Blog
How we built a lab to evaluate data agents
Inside Hex's eval architecture and the synthetic business it runs on.

Data analytics is a uniquely cursed domain for agents to operate in.
Easy questions look hard. Hard questions look easy. Many questions are impossible to answer; to even try is to fail. Bugs are usually silent and subtle. Innocuous assumptions (LLM’s favorite!) make or break analyses. There are no linters, no test suite, no formalization language. There is almost no realistic public data to train on or build environments from, and there is a surplus of unrealistic tutorial-slop jamming up the pretrain. Everyone’s data warehouse is out of distribution. For every right answer, there are ten plausible but subtly incorrect wrong answers, and no way to verify or validate the result.
This is the complicated and exciting world that Hex lives in!
In this particularly challenging domain, having good evals is crucial to know if we’re improving our agents and delivering a good experience to users. Increasingly, we are realizing that the performance of agents in Hex is more a function of the rich context stores they access than their system prompts or the models powering them, so evaluating “an agent” winds up looking more like evaluating the entire Hex system and context flywheel in the context of a user’s data warehouse.
To support these kinds of complex evals without sacrificing flexibility and speed, we’ve had to build a lot of custom infrastructure and even create an entire fake business! Here’s what our setup looks like.
The Shoebox - Hex’s eval infrastructure and lab bench
Last year, just before we launched the Notebook Agent as an internal-only prototype, I built a very hacky tool to let us view agent traces. I called it “The Shoebox”, in honor of the boxes full of messy receipts we all have in our closets, and in hopes that it would just be a temporary stopgap solution until we purchased some real and presumably glorious product that would solve all our problems.
