Blog
We had to build new evals for Fable
Claude Fable 5 is the first model since Opus 4.5 to meaningfully improve at analytical reasoning

Today Anthropic is releasing Claude Fable 5, the first publicly available Mythos-class model. It’s the first model in a long time that we’ve felt is a step change on the kind of tasks we care about— difficult data analysis in complex, realistic (read: broken & messy) warehouse environments.
We’ll be rolling out Fable in Hex this week (although it requires a pre-step for admins to enable – see more below).
The first model in a long time that feels like a step change
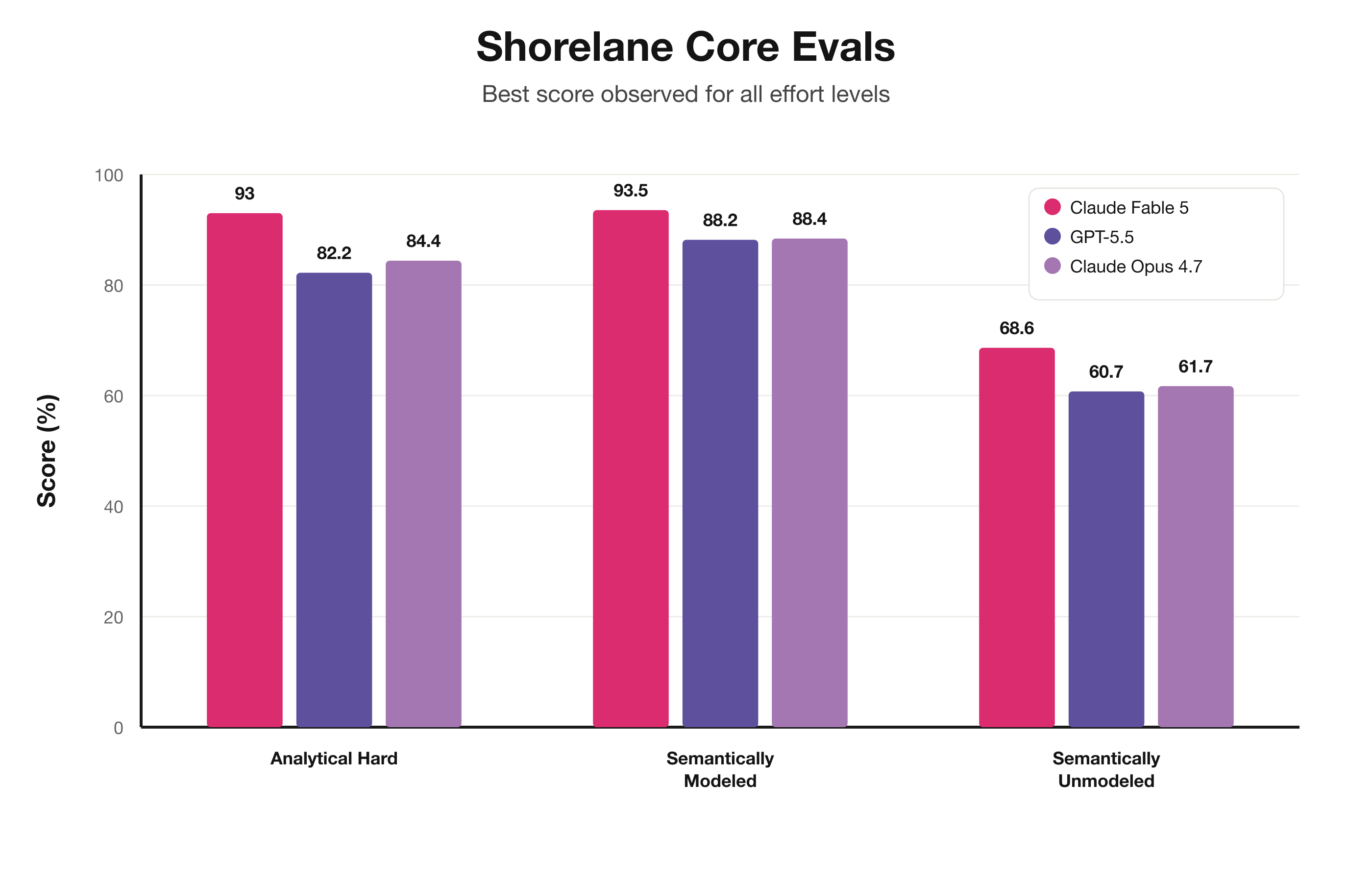
Fable performs very well on our standard set of analytical evals.
