Natural Language Processing

Izzy Miller
Building a natural language processing app that uses Hex, HuggingFace, and a simple TF-IDF model to do sentiment analysis, emotion detection, and question detection on natural language text.
How to build: Natural Language Processing
Natural language processing (NLP) is now at the forefront of technological innovation. The world is getting wrapped up in GPTs, Bards, and Anthropics. These deep-learning transformers are incredibly powerful but are only a small subset of the entire NLP field, which has been going on for over six decades.
With NLP, you can translate languages, extract emotion and sentiment from large volumes of text, and even generate human-like responses for chatbots. NLP's versatility and adaptability make it a cornerstone in the rapidly evolving world of artificial intelligence.
Here, we want to take you through a practical guide to implementing some NLP tasks like Sentiment Analysis, Emotion detection, and Question detection with the help of Python, Hex, and HuggingFace.
The Basics of NLP Preprocessing
Like any machine learning task, language data must go through a series of steps to achieve the desired state needed for the model building. This text preprocessing has several stages, with these as the most common:
Tokenization: This involves breaking down text into smaller elements like words or characters, known as tokens, which are easier for deep learning models to process. While there are various methods and tools for tokenization, such as NLTK, SpaCy, BERT Tokenizer, SentencePiece, and Byte-Pair Encoding (BPE), challenges can arise due to complexity, ambiguity, and special characters.
Text Processing and Normalization: After tokenization, unnecessary elements like special characters, stop words, and punctuations are removed to clean the text. Additionally, converting all text to lowercase aids in readability. The cleaned text is then subjected to stemming and lemmatization to normalize it to its base or dictionary form. Finally, the text is converted into numerical vectors through vectorization using methods like Bag of Words, TfIDF, Word2Vec, and GloVe, making it understandable to machine learning and deep learning models.
Part-of-speech tagging. Part of speech tagging is a necessary stage for different NLP-based models. POS tags different words in the text to different parts of speech, such as nouns, verbs, and adjectives. This way, it helps uncover the syntactical meaning of text.
Common NLP Tasks
What can you do with NLP? Truthfully, a lot. New models and paradigms are being deployed every day. However, the core NLP tasks remain the same.
Sentiment Analysis
Sentiment analysis evaluates text, often product or service reviews, to categorize sentiments as positive, negative, or neutral. This process is vital for organizations, as it helps gauge customer satisfaction with their offerings. Companies across various sectors, including sales, finance, and healthcare, can understand and improve user experiences by analyzing large volumes of customer feedback.
Question Answering
In recent years, question-answering systems have become increasingly popular in AI development. Instead of browsing the internet and sifting through numerous links for information, these systems provide direct answers to queries. Advanced models like ChatGPT and Bard exemplify this technology. Trained on extensive text data, they can respond to questions with accuracy and relevance that sometimes surpasses human capabilities.
Machine Translation
Machine translation is the automated process of translating text from one language to another. With the vast number of languages worldwide, overcoming language barriers is challenging. AI-driven machine translation, using statistical, rule-based, hybrid, and neural machine translation techniques, is revolutionizing this field. The advent of large language models marks a significant advancement in efficient and accurate machine translation.
Text Summarization
With businesses often dealing with vast amounts of unstructured text data, extracting meaningful insights can be daunting for human analysts. Text summarization addresses this challenge by condensing large text volumes into concise, relevant summaries. This technology enables a quick and efficient understanding of data, assisting businesses in determining its utility and relevance.
These use cases are just the tip of the iceberg; plenty of other NLP use cases are being applied daily across multiple businesses.
NLP and Deep Learning
Most NLP algorithms rely on rule-based systems, where, at some point, a human has to define different rules about language for the algorithm to use.
These can work well for simple examples, but language is rarely straightforward. For example, “Great, I am late again for the class” initially has a negative sentiment, but looking at the word great there is a high chance that rule-based models will classify it as positive.
