Blog
Improving the Notebook Agent: error clustering
Why you should analyze your agent's reasoning, not just its errors



Hex’s Notebook Agent is working pretty well. Customers are giving it a ton of love, in fact, and are using it more every single week. We’ve already shipped a number of improvements to the agent to make it smarter and more Hexy. But until recently, we were relying on direct feedback and internal dogfooding to figure out where exactly these opportunities for improvement were. As adoption grew, we needed a better solution.
We had a good amount of observability and instrumentation already: we had DataDog dashboards tracking errors and failed tool calls, and we even built a tool that allows engineers to manually inspect everything that happened in internal threads, from top to bottom.
The latter has been great for noticing qualitative issues with agent behavior; seeing exactly what actions the agent took, what context it examined, what it thought, and what it decided to do next is indispensable for diagnosing flaws in its analysis.
However, this picture was lacking any real synthesis of these qualitative issues. We knew that various issues existed; the agent sometimes got impatient when cells ran too long, and would spin up new, simpler cells instead; it would call a tool with subtly incorrect parameters (looking at you, “null” vs null...); it would sometimes mess up SQL syntax (don’t we all?).
Because we didn’t have an idea of how frequent these different issues were relative to one another, we didn’t know where to put our focus — what to tackle first to make the biggest impact. Put simply, we were Vibe Debugging.
Using cluster analysis to see where our agent was getting stuck
I have a past life as a BERT wrangler; I used to do old-school information retrieval and information extraction tasks, like document classification, clustering, and named-entity recognition.
When I wanted to see what went wrong in an agent thread, I pretty quickly noticed that I would gravitate towards reading the agent’s thinking messages right near where it made the mistake, so I could understand why it chose to do that.
This gave me an idea: What if we took every errored tool call, and looked at the agent’s thinking immediately following the error? Then we would have a comprehensive dataset of how the agent reacts to specific types of failures.
Obviously, I didn’t want to actually read every single message, so I instead used clustering, a classic data science technique that's great for imposing structure onto unstructured data like text, to smush messages together into coherent groups.
To get precise: we embedded each thinking message with OpenAI’s small embedding model, subdivided messages into groups based on which tool the agent had called, and used K-Means to assign them to clusters.
After forming the clusters, examples from each cluster were given to an LLM to generate a natural language label, so instead of “Cluster 1,” we’d see “Dataframe vs. Warehouse Mode Confusion,” which is more interpretable at a glance. In order to visualize the messages, we used t-SNE to reduce the embeddings to x, y dimensions.
Finally, we turned this into a self‑refreshing Hex app that pulls failed tool calls and computes the clusters on a weekly basis, so we could see our biggest opportunities at a glance.
This process uncovered several interesting findings:
- On a tool-by-tool basis, very clear clusters of errors formed in terms of “what the agent had done wrong” in trying to use the tool.
- Tools that created or edited cells could “time out” if they took too long to run, causing the agent to proliferate smaller and simpler versions of the same cell. Because the agent couldn’t delete cells, this could make a big mess in the project.
- Clear and precise tool errors were significantly more helpful; other, vaguer errors could cause the agent to veer entirely off-track in its analysis.
What the clusters reveal
Most of what the Notebook Agent does, by volume, is write Python and SQL. It thus makes sense for most of the errors to come from these tools. As a result, these tools also have the most interesting clustering results, because they have so many different flavors of errors.