Claude Fable 5 (high reasoning) scores 93% on Analytical Hard, 93.5% on Semantically Modeled, and 65% on Semantically Unmodeled, which is approaching the realistic single-turn ceiling for that set.
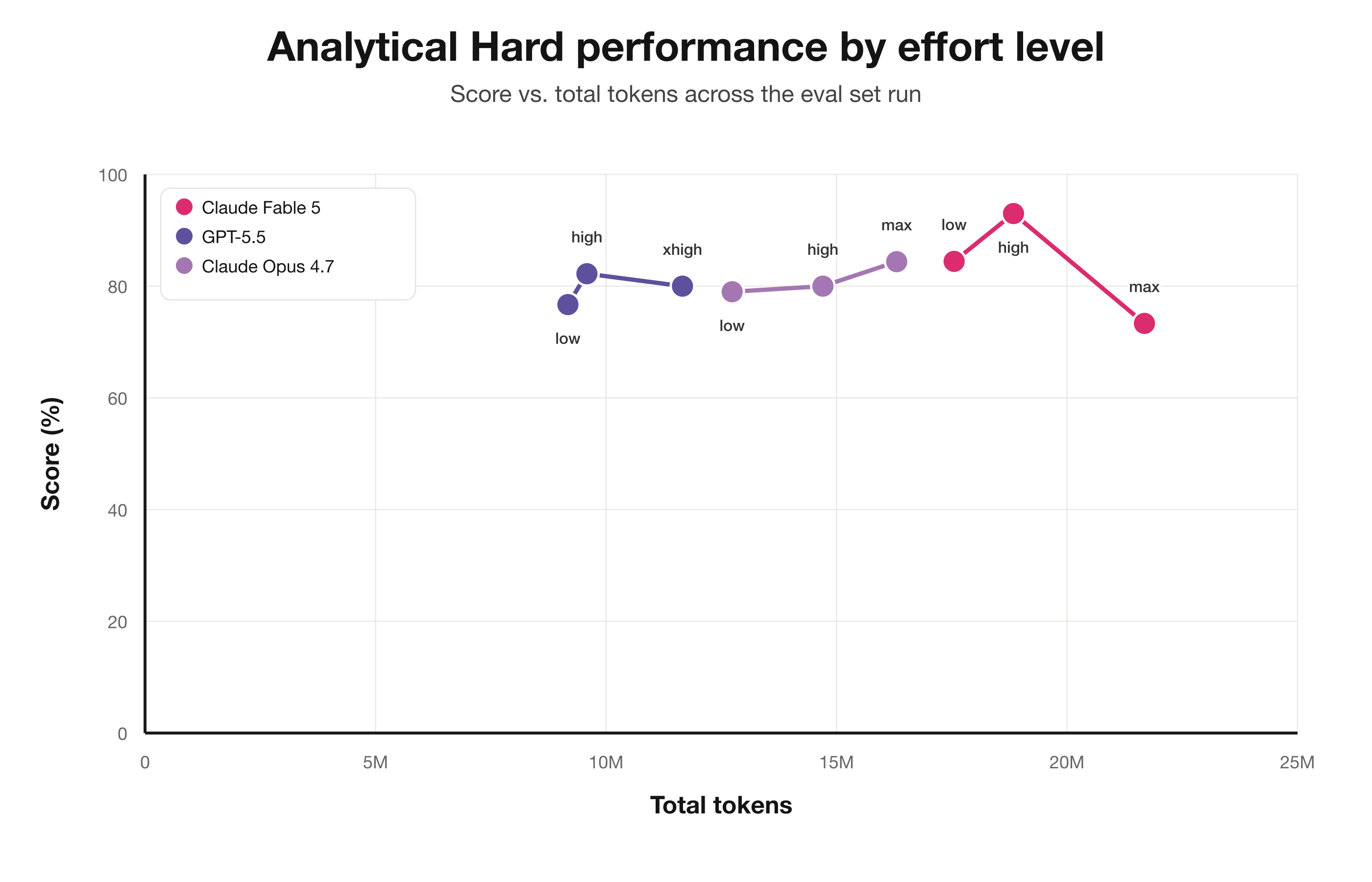
Interestingly, on some of our non-frontier tasks (more on what this means later), we note a performance decrease on Max effort. On these shorter horizon tasks, max effort seems to occasionally lead to overthinking behavior that causes the model to overly second-guess itself and ultimately perform worse in a small number of cases.
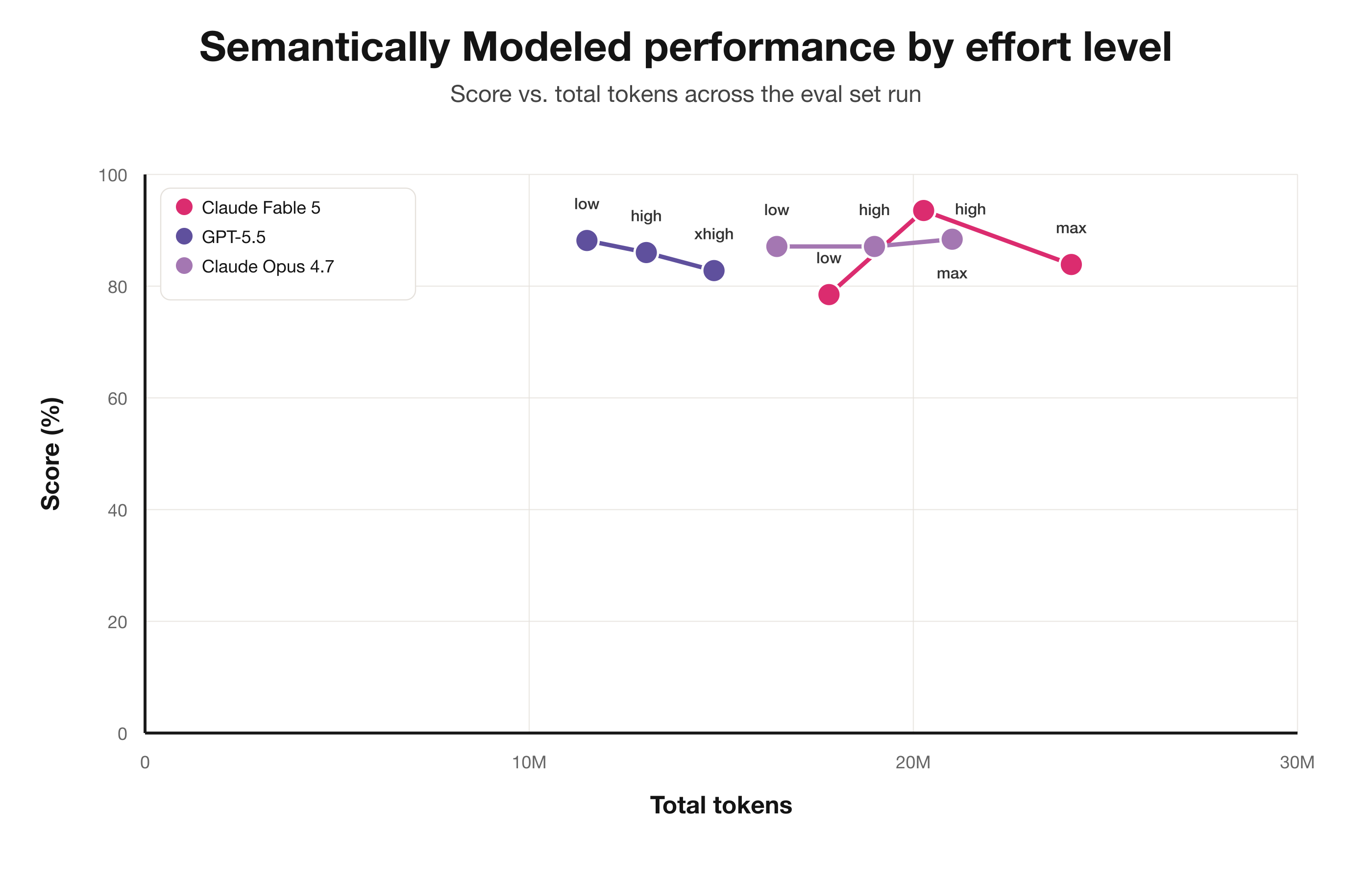
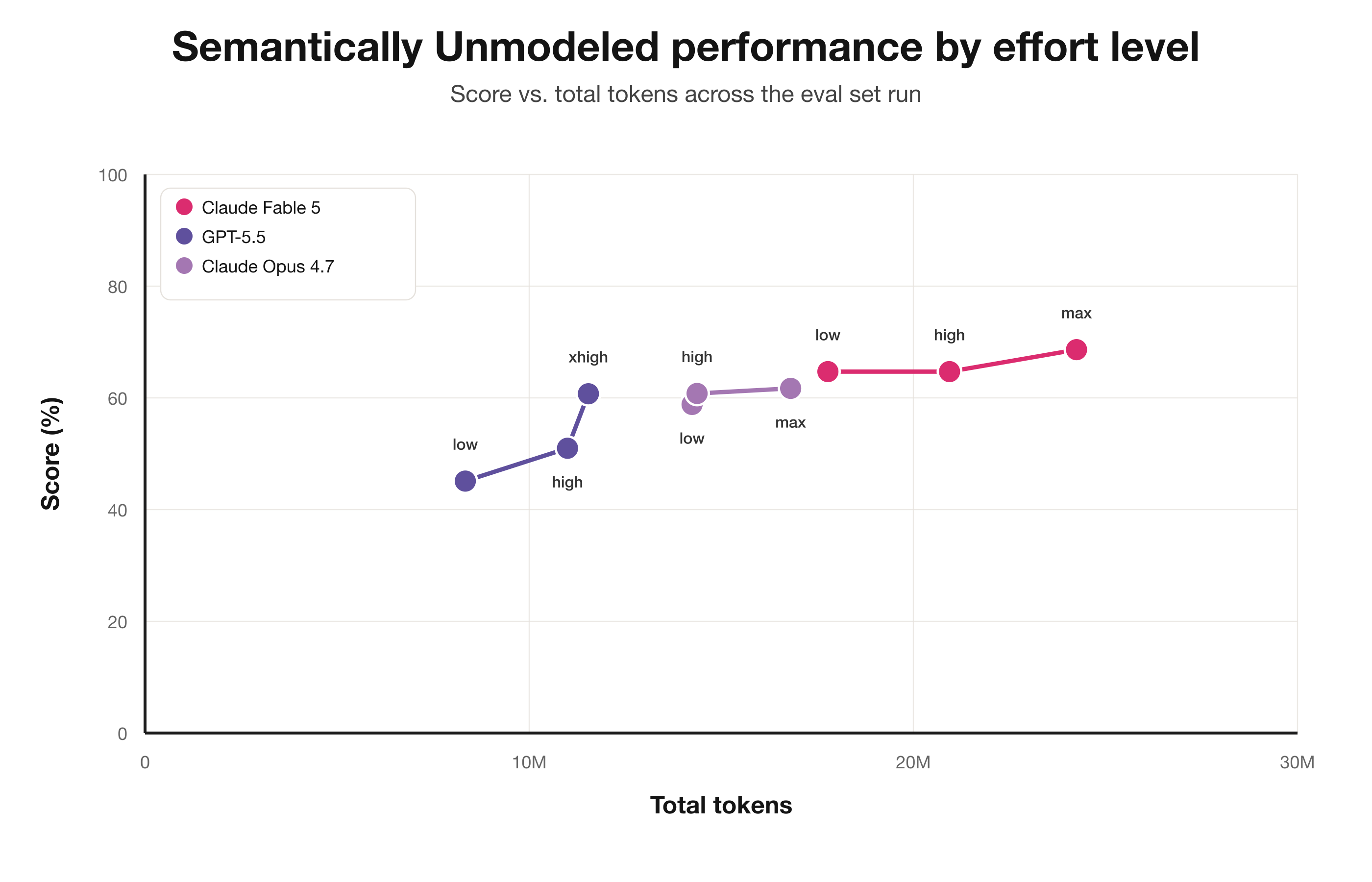
This is not present in the more challenging semantically unmodeled set and seems to be an artifact of using max effort on easier but unverifiable tasks.
Compared to Opus 4.7, Fable 5 is a significant improvement— even with no changes yet to the prompting or harness. Previous model bumps like Opus 4.6, 4.7, and 4.8 have contributed single-digit (and sometimes negative or within noise tolerance) improvements to these sets.