The big breakthrough for NLP has been the rise of deep-learning models. Developers have deployed CNN, RNN, and its variants (LSTM and GRU) that perform well on complex tasks like text classification, generation, and sentiment analysis.
There are a couple of issues with these models, though:
They fail to capture the long-term dependencies in text.
They struggle to identify the context of words in a long sentence chain.
In the past few years, the attention mechanism has been the core insight into mitigating these problems due to its ability to capture long-term dependencies and the context of words in the sentence. Combining multiple components like encoder, decoder, self-attention, and positional encoding helps it achieve better results on NLP tasks. Large language models (LLMs) like ChatGPT, Bard, and Grok work on this concept.
It is resource-heavy to train the LLMs as you need vast amounts of data. A simple model with 1 Billion parameters takes around 80 GB of memory (with 32-bit full precision) for parameters, optimizers, gradients, activations, and temp memory. Usually, you use the existing pre-trained model directly on your data (works for most cases) or try to fine-tune them on your specific data using PEFT, but this also requires good computational infrastructure.
In this article, you will see how to utilize the existing models to test them on your custom dataset. We will use a platform called HuggingFace that contains many model architectures for NLP, computer vision, and other machine-learning tasks. This platform allows users to build, train, and deploy ML models with the help of existing open-source models. You can check a list of pre-train NLP models from HuggingFace here.
NLP with Hex and HuggingFace
Let’s implement Sentiment Analysis, Emotion Detection, and Question Detection with the help of Python, Hex, and HuggingFace. This section will use the Python 3.11 language, Hex as a development environment, and HuggingFace to use different trained models.
Install and Load Dependencies
Let’s start with installing the necessary dependencies with PIP as follows:
$ pip install pandas, numpy, matplotlib scikit-learn
$ pip install transformers
$ pip install nltk
$ pip install sentencepieceOnce the dependencies are installed, you can import them to the Hex environment as follows:
# NLP
import transformers
import nltk
import re
import string
# data manipulation
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
# other
from sklearn.utils import shuffle
import sklearn.metrics as metricsLoad Dataset