Here’s an example of the different errors we were seeing for the RunSQL tool, the tool that allows the agent to write ad hoc queries for exploratory data analysis:
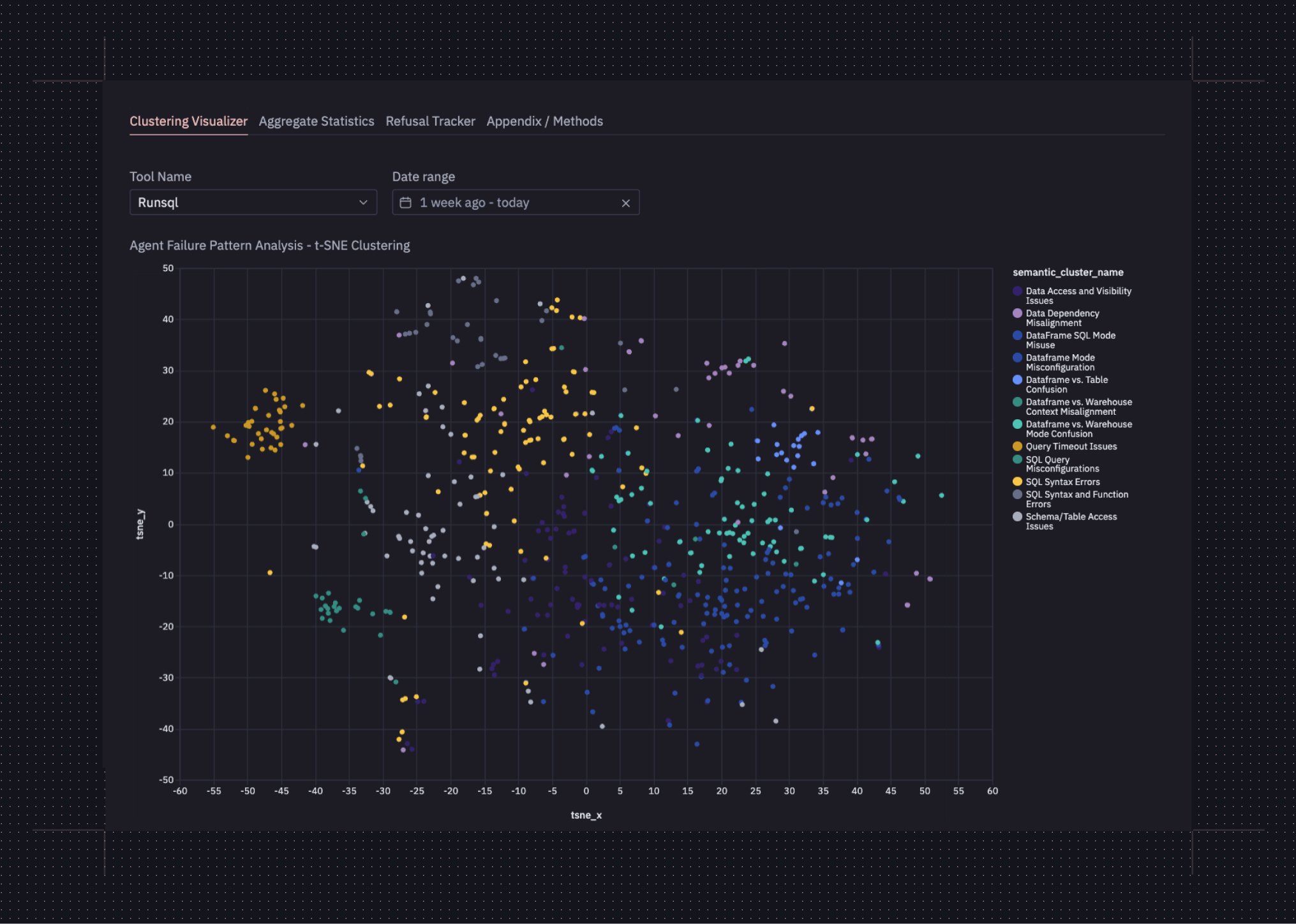
The above chart told us that most of this tool’s errors come from:
- The agent failing to use Dataframe SQL when querying dataframes with RunSQL.
- SQL syntax errors and mixups with using functions correctly (incorrect column and table references, aka hallucinations, also fall into this bucket)
- A longer tail of miscellaneous issues, like queries timing out.
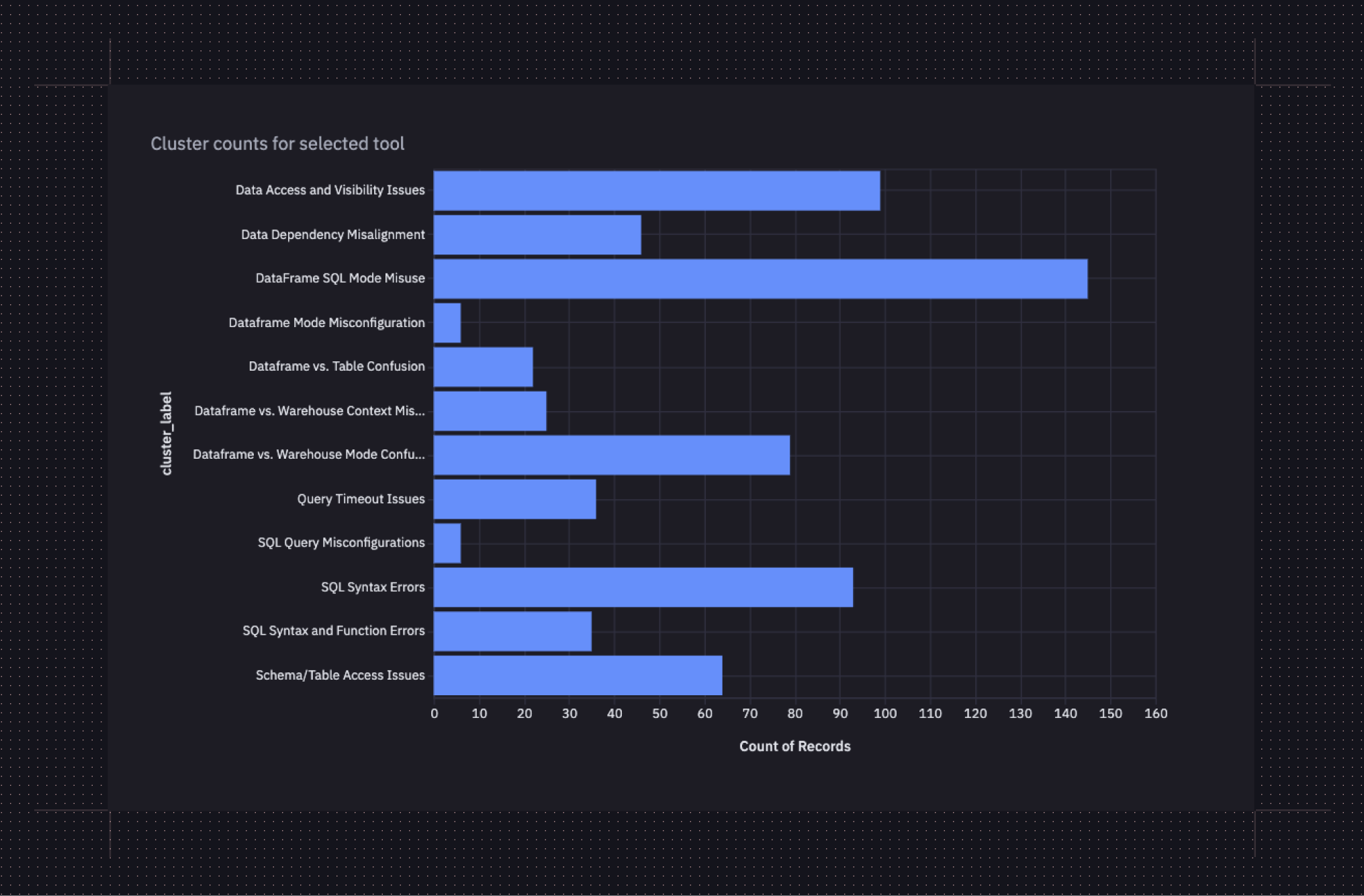
The numbers were helpful, and combined with the qualitative understandings that we had built of each of these error categories via our own dogfooding and usage, gave us a clear set of priorities.
Improving the agent’s understanding of Hex
First: We needed to help the agent better understand how to use Hex, particularly Dataframe SQL. Even though the agent would generally recover from this error within one turn, bumping its head on this over and over was imposed additional latency on analyses.
So, we shipped a bunch of prompt improvements explaining how and when to use Dataframe SQL, as well as a tool that let the agent search Hex docs for info about other features. The latter benefits both the agent and the user, because now the agent can also answer general questions about Hex functionality!
Like humans, the agent occasionally struggled with remembering correct column and table names, how to call functions correctly (especially date functions), and other syntax errors, particularly for lesser-known SQL dialects.
Qualitatively, we’d already noticed that the agent had too strong of a bias towards creating new cells over editing existing ones, which could cause longer analyses to become messy.
We gave it a “notebook DAG” tool to help it better understand the structure of the notebook it was operating in, and enforced a stronger opinion on creates vs. edits, encouraging the agent to edit existing cells over creating new ones.
This gave the agent a much stronger relational understanding of the code in the notebook and kept logic together, making it easier to reason about.
Timing out
Second: We clearly needed to make some changes around how the agent responded to cell timeouts. At the time, the cell tools would wait up to 30 seconds to run; if they didn’t finish before that, they’d simply return a message along the lines of “Cell took too long to run.”
The result is that the agent would see the error, think to itself “oh no, the cell timed out” and decide to simplify its plan. If it were previously querying the full dataset, it would then add an arbitrary limit clause or query fewer columns in order to make it finish faster. Sometimes it would create an entirely new cell with this “simplified” version of the code.