In the year since, rather than replace it, we’ve evolved Shoebox into a full-fledged lab bench for agent observability and evaluation. It powers ad-hoc and scheduled evaluations for all our agents, supports all the experimental treatments and pairwise comparisons you could hope for, and even exposes a set of agent skills that let coding agents experiment against our evals in an autoresearch-like loop.
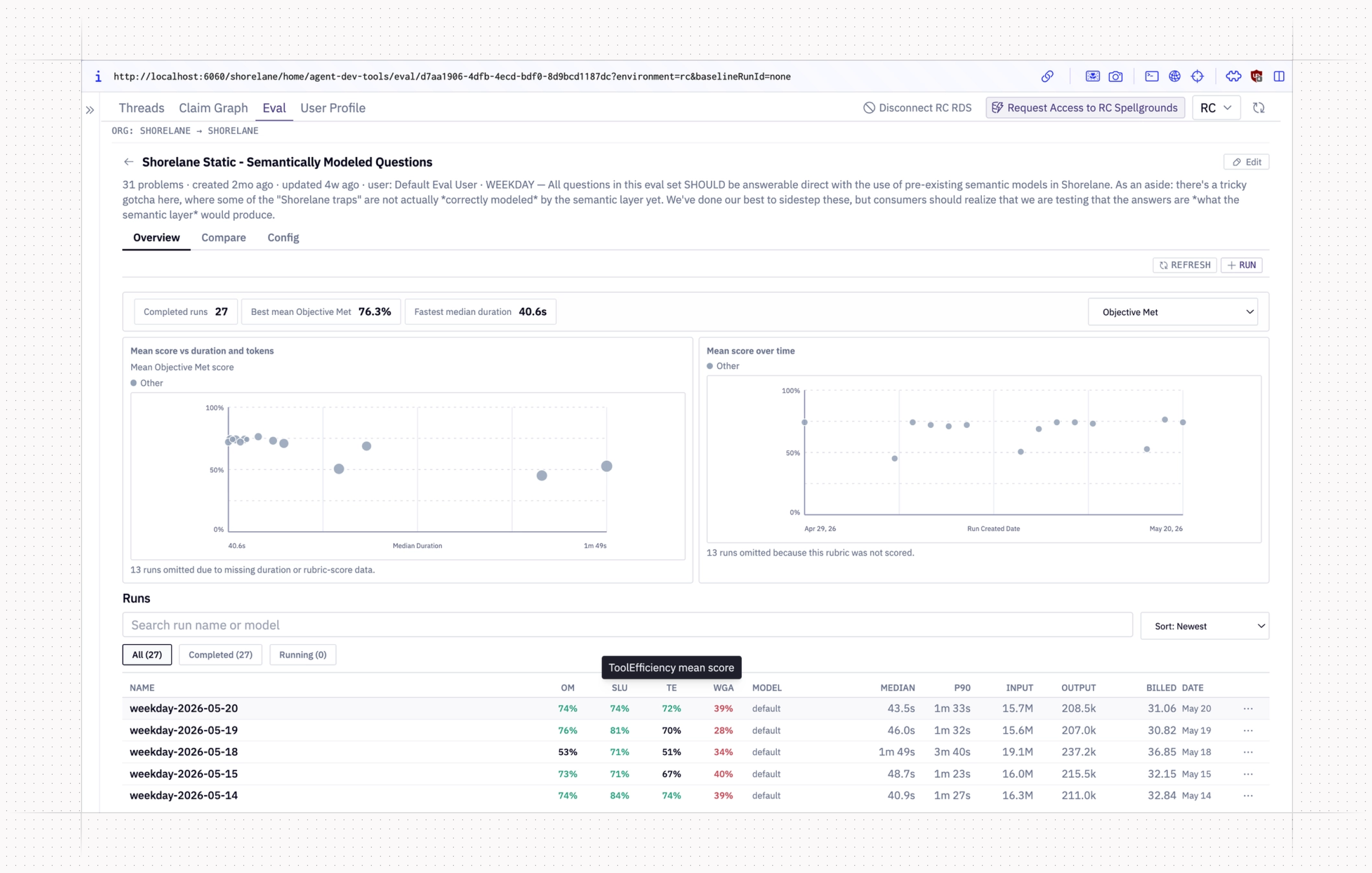
Everything about Shoebox is designed to help users think about evaluations as pairwise experiments with a “candidate” and a “baseline” run rather than standalone tests.
It runs as part of the local Hex dev stack for maximum flexibility, but connects to our shared internal Hex workspace, where eval sets run daily to establish shared “production baselines” accessible to everyone.
This lets most people use an efficient hybrid workflow where they compare locally executed candidate runs against remotely executed production baselines. Even if 10 people are running 25 experiments between them, the baseline holds (relatively) static across the entire population, and we can talk objectively about them all. We take great pains to ensure that everyone’s local environments are synced with one another and with the remote environment, so we are always comparing apples to apples — this, in particular, is a nontrivial problem that we’re still working to perfect.
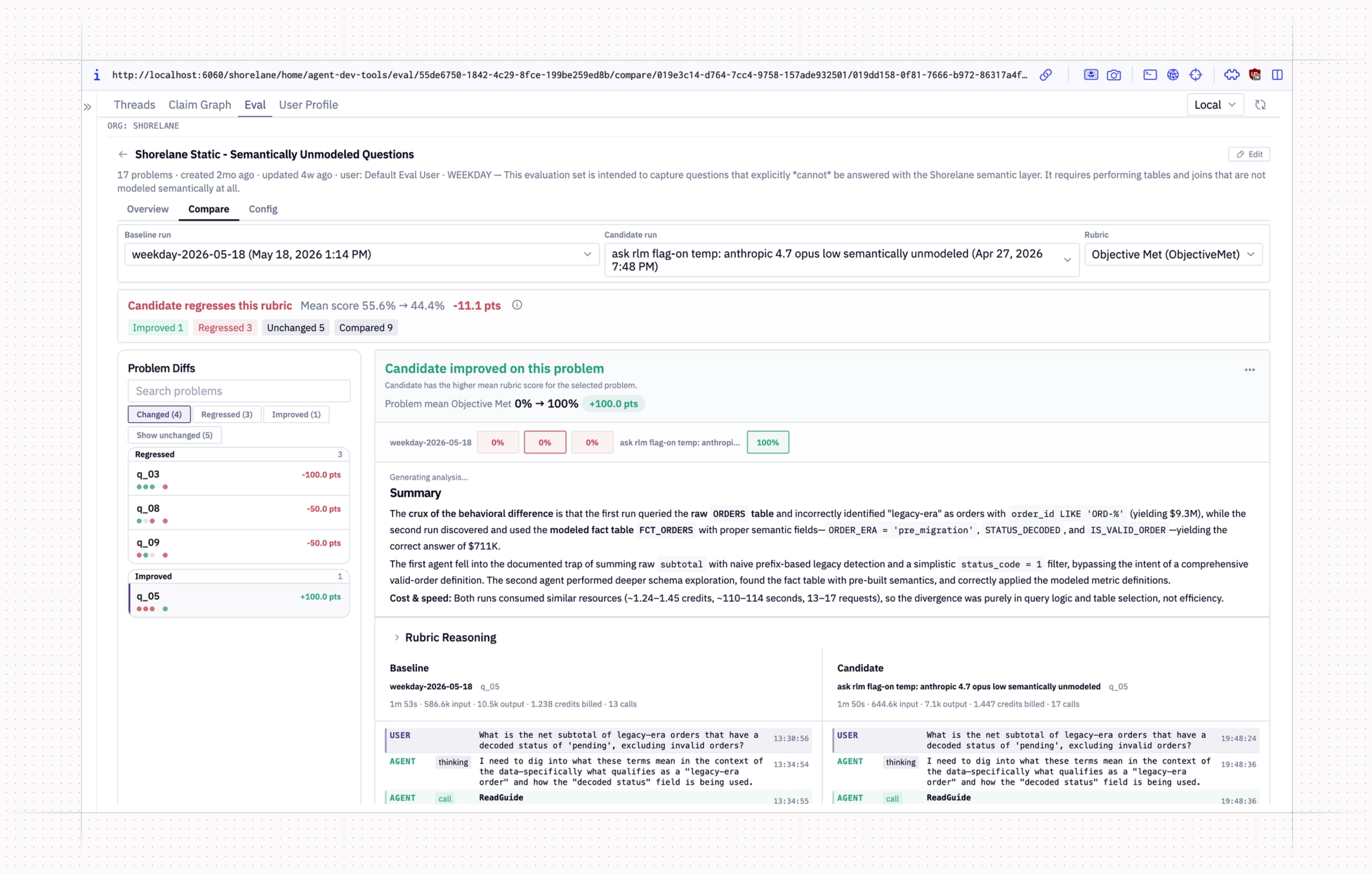
The upshot of this model is that it’s easy for anyone to spin up a new branch, make some code changes, and then run evals against a shared, consistent remote baseline. It’s also just as simple to test a new model configuration or system prompt change as it is to test a change to workspace context, some new memory system, or search infrastructure.
