A simple question: “How many customers do we have?”
What’s hard about data is that answering even simple questions can require a substantial amount of tacit organizational knowledge.
The old way was to have the data team explicitly define everything before anyone could ask a question. This mode of thinking is dead; it’s a huge bottleneck, and we need something much more automated.
We actually need self-learning context
Everything discovered during analysis has the potential to be leveraged in future analysis. The clarification a user offers mid-Thread, quirks about a column an analyst learns to work around, and definitions that change when a new product feature launches.
Our vision for context in Hex is that it compounds: that Hex gets smarter every time you use it.
So, today we're launching Context Suggestions: actionable context improvements generated automatically from the conversations and analyses already happening in your workspace. Every Thread becomes a chance to sharpen what the agent knows.
The self-learning flywheel: Users, Data Agents, and Review Agents
Data agents enable an unprecedented scale of questions to be answered, and we need a new way to handle that scale. The answer is not manually building semantic models before anyone can get an answer. Instead, we built a system where Hex automatically learns definitions from discoveries made by agents and humans.
Every time a user interrogates their business data with a data agent, a Review Agent analyzes the corresponding conversation. It parses through the data agent’s thinking messages, generated code, and outputs to discover reusable context through the data analysis process.
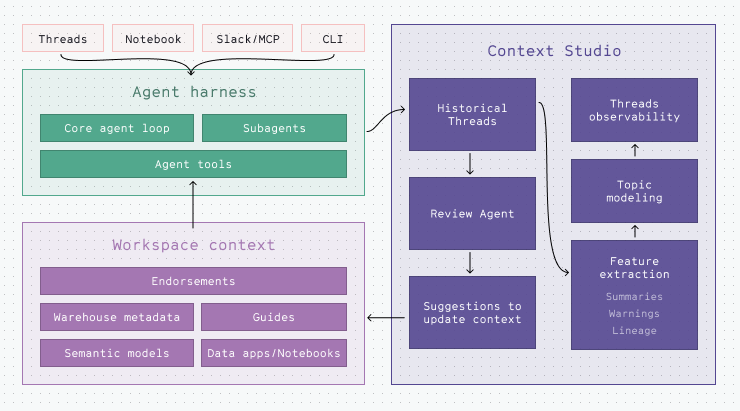
You can observe the Review Agent’s work in Context Studio. It extracts several key components that enable continuous learning inside Hex:
- Summarization with tool calls and references - The Review Agent extracts summaries of the Thread, builds a timeline of the conversation exchange, and extracts data assets used in answering questions.
- Topic tags - Conversations are clustered into topics and areas of interest specific to an organization.
- Warnings - Flagging moments in the conversation where there is agent uncertainty, a user issues a clarification, or the agent notes missing context are identified and categorized
The Review Agent then continually synthesizes all of these signals, clusters them into issues worth resolving, and opens a PR against your context with specific changes to help resolve the issues detected in prior conversations.
We call these Suggestions.
The solution to scale means enabling users to conduct novel analysis with the data agent, pushing the boundaries of the existing context. Then, using review agents and LLMs to review the work done to improve the system in a loop.
Discover emergent data topics
The first job of this system is to surface what users are asking about. Each agent interaction has valuable context embedded in it, begging to be turned into signal for data teams.
Hex created a context pipeline that automatically:
- Extracts a summary of your user conversations in Threads
- Creates a timeline and all of the data assets used to answer their questions
- Clusters these conversations into topics specific to your organization
This allows data teams to see new trends of what is being asked in the organization.
Meet Hannah, data lead at PandaDoc. Her data team noticed an emerging trend in data usage: people were asking about document downloads, a new feature alongside their document-signing services. The challenge was that the agent had no idea what document downloads meant, guessing at what tables and finding some tracked analytics events that could help support the answer.
Hannah was able to dig into this emergent area of the business before anyone had even asked the data team about it. The data team was able to make their own judgments about exactly which events to use for document downloads and plan the documentation and modeling work needed to improve answers for these types of questions in the future.
Flagging areas for improvement
When agents can surface trending topics, data teams can spot what we call emergent metrics. Things the data team could not anticipate. The agent made some assumptions, and this is where online evals can come in as an early warning for questions that aren't sufficiently defined.
The old way for data teams to understand quality was to rely on users explicitly clicking “thumbs up” and “thumbs down” on Threads. We learned this wasn’t a particularly good signal; instead, agents reviewing Threads was a far better measure of agent quality and guaranteed review coverage.