For this article, we will use the Amazon reviews dataset that is stored in the Snowflake warehouse. Hex provides connectors for different cold storage, databases, and warehouses to load and store the data. You can also upload the file-based dataset to Hex workspace. You can use the simple SQL statement to fetch the data from the warehouse and the result will be the loaded dataset in the DataFrame.
select * from "DEMO_DATA"."DEMOS"."AMAZON_REVIEWS"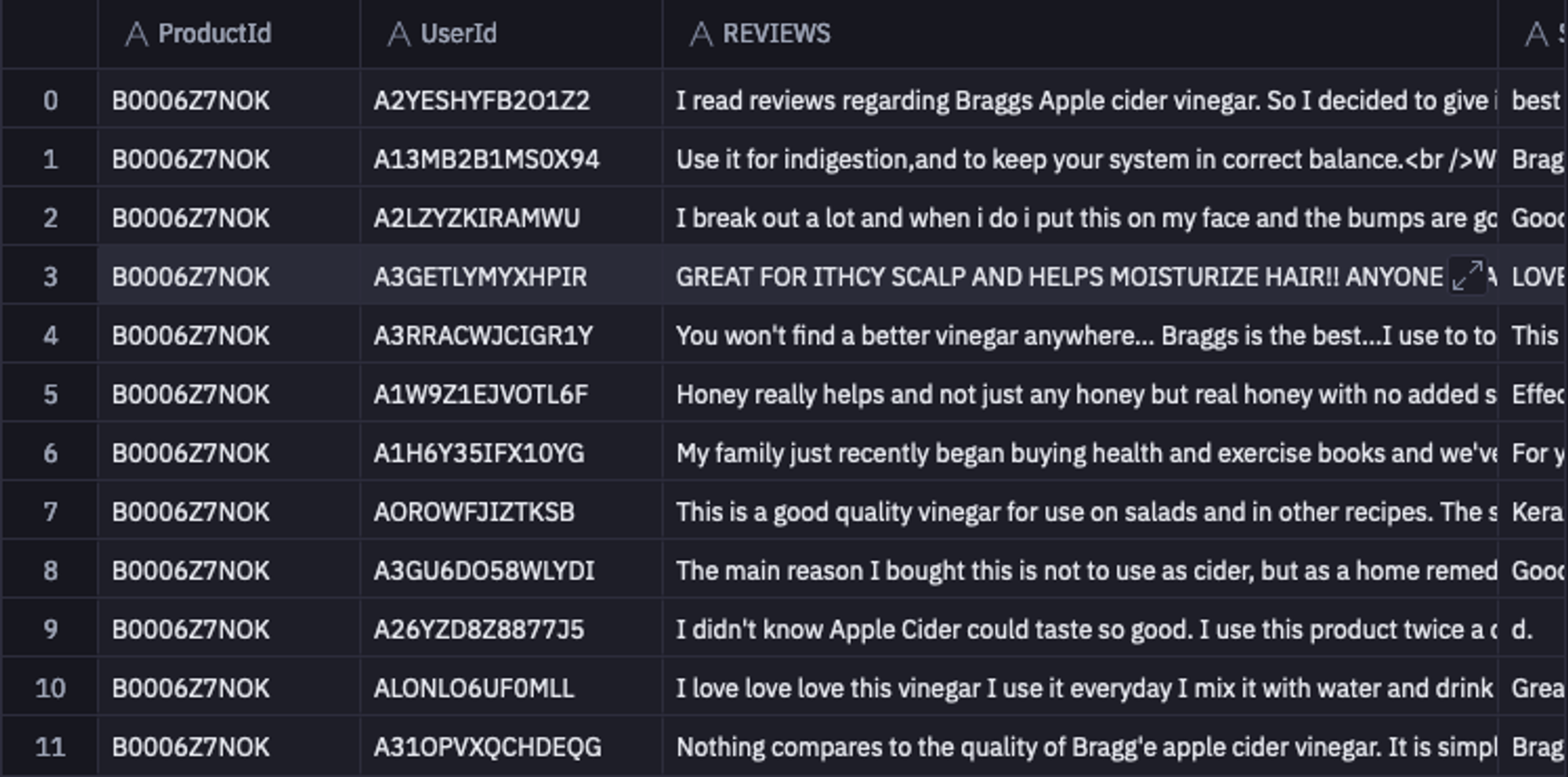
As you can see the dataset contains different columns for Reviews, Summary, and Score.
NLP Models with HuggingFace
Here are the models we are going to use:
We are going to use is a sentiment analysis model that classifies the user reviews into negative, positive, and neutral classes.
An emotion detection model that predicts the emotions wrapped in a text.
Finally, we will use a question detection system that will help us identify if the given text is a statement or a question posted by the user.
We will create a list of three models (from HuggingFace) so that we can run them together on the text data.
hugginface_model = [
"joeddav/distilbert-base-uncased-go-emotions-student",
"textattack/albert-base-v2-yelp-polarity",
"mrsinghania/asr-question-detection",
]Next, we will iterate over each model name and load the model using the [transformers](<https://pypi.org/project/transformers/>) package.
model = [transformers.pipeline(model=model, verbose = False) for model in hugginface_model]Next, we will create a single function that will accept the text string and will apply all the models to make predictions.
def call_model(models, text):
predictions = []
# for each model being used
for model, name in zip(models, hugginface_model):
# get the models prediction
prediction = model(text)[0]
# mapper used to make better labels
mapper = {
# if this model is chosen then the label LABEL_1 will be changed to Positive
"textattack/albert-base-v2-yelp-polarity": {
"LABEL_0": "negative",
"LABEL_1": "positive",
},
# if this model is chosen then the label LABEL_1 will be changed to Question
"mrsinghania/asr-question-detection": {
"LABEL_0": "statement",
"LABEL_1": "question",
},
}
# changes the predicted label (if required)
prediction["label"] = (
# label doesn't need to be changed
prediction["label"]
# label needs to be changed
if name not in mapper.keys()
else mapper[name][prediction["label"]]
)
predictions.append(prediction)
return tuple(predictions)In the above function, we are making predictions with the help of three different models and mapping the results based on the models. Finally, we are returning a list that comprises three different predictions corresponding to three different models.
