods of feature selection are majorly classified into two categories Supervised and Unsupervised. Methods that take target feature into account for selecting the best set of features are called supervised feature selection methods. These methods are further classified into Filter Methods, Embedded Methods, and Wrappers Methods. On the other hand, methods that solely rely on the features to come up with the most relevant feature set are called unsupervised methods.
The Basics of Overfitting
Before discussing the effect of overfitting on feature selection let’s first understand what overfitting means in machine learning.
Usually, there is a fair amount of noisy information in our data. When we train the machine learning models in this data, they learn the noise and patterns from the training data that negatively impact the performance of the models and as a result, they fail to generalize well on the validation and testing data. This problem of performing well on training data and poorly on the testing one is called overfitting. It is the result of low bias and high variance.
How Overfitting Occurs in ML Models?
There are various reasons for overfitting, some of the most important ones are:
- Presence of noisy and irrelevant data such as inaccurate observations and outliers in the training dataset.
- The size of the training dataset is too small, it has a higher number of features and it does not represent all the possible input data values.
- Model is highly complex and learns the noisy and irrelevant information from the data.
- The variance of the model is very high which lowers the precision.
Overfitting and Feature Selection
Now that you understand both feature selection and overfitting, you must know that having too many features in the dataset can ultimately lead to overfitting while having a very small number of features in the dataset can lead to underfitting. So, we need to come up with an optimal feature set that can improve the predictive performance of the models and reduce the overfitting.
How Overfitting Ruins Feature Selection?
Overfitting can undermine the effect of feature selection in several ways, which are:
- Inconsistent Feature Importance Rankings: Feature selection methods often rank the features in a training dataset based on their feature important score. In the presence of overfitting, these rankings can be erroneous because the model has memorized the irrelevant information based on the noisy data. As a result, a fluctuation can be seen in the feature importance scores making it difficult to make an informed decision about which features to keep and which ones to ignore.
- Discarding Relevant Features: The overfit models can ignore the genuinely relevant features during the feature selection process. This happens because the model has fit the training data so closely that it assumes features, that may be important for generalization, are unnecessary. Feature selection methods may mistakenly discard these important features, causing the model to lose predictive power on unseen data.
- Selecting Irrelevant Features: Overfitting happens when models learn the noise and random fluctuations in the training data and mistake them for meaningful patterns. So when you have overfitting, it is highly likely that your model has irrelevant features with really low predicting power. Feature selection methods may struggle to identify these irrelevant features amidst the noise, leading to an inefficient feature set.
- Increased Sensitivity in Data variability: High sensitivity for the training data is the key indicator of overfitting. A minor change in the dataset can lead to substantial changes in the selected feature set. When using various datasets or data subsets, this instability might make it challenging to duplicate or trust the feature selection process.
- Poor Generalization: The ultimate goal of the feature selection method is to improve the model’s generalization performance on unseen data. As overfitting compromises this goal, feature selection, therefore, becomes less effective at improving the model’s ability to generalize to new, unseen examples.
These reasons are enough to look for the solution of overfitting so that you can choose the relevant set of features using feature selection methods and as a result, you can improve the predictive performance of the model.
Overfitting with a decision tree
Let’s step through an example. We’ll generate a synthetic dataset with both relevant and irrelevant features, and then fit a model without any regularization and with too many features, thus allowing it to overfit.
You can find this example as a Hex notebook here:
Let's say we have two relevant features and 18 irrelevant/noisy features. We'll generate 1000 samples. The relation between the output and the two relevant features will be linear. The rest of the features will be random noise:
import numpy as np
import pandas as pd
from sklearn.datasets import make_regression
# Set random seed for reproducibility
np.random.seed(42)
# Generate synthetic data with 2 informative features and 18 noise features
X, y = make_regression(n_samples=1000, n_features=20, n_informative=2, noise=0.5)
# Convert to DataFrame for better visualization
df = pd.DataFrame(X, columns=[f"Feature_{i}" for i in range(1, 21)])
df['Target'] = y
df.head()We've created a synthetic dataset. As you can see:
- The first two features are relevant and have a linear relationship with the target variable.