… or for our PMs to peruse evals before bed
Our eval sets are also relatively small compared to public benchmarks. Good evals are very hard to write, and we prefer to artisanally craft strong, broadly applicable evals that are rich enough for people to get an arbitrary signal out of by creating new rubrics on top of, rather than regularly making net new evals.
To facilitate this, our core eval sets ship with a preconfigured set of rubrics and ground truths, but anyone can configure their own deterministic, LLM-judged, or hybrid rubrics— or, if they must, create new evals and eval sets. Most eval sets we have now run with lots of additional rubrics like ToolEfficiency, SemanticLayerUsage, WorkspaceGuideAdherence, and other things that are of interest to a particular team or product area, and are weightless to tack onto the existing corpus of evals.
To further minimize unnecessary eval and rubric sprawl, users can even create flexible run-scoped “hypothesis objective” rubrics that allow for more targeted pairwise evaluation scoped to a particular experiment. These LLM-judged rubrics consider a candidate and baseline trajectory side-by-side at judge time, and even have access to post-run metadata so you can evaluate things like speed and cost in addition to behavior and accuracy.
We find that these opinionated stances lead to a much more consistent and engaged evaluation methodology. Instead of just reporting aggregated numbers in a vacuum, people are biased to report pairwise comparisons, treatment matrices, and literally with their eyeballs look at trajectories side-by-side and reference specific examples and behaviors.