What these evals actually measure:
Semantically modeled: Questions that are able to be answered using a clean semantic model— requires avoiding many pitfalls and quirks of the data and determining the best definition of vague requirements.
Semantically unmodeled: Questions that are not able to be answered using just the semantic model. An agent must do analysis using raw tables in a complex and intentionally confusing environment, synthesizing a lot of disparate context to do things correctly.
Analytical hard: Evaluates an agent’s ability to answer questions correctly even when retrieving all relevant context does not resolve certain complications. Agents must make correct assumptions and actually discover things about the dataset in order to perform well.
Why does Fable perform so well on these evals? From what we’ve seen, there’s three main contributors:
- It’s just better at the intuitive little stuff that makes all the difference in analytics. It is a “better analyst”, with all the je ne sais quoi that comes with that— it knows when to double-check without being overly paranoid, has a good nose for which way to slice and dice a problem, and is a much better analytical communicator.
- It is much better at leveraging what we think of as the “golden workflow”, where an analysis begins in the semantic layer, and if it needs to deviate out into raw data or downstream transformation, the final results are carefully framed and compared to the original semantically modeled data*.*
This is how everyone should work, but earlier models often fail here, forgetting to cross-check a final number derived from SQL queries back to relevant semantic ground truth. - It’s much better than other models at understanding and defining the assumptions it’s making as it works, and often offers alternatives or further depth to users.
Here’s some examples of what that looks like in practice:
Example 1: Minimum total MRR
On this eval, Opus discovers an interesting quirk of the data and presents it as the primary answer, despite it being obviously (to a human’s eyes) the caveat/footnote that should be attached to the correct answer— SMB.
Fable correctly presents the primary finding up front and clearly, and adds some elegant “notes on scope” in which it explains how it defined its terms, points out that consumer data quirk, and notes + proactively presents an alternative definition.

Opus wasn’t flat out wrong, and it would even be tempting to mark it as passing— until you see it side-by-side with Fable’s work and realize what the more optimal analytical behavior here is.
This pattern plays out reliably across all our evals.
Example 2: Median Refund Request by channel
This next eval cannot be answered purely using our semantic layer, though there are helpful partial results available there. Here, Opus returns raw data without realizing there’s an obvious (to my eyes!) cents-for-dollars bug affecting this raw table.