For HuggingFace models, you just need to pass the raw text to the models and they will apply all the preprocessing steps to convert data into the necessary format for making predictions.
Hex provides an interactive environment where you can provide the variable values. Reading the value of the text variable will look something like this:
Let’s use the above function to make predictions on the text data.
# gets the results of calling the models
results = call_model(model,text)
v1 = results[0]['score']
t1 = results[0]['label']
# extract the label and the val
v2 = results[1]['score']
t2 = results[1]['label']
v3 = results[2]['score']
t3 = results[2]['label']You can use the beauty of Hex to present the results in appealing visuals as follows:
Now let’s make predictions over the entire dataset and store the results back to the original dataframe for further exploration.
# creating the dataset
preds = pd.DataFrame(columns = ['emotion', 'sentiment', 'grammar'])
try:
# loop through each review
for index, text in enumerate(reviews):
# get the sentiment, emotion, and grammar
model_predictions = call_model(model, text)
# print(f"{model_predictions}")
# save the predictions from each model in a variable
emotion_pre = model_predictions[0]['label']
sentiment_pred = model_predictions[1]['label']
grammar_pred = model_predictions[2]['label']
# add to dataframe
columns = [emotion_pre, sentiment_pred, grammar_pred]
temp = pd.DataFrame(data = [columns], columns = ['emotion', 'sentiment', 'grammar'])
preds = pd.concat([preds, temp], ignore_index=True)
# save dataframe every 1000 iterations
if index % 1000 == 0:
print(f"saving data {index}")
preds.to_csv('predictions.csv')
# This exception isn't best practice but is OK for our purposes.
except Exception as e:
print(e)
merged = pd.concat([frame, preds], axis = 1)
# for some reason, the dataframes seemed to not be aligned so I had to merge using the method below
preds_array = preds.to_numpy()
frame_array = frame.to_numpy()
data = []
for i in range(len(preds_array)):
data.append(np.concatenate([frame_array[i], preds_array[i]]))
final = pd.DataFrame(data, columns = merged.columns)
final.to_csv('predicted_reviews.csv', index = False)Running this code chunk will take a lot of time to complete as there are multiple rows of data. Once done the dataset will look like this:
select * from "DEMO_DATA"."DEMOS"."AMAZON_REVIEWS_SENTIMENT"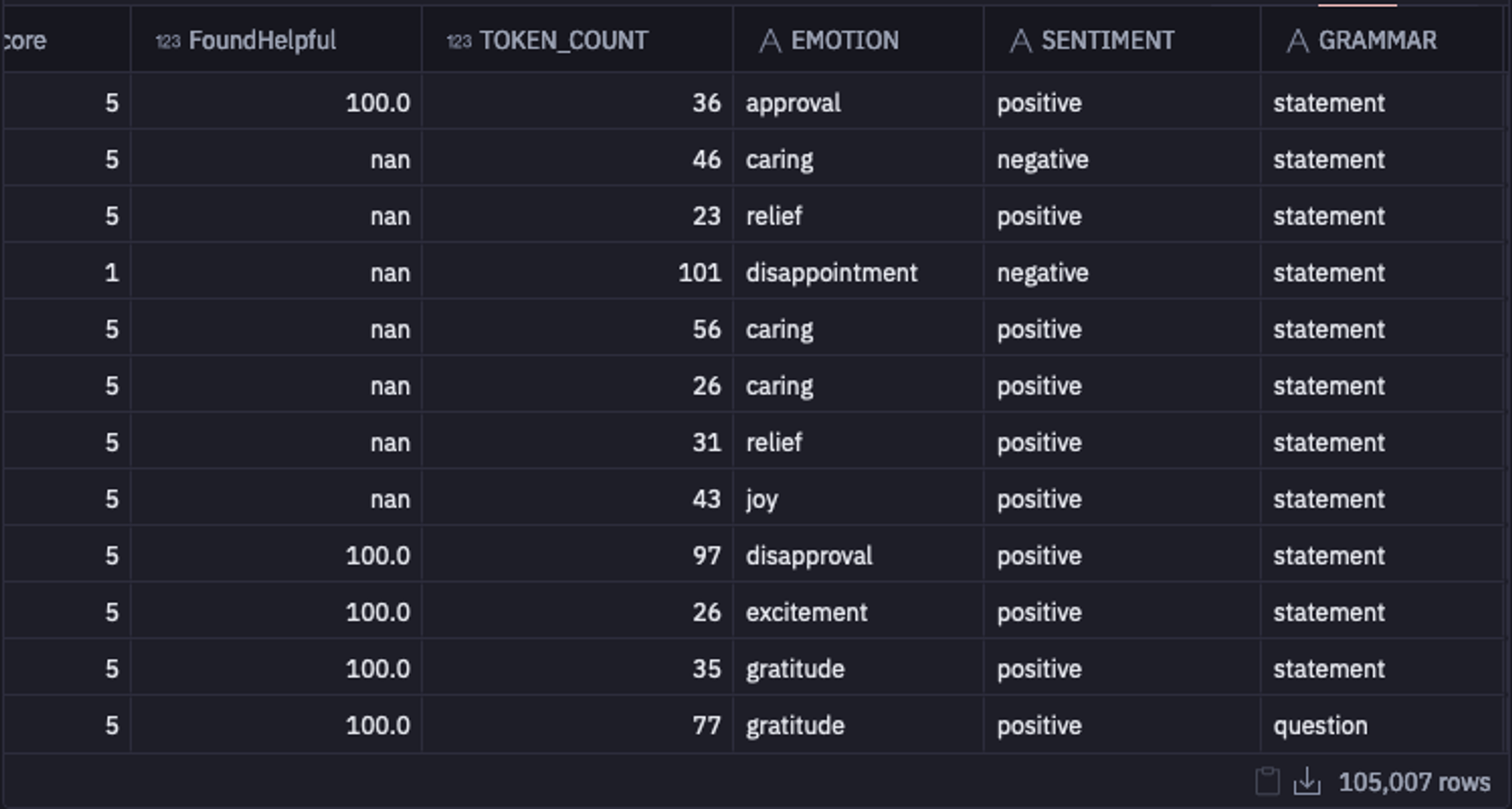
We will drop the duplicate data from this to remove the data redundancy.
final = final.drop_duplicates(subset = ['REVIEWS'])Now, let’s check the aggregate results of these predicted columns with the help of a simple SQL command:
select emotion, sentiment, count(reviews) as review_count from final
group by 1, 2
order by review_count desc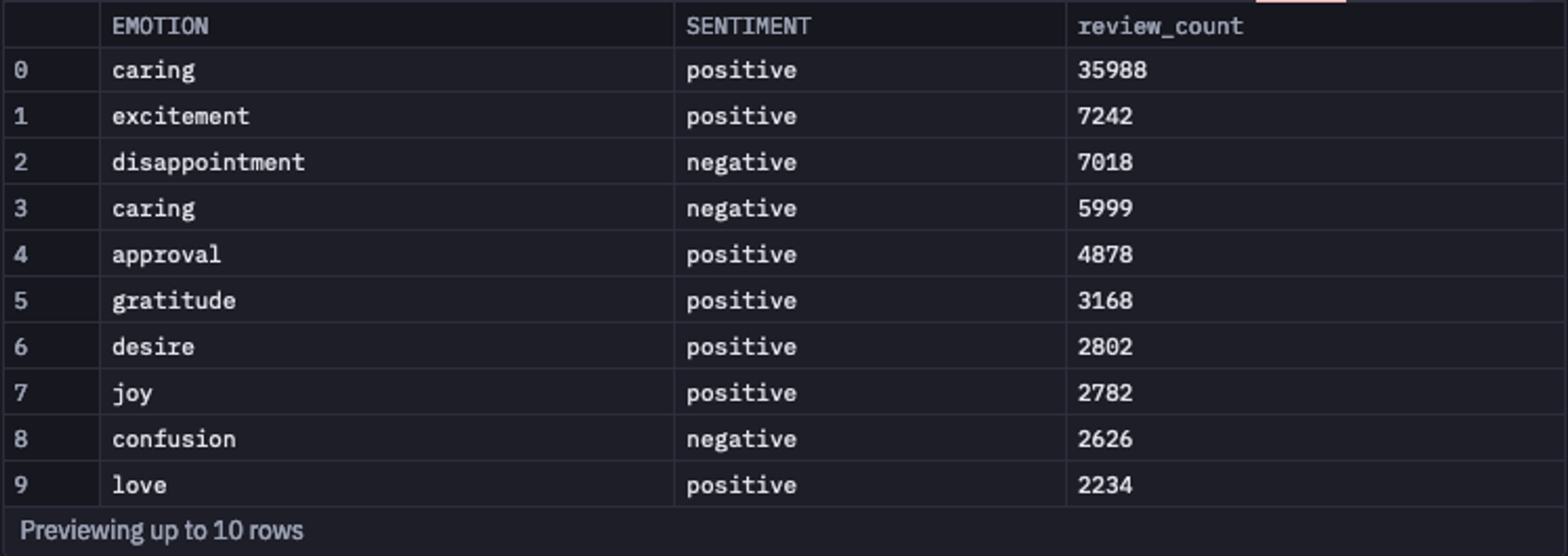
As you can see in the above image, the results make perfect sense.
Product Level EDA
Now let’s explore the individual products in the dataset. Since the product name is not given, we have no idea what each product is. To fix this, we will use a method called Term-frequency Inverse document frequency (TF-IDF) to extract possible topics, or themes from our reviews.
Let’s first select the top 200 products from the dataset using the following SQL statement.
select productid, count(reviews) as review_count from final
group by 1
order by 2 desc
limit 200Then using Hex, you can select the product ID and then filter out the data for that product.