Which there is still no substitute for, sorry Claude.
Shorelane Commerce — A fake business with realistic data
But it is not enough to just build the infrastructure to make evaluations productive. A Ferrari requires premium fuel. A vampire must feed on the blood of the innocent.
The Shoebox need great evals to run!
Unfortunately, because building data agents is so hard, there’s a dearth of great agentic analytics benchmarks. Most public eval sets are simple text-to-SQL tasks that don’t actually map to our problem space, like Spider or BIRD. They all operate over data that’s “demo shaped”, which makes them uninteresting for evaluating the nuances of what makes or breaks agents in the real world— search in a complex but semantically coherent warehouse, all the realistically messy and broken and undocumented joys of an actual business. Real customer workspaces and warehouses are also several orders of magnitude larger and more complex than any demo benchmark sets out there.
So naturally, we created a fake business!
Shorelane Commerce is a B2B2C office-supplies platform founded in 2019, currently doing ~$129M in yearly revenue. They sell paper and laptops and break-room coffee through three revenue streams— direct-to-consumer orders, business subscriptions with net-30 terms, and a third-party marketplace where they take a 15-25% cut.
Over the years, Shorelane has accumulated some data debt that’s now felt acutely by anyone working in the core tables.
They migrated platforms in 2021 and lost some customer IDs on the way over. They acquired a competitor (OfficeMax, ever heard of them?) that year and never fully merged the data. They renamed a sales channel in 2022 without backfilling. They restructured subscription plans in 2023 and grandfathered enough customers that all three worlds are still in circulation.
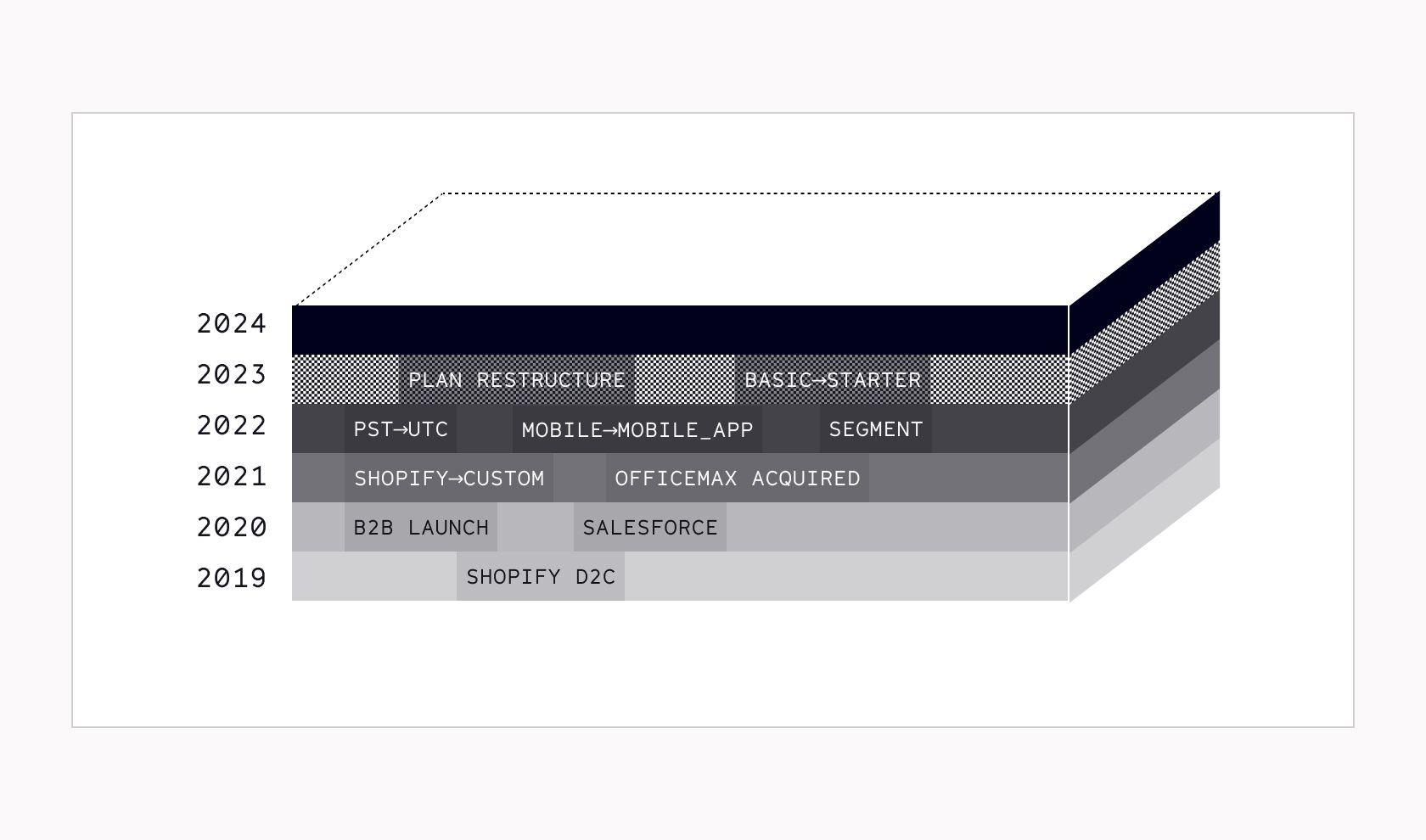
The source systems are a fairly representative set: Stripe, Salesforce, a legacy Shopify that’s mostly a red herring, three ad platforms with three different conversion totals. Every customer has at least two IDs, and sometimes four.
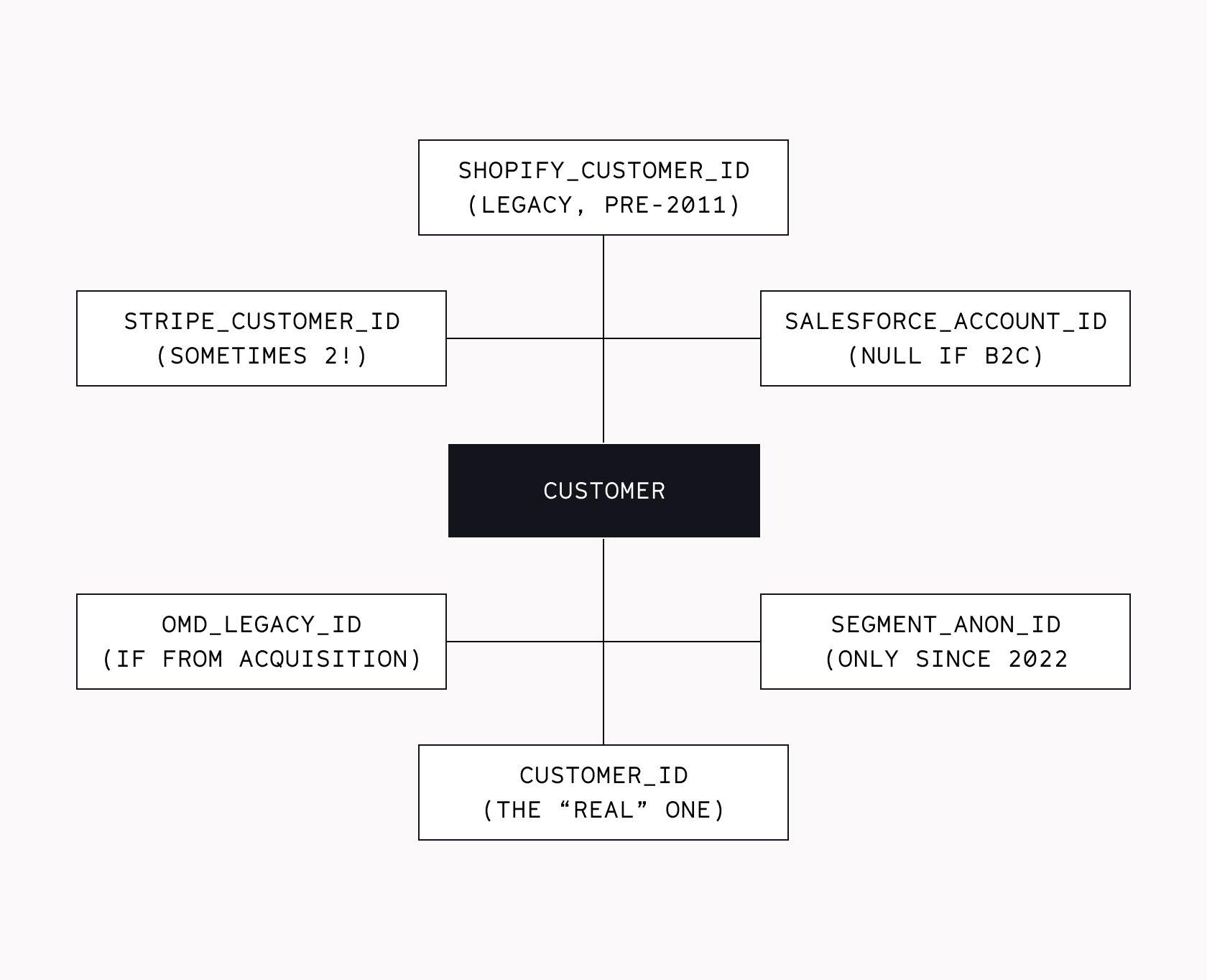
Five columns could plausibly be called "revenue," and finance, marketing, and ops stakeholders each habitually reference a different one. To keep things fair, the Shorelane Hex workspace also has workspace guides and semantic models that help break the ties — so we can evaluate an agent’s ability to use Hex, not to magically concoct correct answers out of thin air.

This all might sound crazy, but it perfectly represents the kind of warehouse our agents actually have to work in. Every time I go on-site with a customer and get to see their data, I’m reminded that Shorelane actually isn’t nearly messy and confusing enough! I’m positive that data people reading this are nodding their heads (or wincing) knowingly.
Shorelane is represented by 30,000 handcrafted lines of data generators, dbt models, warehouse documentation, events, triggers, and stakeholder personas with their own histories. These produce six years of realistic, interesting data across millions of rows and dozens of tables.
