








Don't see what you need?
We're always expanding our collection of examples and templates. Let us know what you're working on, and we'll whip up an example just for you.
A quick guide to Data Clustering
Clustering is a machine learning technique that groups similar data points together based on certain characteristics, effectively forming clusters. It’s an unsupervised learning method and does not require labeled data for training.
Understanding Clustering
In machine learning, clustering helps to uncover the inherent groupings within data, thereby aiding in exploratory data analysis. It can also be used to preprocess data, as an initial step before applying other machine learning algorithms.In clustering, data points are grouped based on their similarity or distance. This can be computed using various metrics such as Euclidean distance, Manhattan distance, or cosine similarity, depending on the context and nature of the data. Data points in the same cluster are more similar to each other than those in different clusters.
Types of Clustering Algorithms
Clustering algorithms represent a variety of methods for partitioning data into subsets:
- Hard and Soft Clustering: Hard clustering assigns each data point to a distinct cluster, while in soft clustering, a data point can belong to multiple clusters with different degrees of membership.
- Hierarchical Clustering: This type of clustering builds a hierarchy of clusters by either a bottom-up or top-down approach. It's particularly useful when the relationship among the data is hierarchical and allows visualization through dendrograms.
- Partitioning Clustering: Partitioning clustering divides data into non-overlapping subsets or clusters without any hierarchy. K-means is a widely used partitioning clustering technique.
- Density-based Clustering: Density-based clustering algorithms identify clusters as dense regions of data points separated by sparse regions. DBSCAN is a well-known example of this type.
- Grid-based Clustering: Grid-based methods quantize the data space into a finite number of cells that form a grid structure and then perform all the operations on these grids.
Popular Clustering Algorithms
Each clustering algorithm has unique characteristics and applications. Understanding these can help select the most appropriate algorithm for a specific task.
- K-means Clustering: K-means is a popular partitioning method that divides data into K non-overlapping clusters. It's widely used because of its efficiency and simplicity.