product_data = final[final['ProductId'] == product][['ProductId', 'REVIEWS', 'EMOTION', 'SENTIMENT', 'GRAMMAR']]For the selected product, you can check the ratio of negative and positive sentiments and emotions associated with the product.
# get the percentage of positive and negative reviews
pos = product_data[product_data['SENTIMENT'] == 'positive'].shape[0] / product_data.shape[0]
neg = product_data[product_data['SENTIMENT'] == 'negative'].shape[0] / product_data.shape[0]
top_emotions = product_data['EMOTION'].value_counts()[:3].rename_axis('emotion').reset_index(name='counts')['emotion'].to_list()
Check Product Sentiment and Emotion
To identify the name of the product from the existing reviews, you use the TF-IDF. This method gives the count of each term in the document and conveys its importance. Generally, in a clean text, a high occurrence of words represents high importance. These words in a corpus (collection of documents) are referred to as a gram. The collection of two words is a bi-gram, a combination of 4 words is a quad-gram, and similarly, the collection of N words is an N-gram. We may extract information about the potential product from the reviews by applying TF-IDF across all of them.
Since we are not using any HuggingFace model for this, you need to write the code to clean the text. General cleaning steps are:
Removing the emojis from the text.
Removing unwanted information such as stopwords, special characters, user mentions, hashtags, and punctuation as they can increase the complexity of the analysis.
Removing the words that are in other languages. Focusing on one language will give us the exact information that we want as the other language words will have almost negligible occurrence.
Apply lemmatization and stemming to bring the words to their original form in the corpus.