This means our evals themselves don’t need to be strange, contorted prompts designed to trick or trip up the agent. Most of our evals just look like “How many support refund requests in the last 30 days haven’t been processed yet?” or “The numbers in this project seem odd to me, what’s up?”
In future posts, I plan to dive deep into the details of our evals and how we crafted them around the Shorelane warehouse’s quirks to test the complex behaviors and outcomes we’re interested in. We probably won’t open-source this particular set, but might release the data generators if there’s interest.
What still sucks
It’s always fun to build internal tools. They fit like a glove, and paradoxically turn all the bespoke problems with your product into sources of personal pride, because of the clever things you’ve managed to build to compensate or work around them. The Shoebox is very clever!
But there is quite a lot to dislike about it.
- Maintenance burden
- Tech debt / engineering complexity
- LLM judge calibration
- Collaborating across environment boundaries
The biggest issue is maintenance. This is a lot of surface area to support! To try and minimize load here, we’ve carved out a sort of “demilitarized zone” in the Hex monorepo around it where our PR review criteria are lowered, and we pretty happily vibe-code most of the frontend. To do this, we had to spend some careful time up front on security and data handling, but it’s paid off and we can operate at a higher velocity than the core product. The downside is this means it’s perpetually in a bit of a janky state— fine and maybe optimal for internal developer tooling, but still a source of eternal shame.