Now, Hex automatically evaluates every Thread for quality. We’ve worked with dozens of development partners to determine which evals provide the strongest signal for data teams to improve agent trust.
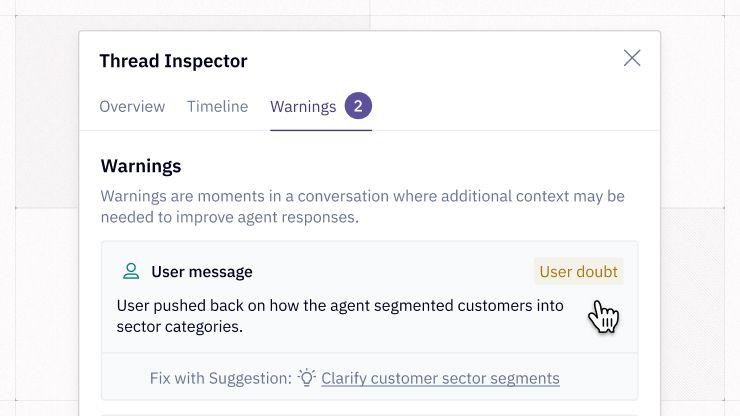
We run three core evals on each Thread:
- Context gaps - flags missing data where the agent was unable to answer all or part of a question. This is desired agent behavior; it’s good when the agent says it doesn’t know! These are critical signals for understanding gaps in coverage.
- Data limitations - captures Threads where the agent was able to respond but acknowledged incomplete or partial coverage. For example, it might say "this metric may not account for external API events." Unlike context gaps, the agent returns an answer, but caveats it in ways that indicate gaps in the underlying data model or missing definitions.
- User doubt - oftentimes, users will explicitly correct the system and offer it guidance. In the previous example, a user might say, “Oh, I don’t want downloads from emails, just from the UI.” This is one of the most important signals and feedback to the agent about how to improve future behavior.
The evals return Warnings. A long Thread where the user struggles to find the right answer might have several Warnings of mixed types flagged at specific points in the conversation. If the agent found the question straightforward to answer based on the available data and context, there will likely be no warnings at all.
Automated context suggestions
The agent has identified gaps in your context, sized the impact, and now we have to fill them. This process used to involve someone on the data team creating an update for a guide or semantic model from scratch. Hex’s agents help kickstart this work as well, suggesting specific changes you can easily accept or use as a starting point in your own workflow.
Instead of a data team member reading hundreds of individual Threads along with their tool calls and Warnings, we give you a feed of Context Suggestions you can sort and explore.
In each suggestion, the Review Agent surfaces a unified problem statement directly to the data team:
- The evidence - the representative Threads that show the underlying issue.
- The eval generated Warnings - the signals that triggered this cluster (user doubt, inconsistent definitions, missing context)
- The data assets that were used - and the ones that were conspicuously not used
Based on the problem statement, the Review Agent drafts a specific change to improve your context. These Context Suggestions mean your team isn’t guessing at what changes will improve agent responses.
Depending on the shape of the problem, it might suggest changes to:
- A Guide — a markdown document that defines the organizational logic or explains edge cases. It could give the agent explicit decision rules (e.g., "we never use email metrics on the product team").
- A semantic model update — when the definition is stable and should become a first-class KPI in a semantic model.
- Metadata improvements — column or table descriptions, for when the agent is going off-road and making the wrong assumptions.
These are changes you can review and merge like any other piece of work. The data team stays in control; the agent just does the legwork.
Context that compounds
We’ve come to the conclusion that any chatbot for data that doesn’t have a context platform powering it will feel pretty quaint. Users are going to ask questions that the agent has no way of answering, data teams are going to create analyses that are never used, and context projects are going to take months or years and be outmoded before they’re even rolled out.
Instead of constantly being worried about giving more people access to data because they create risk and governance problems, what if you were excited to give people access to data because they were going to innately make the system smarter? The more questions people ask, the more context is created, and Hex is designed to take that context and put it to work.
Every Hex surface has access to the same context. We have a broad environment with the ability to create dashboards, offer conversational insights for business users, and deep data science capabilities for more technical analysts. All of those surfaces should be able to talk to each other - when an analyst develops a new model, it should be accessible and referenceable by your conversational system. When an analyst kicks off a new analysis, they should be able to see which metrics are already defined in the model. This way, you end up with a set of answers that all feel connected, not a mess of differing opinions.
If you’re looking at agentic analytics tools - give us a try and see the difference.
If this is is interesting, click below to get started, or to check out opportunities to join our team.