Instead of understanding the issue correctly or cross-checking to related semantic models, it assumes that these must be “partial/line-item refund requests” and presents the misleading data as-is.

Fable is able to start in the semantic layer, move out to raw SQL for transformations, and then present correct findings couched in the semantically modeled data, avoiding the dollars-for-cents bug. This is the “golden workflow” that Hex enables, where any question can be answered with a verified foundation, and it warms my cold little heart to see a model leverage it correctly.
Note also the richness of the response; again, terms and assumptions are specified, and deeper details are elegantly peppered in. It’s a very nice response!
Quantitatively, Fable scores ~10-15% higher than other models across all these eval sets, which is a much larger jump than other recent models.
But qualitatively, we felt that there was actually something bigger than we were seeing in these scores. Saturation meant we had no way of understanding the performance ceiling, and other models perform well enough on this eval set that it was a step-change, but nothing crazy.
Most importantly, this eval set is designed to test single-turn Q&A. Complex, difficult, realistic single-turn Q&A, for sure, but this is still just barely scraping the agentic possibilities of these models…
Building a harder benchmark
Our core evals were painstakingly handcrafted to expose and test the exact analytical shortcomings that Fable is clearly overcoming on shorter horizon data work. It brings our team immense joy to watch this benchmark saturate!
The “analytical overhang” has been clear to us since Claude code started taking off; even at the start, you simply could not square model performance on agentic coding and reasoning with the absolute foolishness that’s still on display whenever you ask them to do complex data work. We have been waiting eagerly for something like Claude Fable 5 since I first tried Opus 4.5 in November 2025 and saw that gap start to really widen.
So when Anthropic asked for our opinions on Fable and we saw it max out our evals… we knew exactly what we wanted to test for next.
No more pub trivia Q&A. No more gotcha trick questions with finicky bugged columns.