The code for all these methods looks like this:
from sklearn.feature_extraction.text import TfidfVectorizer
import nltk
from nltk.stem import PorterStemmer, WordNetLemmatizer
import re
from sklearn.utils import shuffle
import string
nltk.download("stopwords")
nltk.download("wordnet")
nltk.download("omw-1.4")
normalize = lambda document: document.lower()
def remove_emoji(string):
emoji_pattern = re.compile(
"["
"\\U0001F600-\\U0001F64F" # emoticons
"\\U0001F300-\\U0001F5FF" # symbols & pictographs
"\\U0001F680-\\U0001F6FF" # transport & map symbols
"\\U0001F1E0-\\U0001F1FF" # flags (iOS)
"\\U00002702-\\U000027B0"
"\\U000024C2-\\U0001F251"
"]+",
flags=re.UNICODE,
)
return emoji_pattern.sub(r" ", string)
def remove_unwanted(document):
# remove html
document = re.sub('<[^<]+?>', ' ', document)
# remove user mentions
document = re.sub("@[A-Za-z0-9_]+", " ", document)
# remove URLS
document = re.sub(r"http\\S+", " ", document)
# remove hashtags
document = re.sub("#[A-Za-z0-9_]+", " ", document)
# remove emoji's
document = remove_emoji(document)
# remove punctuation
document = re.sub("[^0-9A-Za-z ]", " ", document)
# remove double spaces
document = document.replace(" ", "")
return document.strip()
def remove_words(tokens):
stopwords = nltk.corpus.stopwords.words("english") # also supports german, spanish, portuguese, and others!
stopwords = [remove_unwanted(word) for word in stopwords] # remove punctuation from stopwords
stopwords.extend(['like','make'])
cleaned_tokens = [token for token in tokens if token not in stopwords]
cleaned_tokens = [token for token in cleaned_tokens if len(token) > 3]
return cleaned_tokens
lemma = WordNetLemmatizer()
def lemmatize(tokens):
lemmatized_tokens = [lemma.lemmatize(token, pos="v") for token in tokens]
return lemmatized_tokens
stem = PorterStemmer()
def stemmer(tokens):
stemmed_tokens = [stem.stem(token) for token in tokens]
return stemmed_tokens
def pipeline(document, rule="lemmatize"):
# first lets normalize the document
document = normalize(document)
# now lets remove unwanted characters
document = remove_unwanted(document)
# create tokens
tokens = document.split()
# remove unwanted words
tokens = remove_words(tokens)
# lemmatize or stem or
if rule == "lemmatize":
tokens = lemmatize(tokens)
elif rule == "stem":
tokens = stemmer(tokens)
else:
print(f"{rule} Is an invalid rule. Choices are 'lemmatize' and 'stem'")
return " ".join(tokens)Now, you can apply this pipeline to the product DataFrame that we have filtered above for specific product IDs.
all_rev = product_data['REVIEWS'].apply(lambda x: pipeline(x)).to_numpy()Now it’s time to create a method to perform the TF-IDF on the cleaned dataset.
def get_tfidf_top_features(documents, n_top=8):
tfidf_vectorizer = TfidfVectorizer(
max_df=0.95, min_df=1, stop_words="english", ngram_range=(gram, gram)
)
tfidf = tfidf_vectorizer.fit_transform(documents)
importance = np.argsort(np.asarray(tfidf.sum(axis=0)).ravel())[::-1]
tfidf_feature_names = np.array(tfidf_vectorizer.get_feature_names())
return tfidf_feature_names[importance[:n_top]]The ngram_range defines the gram count that you can define as per your document (1, 2, 3, …..). Let’s apply this method to the text to get the frequency count of N-grams in the dataset.
overall_tfidf = get_tfidf_top_features(all_rev)This is it, you can now get the most valuable text (combination) for a product which can be used to identify the product.
You have seen the basics of NLP and some of the most popular use cases in NLP. You have also seen the evolution of models used for the same. Now it is time for you to train, model, and deploy your own AI-super agent to take over the world.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.
Ready to get started?
You can use Hex in two ways: our centrally-hosted Hex Cloud stack, or a private single-tenant VPC.