- Hierarchical Clustering: Hierarchical clustering creates a tree of clusters, which allows for an interpretable hierarchy of clusters. It's often used when the number of clusters is not known a priori.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN is a density-based clustering algorithm that can discover clusters of different shapes and sizes. It's particularly useful for spatial data analysis and anomaly detection.
- Spectral Clustering: Spectral clustering uses the eigenvectors of a similarity matrix to reduce the dimensionality of the data before clustering in fewer dimensions. It's capable of identifying complex structures.
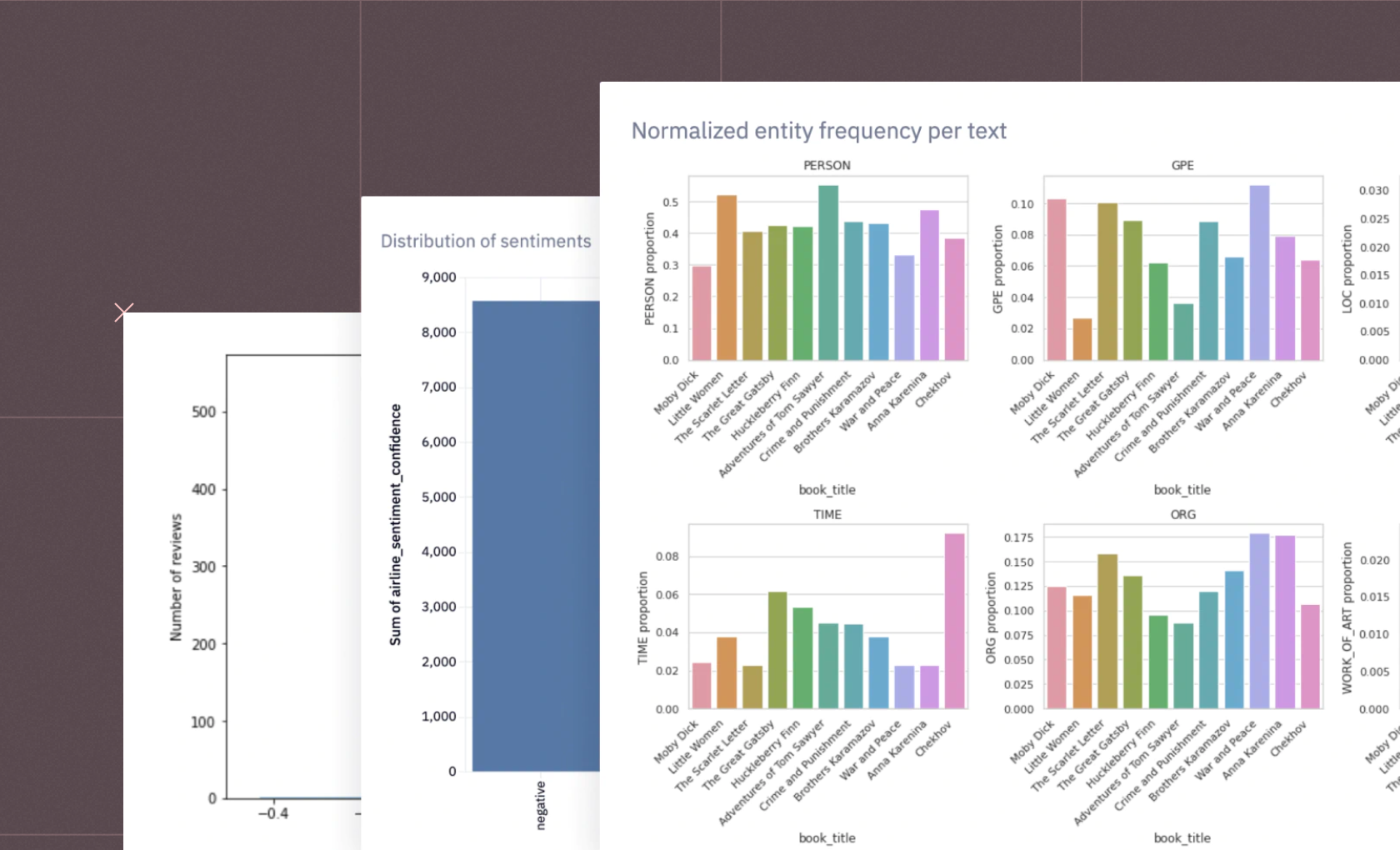
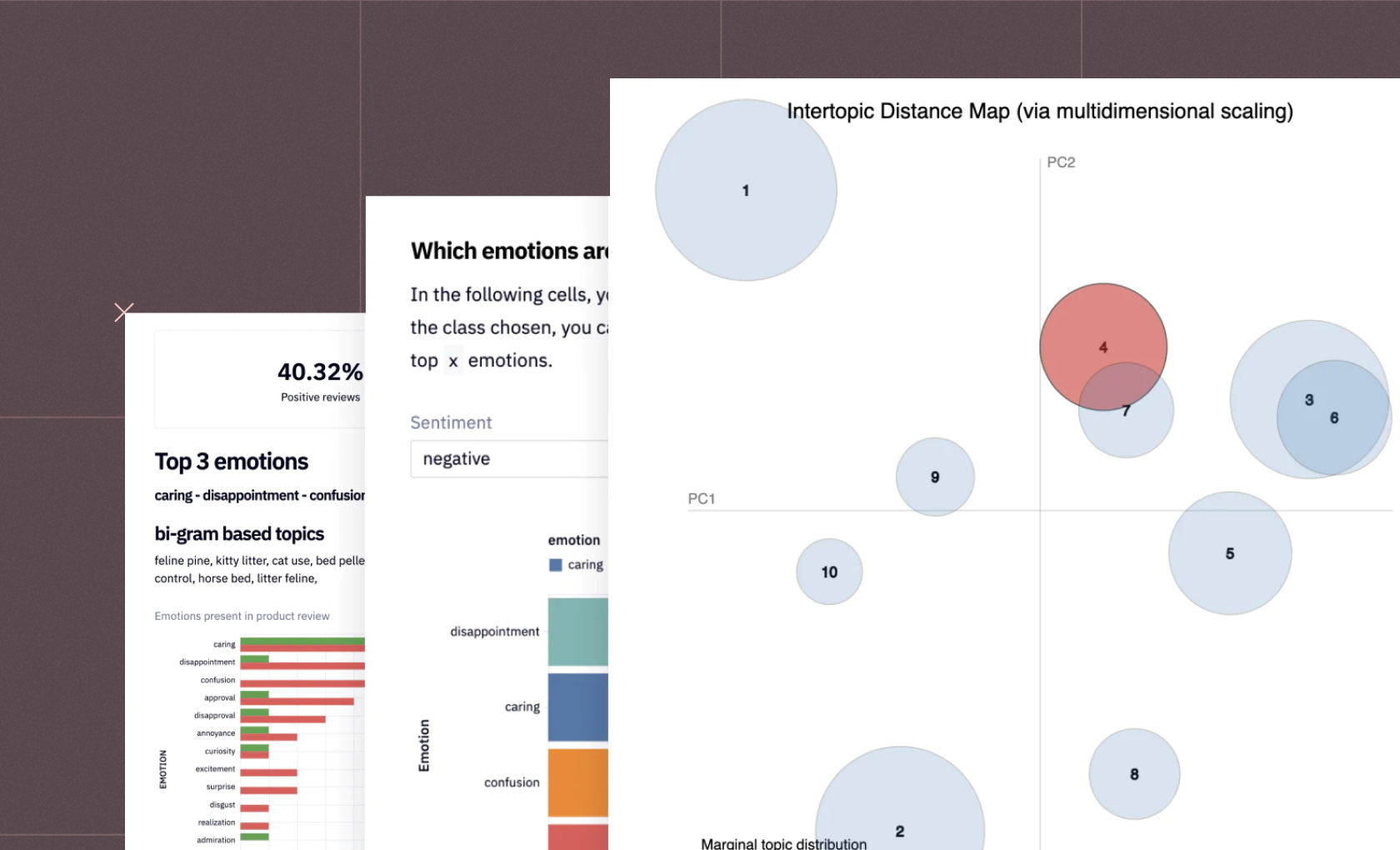
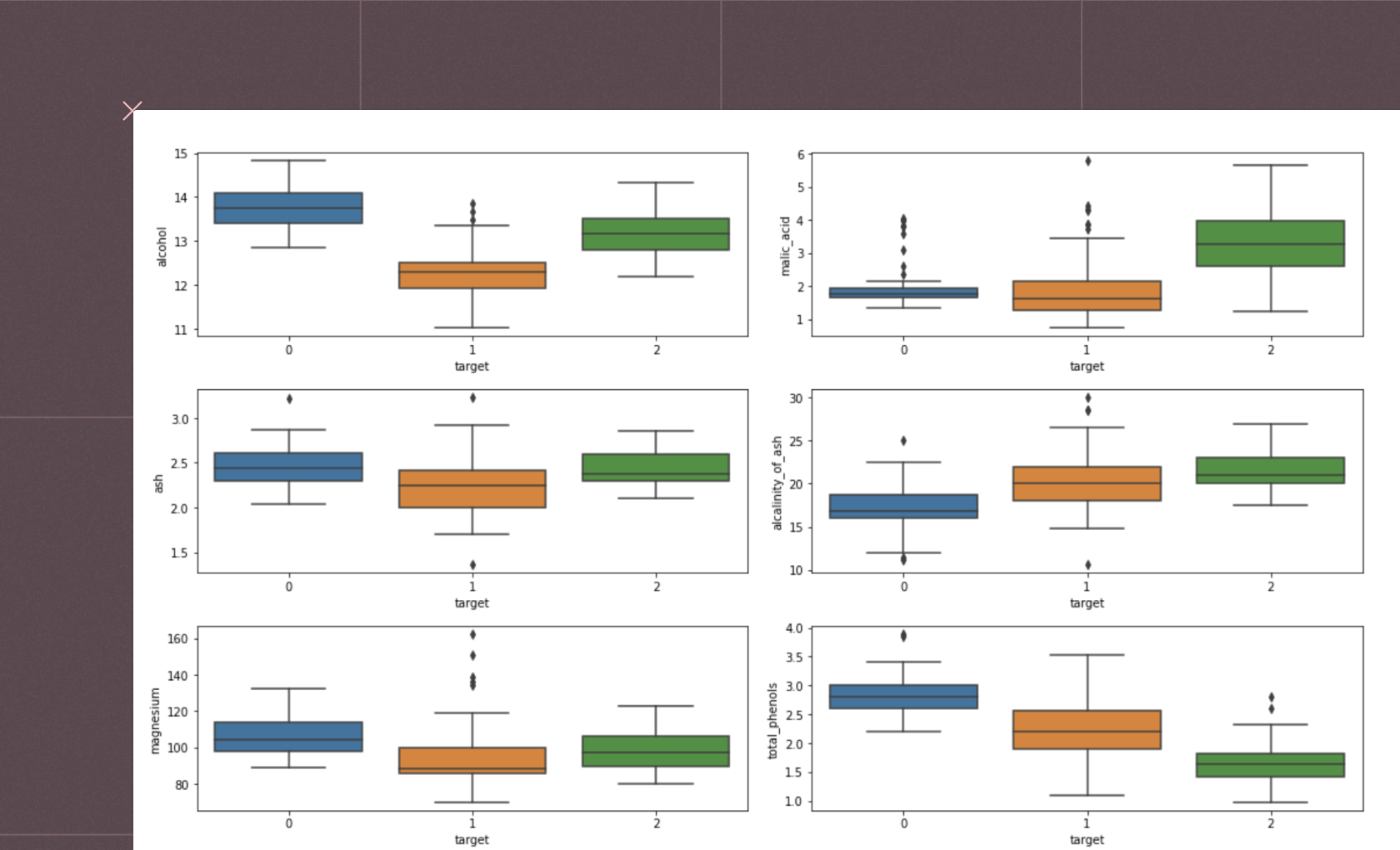
Finding the right number of clusters is crucial in clustering. Techniques such as the Elbow method, Silhouette analysis, and Gap statistic can help determine the optimal number of clusters.On this page, you'll find interactive examples demonstrating data clustering. If you see something interesting, click "Get a copy" to dive deeper and adapt any example to your requirements.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.
FAQ
Can't find your answer here? Get in touch.