Our new “Frontier” eval set tests more realistic problems, asking more open-ended and long-horizon questions on top of the same Shorelane dataset that powers all our evals:
User: Ugh. The data team says this board packet is technically correct, but I think it is leading us toward the wrong decision... Find the thing we would regret missing and tell me what to do.

These longer horizon tasks reveal quantitatively the difference that was qualitatively obvious when reading the simpler evals. Fable at Max effort hits 58%, a significant increase on all other runs we tried. These are the only evals where Max effort seemed to make a meaningful difference.
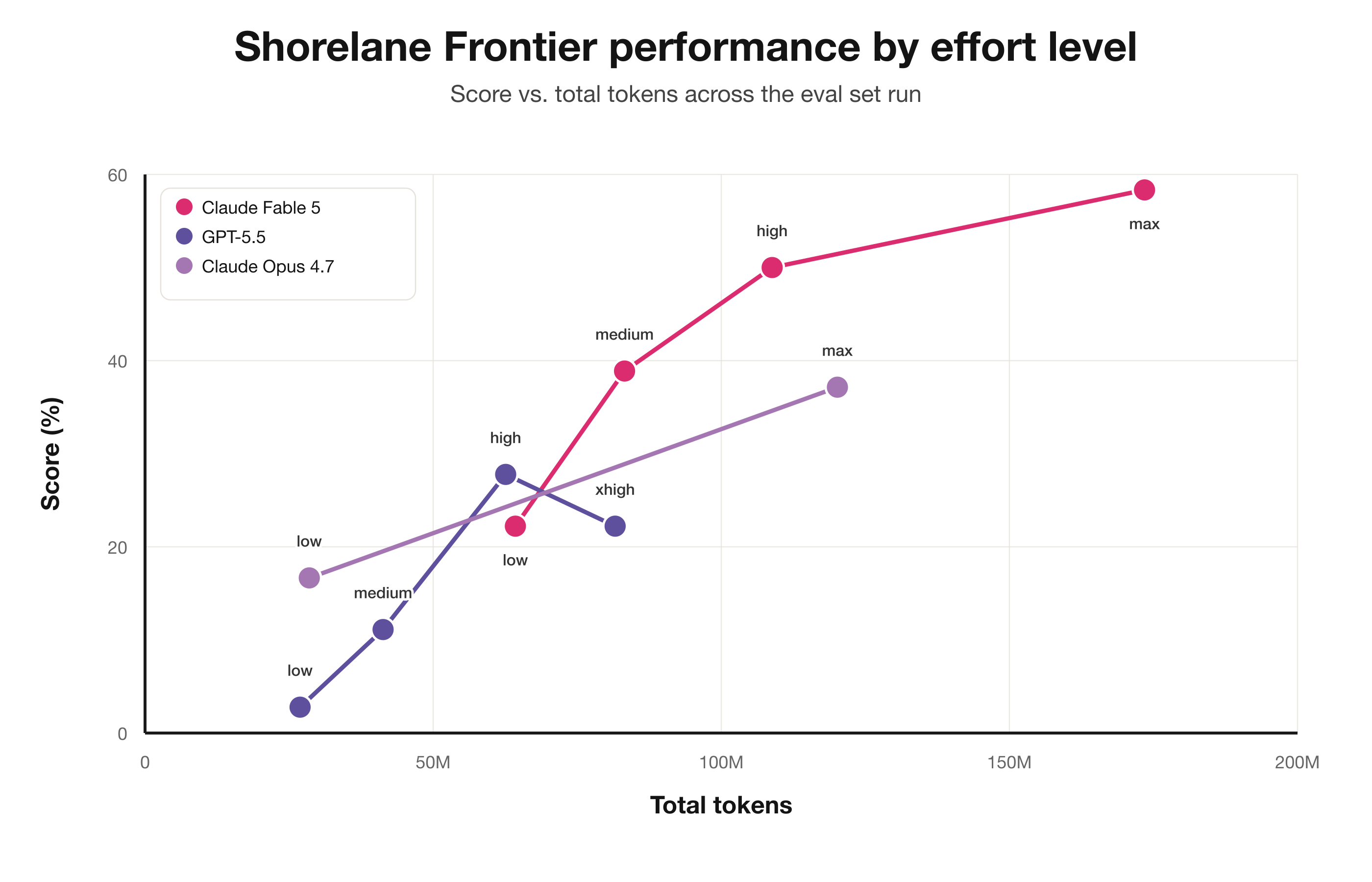
On this frontier set, success is more subjective than getting a single data point right. For that board-regret eval, a passing score requires a response that:
- Frames the latent, implicit business decision correctly
- Investigates multiple plausible explanations
- Catches that FCT_ORDERS.COGS_AMOUNT runs ~1.4x the summed ORDER_ITEMS.TOTAL_COST across the Aug–Oct 2025 peak window — leaving gross-profit truth unresolved
- Ideally treats record revenue as the symptom, and downranks at least two other non-root-cause explanations (refunds, subscription health, marketing ROAS, channel mix, discounts)
- Reaches the right decision: don't scale the peak-season playbook or set targets off the October run-rate until Finance/Data verifies whether the premium is a real surcharge or just an ETL artifact/bug.
- A litany of other potential ways to win/lose points.
All evals in this set test similarly complex and open ended tasks. They often require generation of a full report, and intentionally place the models in situations where a mistake early on in the trajectory can permanently “poison” downstream decisions unless it can redirect. Models are penalized for putting on blinders and missing the forest for the trees, but also for wasting time on obviously fruitless directions.
These responses and trajectories are too large to include here today, but Fable is consistently more thorough, curious, careful, and precise as an analyst. We’re excited to watch that 50% high water mark creep upwards over the next months and publish more information about this benchmark.