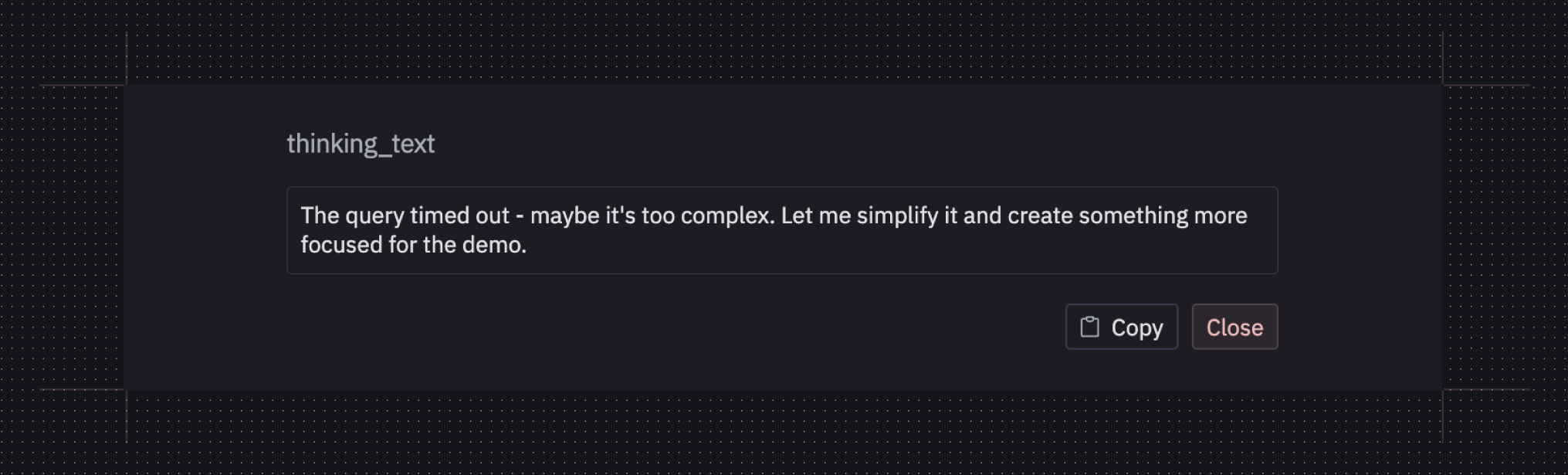
This often isn’t what the author actually wanted! Some operations just take a long time to finish, and that’s okay, as long as we eventually get our answers. We especially didn’t want the agent just proliferating various versions of the same operation in an attempt to get at least one of them to finish; since the agent didn’t have access to cell deletion tools, this just resulted in a mess of similar cells that the author had to go back and clean up themselves.
We fixed this one by softening our language around timeouts and encouraging the agent to check in with the user before making changes after a timeout. Instead of independently deciding to simplify, it now informs the user that the cell is taking a while, and asks the user if they’d like to simplify or just wait. If the user says to wait, the agent will also prefer to wait for future long-running operations by default, and will pick up other available work in the meantime.
The importance of good error messages
The last impactful finding from this analysis was that good error messages, perhaps unsurprisingly, vastly increased the chance that the agent would recover gracefully and continue the analysis as planned.
Slightly more surprising was the discovery that, if the agent got a vague and unhelpful error, it would often completely pivot its strategy, dropping the tool in favor of a different one, instead of trying to figure out where it might have gone wrong.

Our CreateChartCell tool is a fairly complex tool; it takes a structured JSON describing an Explore cell as input, and there are multiple interdependent parameters that are important to get right, else the requested cell is invalid.
The Chart cell is also currently the only cell type that the agent can use to work with semantic models, which are often the most structured, blessed source of business definitions and calculations.
We want the agent to use semantic models whenever possible! But when the agent would call the tool and get “Unhandled tool call error,” — our default error message for unexpected errors — it understandably didn’t really know what to do with that. It would then “bail out” of using Hex-native chart cells and opt for writing SQL against an equivalent warehouse instead.

If it was just trying to chart some data from a dataframe, and it got “Unhandled tool call error,” it would default to Python charts, since those were guaranteed to work. However, Python charts, especially those created with matplotlib or seaborn, are less ideal from an interactivity perspective — unlike Hex charts, they’re static images. If the author were building a Hex app, their users wouldn’t be able to easily filter, inspect, or Explore the data in the chart.
The way these models are trained causes them to react poorly to non-specific tool failures. They assume it’s just broken and take another tack. Investing in clearer errors for agents makes for much better, more predictable behavior.
Making it stick
We’ve productionized this Hex app as an internal tool for our product and AI engineers to consult. We refresh the data regularly with the latest thinking messages and errors, so that we’re always up to date on what our agent’s most common failure modes are. When planning work for upcoming sprints, it helps inform what we can get in as a quick win (like prompt changes around dataframe mode) and what’s going to take deeper, more deliberate experimentation (like the notebook DAG tool).
The best part: we did most of the work on this tool using the Notebook Agent! It wrote the (fairly long and sophisticated) SQL query to pull join all the relevant tables and reasoning traces that followed tool call failures, then wrote pretty much all the embedding and analysis code too. We just came up with the idea, supervised the agent while it worked, and organized it into a nice, neat Hex app.
All in, it only took two AI engineers ~a few hours each to first spin up the prototype, then polish and productionize it, and it’s been serving up insights ever since!
The takeaway: trace the agent's reasoning, not just its errors
It's tempting to treat AI agents like other software systems, where error rates and success/failure metrics tell most of the story. But if you’re leveraging thinking models, why stop at raw tracebacks? The agent's reasoning about errors provides a window into its mental model of the environment that error logs can't capture.
Check out the full list of improvements in our recent Release Notes.