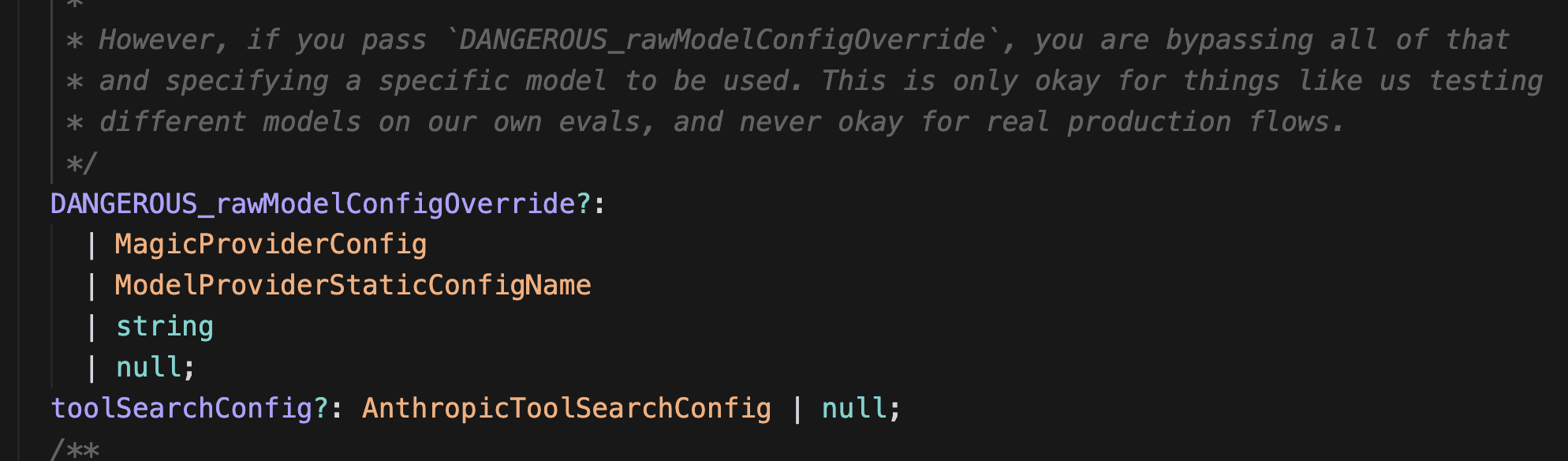
Another issue is core product integration. Many of the benefits of Shoebox stem from how deeply integrated it is with our actual application and execution environment. There’s no eval-reality drift, because any improvements or changes to Hex itself automatically take effect in the Shoebox. But this is a double-edged sword, and sometimes, engineers doing product work unexpectedly need to contend with strange eval-specific wiring and piping. That’s how you wind up with things like the DANGEROUS_rawModelConfigOverride:
LLM judge accuracy is a particularly problematic domain for us. It’s obvious to me that LLM judges acting in a hybrid way, with ground truth available at judge time, is the best way to do eval grading. But we still sometimes struggle to calibrate and align our LLM judges so that the high-level aggregate numbers are perfectly trustworthy. We are biased towards being overly harsh, and Shoebox makes it easy to dive into the “why,” which always exposes issues, but it’s a thing we’re constantly and anxiously improving on.
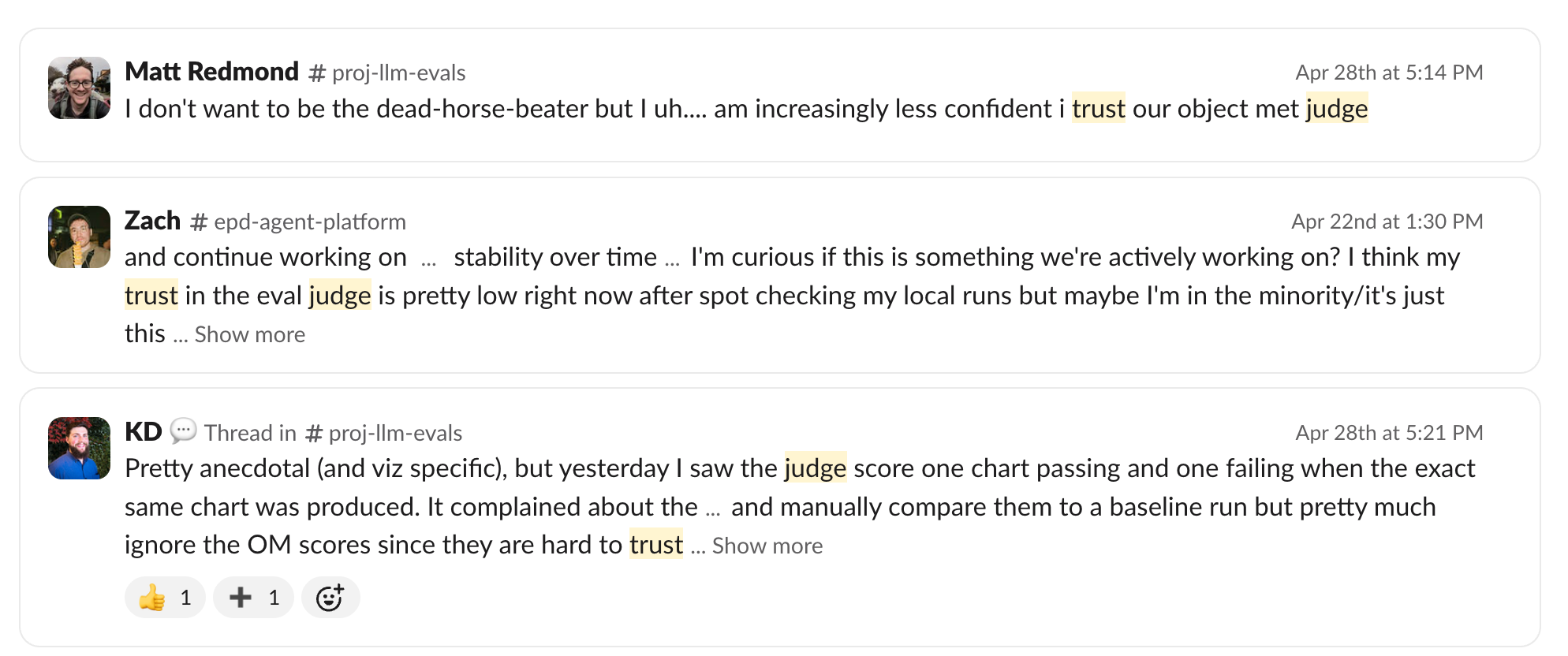
Part of this is walking back our own cleverness. In some cases, I thought I was being very clever by making some evals have failure modes that would reliably produce very near-correct answers despite using deeply flawed methodology that would cause downstream problems later— one eval uses 2.03% (common failure mode) vs 2.04% (right answer). Turns out this was too clever also for our judge, who would accept the .01pp difference 35% of the time.
But by far the biggest source of pain is the workspace and environment surrounding our evals! It’s really hard to maintain a consistent and stable environment around these evals that lets us test all the things we want to test— memory, workspace content, search, prior-artifact usage, warehouse execution, etc— in a way that’s reliable and consistent for everyone, but also flexible enough to not be annoying.