Available in Hex soon
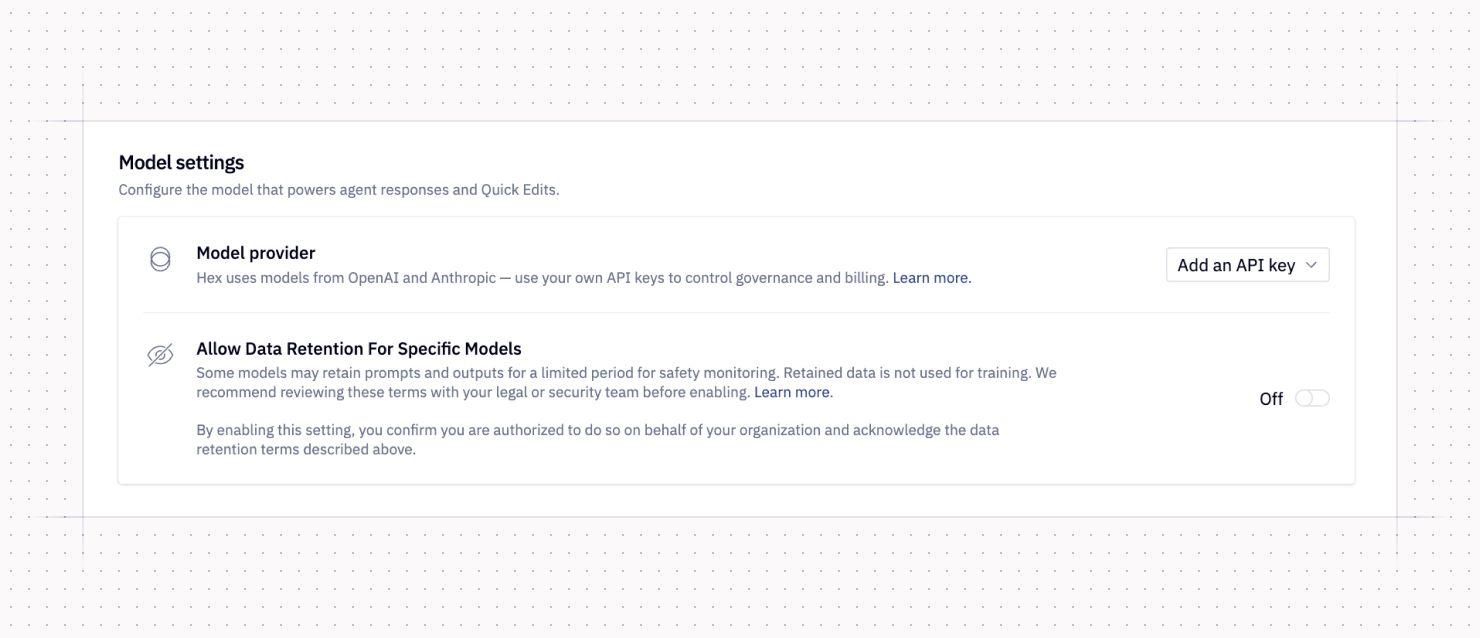
We will be rolling out Fable in Hex via the agent model picker this week. It will not be on by default — enabling it requires a prestep for admins and we encourage you to discuss with your security and legal teams before doing so.
Admins must enable model data retention for your workspace. Fable is a Mythos-class Anthropic model, and Anthropic retains conversation data for a limited time period for safety monitoring purposes. Admins must enable model data retention in Hex before users will be able to leverage Fable. This is an Anthropic policy requirement and is not configurable. This will be available in Settings → AI & Agents.
A note on cost: On some tasks, Fable can use significantly more tokens than our standard model set and is priced accordingly. For routine analytical work, it's likely more than you need. For high-stakes, complex, or long-horizon analysis, we think the quality difference justifies it. We'd encourage teams to evaluate that tradeoff for their own workloads before encouraging use more broadly.
If this is is interesting, click below to get started, or to check out opportunities to join our team.