- The other 18 features are essentially noise.
Now, let's fit a model without any regularization and with too many features. We'll use a decision tree for this purpose. Decision trees are prone to overfitting, especially when we allow them to grow without constraints. After training the model, we'll extract feature importances to see which features the tree deems most important.
from sklearn.tree import DecisionTreeRegressor
# Train a decision tree regressor without constraints (prone to overfitting)
tree = DecisionTreeRegressor()
tree.fit(X, y)
# Extract feature importances
feature_importances_overfit = tree.feature_importances_
feature_importances_overfitThe feature importances are presented as a proportion of the total importance.
array([8.39667679e-05, 2.89214001e-05, 2.14382700e-05, 9.96077830e-01,
5.84358121e-05, 7.50924992e-05, 5.25641864e-05, 4.08189016e-05,
4.17799006e-05, 3.16843168e-05, 2.20349196e-05, 1.51199888e-04,
3.66689548e-05, 8.84894487e-05, 9.37809032e-05, 6.04876070e-04,
3.94749536e-05, 6.34848635e-05, 2.29273318e-03, 9.47245672e-05])As you can observe, the decision tree has given an overwhelming importance to feature 4 (9.96077830e-01), which is one of the noise features. This clearly indicates overfitting because the tree has latched onto the noise in the data.
Strategies to Prevent Overfitting in Feature Selection
Preventing overfitting is not an easy fix.
Let’s continue from the example above and fit a model with some form of regularization or a simpler model to prevent overfitting.
Using regularization techniques is an effective way to penalize the overfitting. By adding a penalty term to the loss function, regularization techniques prevent the model from picking up extremely complex patterns that would not generalize properly. There are different techniques of regularization in traditional machine learning models that include L1 Regularization, L2 Regularization, and Elastic Net Regularization. For the neural networks model, you can use the Dropout, Batch Normalization, or Early Stopping to observe and prevent overfitting.
For this, we'll train a decision tree again, but this time with constraints to prevent overfitting (like setting a maximum depth). After training, we'll extract the feature importances.
# Train a decision tree regressor with constraints to prevent overfitting
tree_regularized = DecisionTreeRegressor(max_depth=3)
tree_regularized.fit(X, y)
# Extract feature importances
feature_importances_regularized = tree_regularized.feature_importances_
feature_importances_regularizedThe regularized decision tree has also given all its importance to feature 4.
array([0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.])This suggests that the noise in feature 4 might be particularly misleading, even for a more constrained tree. For a more comprehensive comparison, let's compare the feature importance from both models. We'll visualize the feature importances from both models side by side to clearly see the differences.
import matplotlib.pyplot as plt
# Plot feature importances
fig, ax = plt.subplots(1, 2, figsize=(15, 6))
# Overfit model
ax[0].barh(df.columns[:-1], feature_importances_overfit, align='center')
ax[0].set_title('Feature Importances (Overfit Model)')
ax[0].set_xlabel('Importance')
ax[0].set_yticks(df.columns[:-1])
ax[0].invert_yaxis() # Reverse the order of features for better visualization
# Regularized model
ax[1].barh(df.columns[:-1], feature_importances_regularized, align='center')
ax[1].set_title('Feature Importances (Regularized Model)')
ax[1].set_xlabel('Importance')
ax[1].set_yticks(df.columns[:-1])
ax[1].invert_yaxis()
plt.tight_layout()
plt.show()Which outputs:
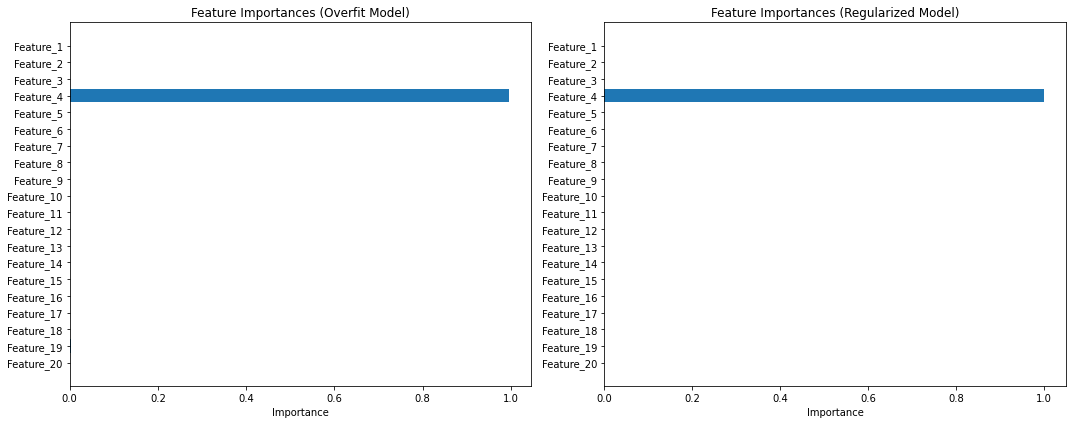
From the visualizations, we can observe the following:
- Overfit Model: The unconstrained decision tree (prone to overfitting) has given significant importance to feature 4, one of the noise features, while almost completely ignoring the actual informative features.
- Regularized Model: The constrained decision tree, designed to prevent overfitting, also gave all its importance to feature 4. This means that despite our efforts to regularize the model, the noise in feature 4 was still strong enough to mislead the tree.
Both models failed to correctly identify the truly informative features (feature 1 and feature 2). This demonstrates that overfitting can significantly affect feature selection and underscores the importance of careful model validation and feature engineering.
In real-world scenarios, other techniques such as cross-validation, feature selection algorithms, and ensemble methods can be used to address such issues and get a better understanding of feature importance.
Cross-validation and its Role in Feature Selection
Cross-validation is an effective method to reduce the effect of overfitting. It works on the principle of distributing the initial training dataset to mini-train and test splits and using these splits for training. One such widely used technique is K-Fold cross-validation. This method divides the original training dataset into k different subsets known as folds. Out of all these subsets, k-1 folds are used for training the ML models while the remaining fold (often called the holdout fold) is used for testing. This way it allows us to tune the hyperparameters of the model according to the training set and immediately test it on the unseen data (test fold).
Balancing Feature Selection and Model Complexity
Finding a perfect balance between feature selection and model complexity is an iterative process. It often suggests starting small with the simpler model and trying feature-important analysis to identify a relevant set of features that do not overfit. You must try the above two methods that ensure the reduction of overfitting. It’s essential to continually assess your model’s performance on validation data and be willing to adjust your feature set and model complexity as needed to achieve the best results while preventing overfitting.
Ensemble Methods and Mitigating Overfitting
Ensemble methods are a powerful strategy to combat overfitting in machine learning. They work by combining the predictions of multiple base models, allowing the ensemble to capture diverse perspectives and reduce individual model biases. Common techniques include Bagging (Bootstrap Aggregating), where multiple subsets of the training data are used to train different models, and Boosting, which focuses on training subsequent models on the errors of the previous ones.
Another popular ensemble method is the Random Forest, which creates a 'forest' of decision trees, each trained on random subsets of features and data samples. By aggregating the predictions of individual models, ensemble methods often achieve better generalization on unseen data, reducing the risk of overfitting. Moreover, ensemble methods can provide more stable and interpretable feature importances, offering insights into which features genuinely drive predictive power.
Careful Feature Selection
Overfitting can ruin feature selection, leading to poor predictive performance of the model. Techniques such as cross-validation and ensemble methods further aid in diagnosing and mitigating overfitting, ensuring that models are robust and perform consistently across varied datasets. As we advance in the realm of machine learning, the precision with which we select features will shape the efficacy and reliability of our models. It's not just about building models; it's about crafting them with diligence and insight, ensuring that every decision, every feature, propels us closer to accurate and meaningful outcomes.