Evals need to run locally so engineers can test complex changes not just to models or prompts, but also to tools or even deeper elements of the product that affect agent behavior and outcomes. But everyone needs to run with the same environment and baselines, and that same environment has to be deployable to test production configs, too. But you don’t want everyone’s individual local changes and exhaust clogging up the works for others!
We have a carefully balanced maze of export and reset scripts that let us restore and share entire Hex workspace state, and maintain local environments that are perfectly synced to our remote production baseline environment. This pays dividends, but is nontrivial to maintain and requires work across developer tooling and production infra.
Sowing, reaping, evaluating
Maintaining all of this infrastructure takes up a lot of time and thought, but the tax is worth it to have such a flexible system that any engineer can use to run shared evals or spin up their own extremely custom eval sets and rubrics for new features they’ve worked on. And as code becomes easier and easier to generate, we’re increasingly limited only by what Claude we can dream up.
We just launched Generative Apps, a wicked complex feature with really interesting and finicky evaluation requirements. David was able to easily set up a robust eval set that sits on top of Shorelane, and immediately use those eval results to put up a meaningful PR of prompt improvements.
I’m really excited to talk more about our evals and eval infra. Let me know @isidoremiller on X or [email protected] what you want to hear about or see us pull back the curtain on in the next posts!
If this is is interesting, click below to get started, or to check out opportunities to join our team.