Blog
Why analytics agents break differently
What we learned about context management while building production analytics AI



The Notebook Agent inside of Hex helps users explore their data and build analyses using the state-of-the-art frontier models inside their workspace.
The Notebook Agent was analyzing a marketing funnel when it hit a wall. By the third step of a five-step analysis, the agent quickly hit the 200k token window. Compression triggered — the agent's "memory" of previous conversation was summarized to save space. When it tried to continue, it failed: "I can't complete the analysis — I need the actual conversion numbers from step 2."
The problem wasn't that we forgot to add token limits. The problem was fundamental: you can summarize what code does ("this function calculates revenue"), but you cannot summarize the actual data values without losing the ability to reason about them. Code has abstractions — functions, classes, interfaces — that preserve meaning when compressed. Data doesn't. An analyst needs to see the actual numbers to spot patterns, identify outliers, or compare metrics. An AI agent needs the same.
These are the kinds of challenges we faced while building early versions of the Notebook Agent in Hex. After months of work, we now have something that works great for thousands of data analysts for deep workflows — but this wasn't always the case! It took a bit for us to create a new mental model for how we think about context engineering specifically for data flows.
Our key takeaway was: analytics agents break differently than coding agents. Code has predetermined abstractions. Data requires discovered structure. When you compress code, you're using an interface someone designed. When you compress data, you're deciding what matters — but for exploratory analysis, you can't know what matters until you look. And enterprise data environments, with 200-column dimension tables and comprehensive dBT documentation, only make the challenge worse.
When you point an AI agent at a data warehouse and ask it to "find insights," context breaks in new ways that differ from coding agents. Here are our notes on context engineering principles after building Hex's Notebook agent.
The two ways analytics agents are different
1. Analysis requires judgement and you can't unit test that
When building a new feature, one of the best ways to start is with clearly outlined tests that the agent can use to determine success as it works through building this feature. Analysis doesn’t have the same luxury.
Analytics agents face open-ended exploration:
- "Are there any interesting patterns in Q4 sales?"
- "Why did conversion drop last week?"
- "Help me understand the customer segments"
These aren't tasks with binary outcomes, or tasks that necessarily have a clear correct answer. They're invitations to explore the data space where the agent needs to form hypotheses, test multiple approaches, and recognize "interesting" vs "expected" patterns.
These sorts of questions and analysis are much closer to a writing task - there is a lot of taste and judgement that goes into an analysis and there's no way to write a unit test for it.
2. Data objects can be unpredictably massive
Coding agents work with functions, classes, and modules. These are conceptual units that compress naturally:

An agent can understand "this function calculates revenue" without seeing the implementation. The summary preserves the essential information.
Now consider a data table:

How do you summarize this? "A table with customer orders" loses everything analytically valuable. The agent needs to see actual values to identify patterns, spot anomalies, compare metrics.
Tables inside of a data warehouse often have large JSON blobs that are the bane of data analysts — no surprise that they are equally painful for agents. You can't compress 50 rows of such data to "quarterly sales data" without losing the ability to reason about it.
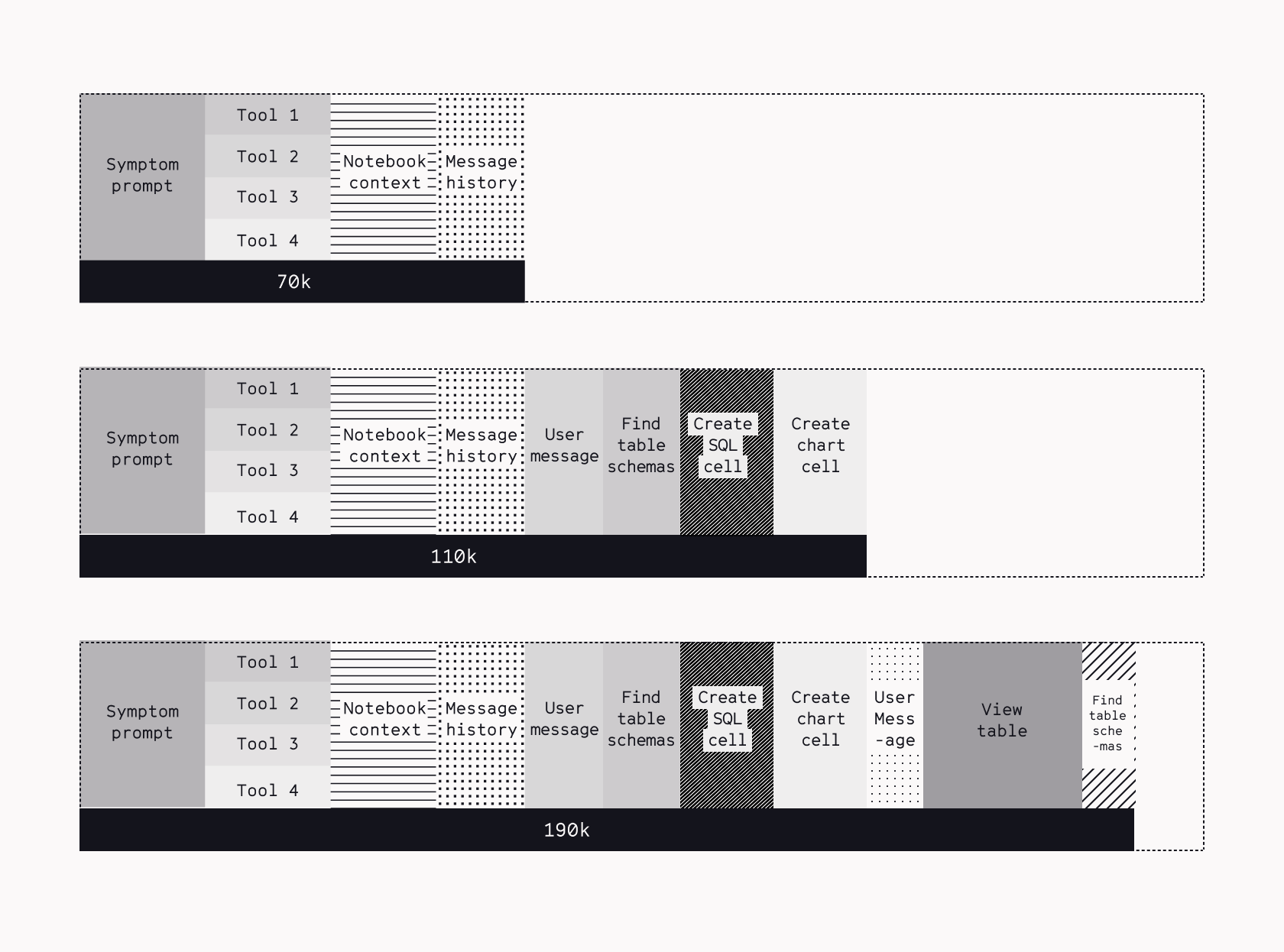
This creates an immediate problem: viewing a single cell's output in our notebooks — something analysts do constantly — could consume 30,000+ tokens.
Lessons we learned
When we built the alpha version of the agent, it seemed like a no-brainer to utilize the large context window models to solve all the problems above. 1-2M context window models were readily available, and in some cases, even boasted of rave benchmarks. There are truly no free lunches in the AI world and we quickly identified three core tradeoffs to using large context windows:
- Quality degrades rapidly when we stuff the model with millions of tokens as seen by
- independent research.
- Speed of response slows down making the agent feel sluggish.
- Cost, depending on your model provider and day of week, can be 2-3x.
Structure context as a map
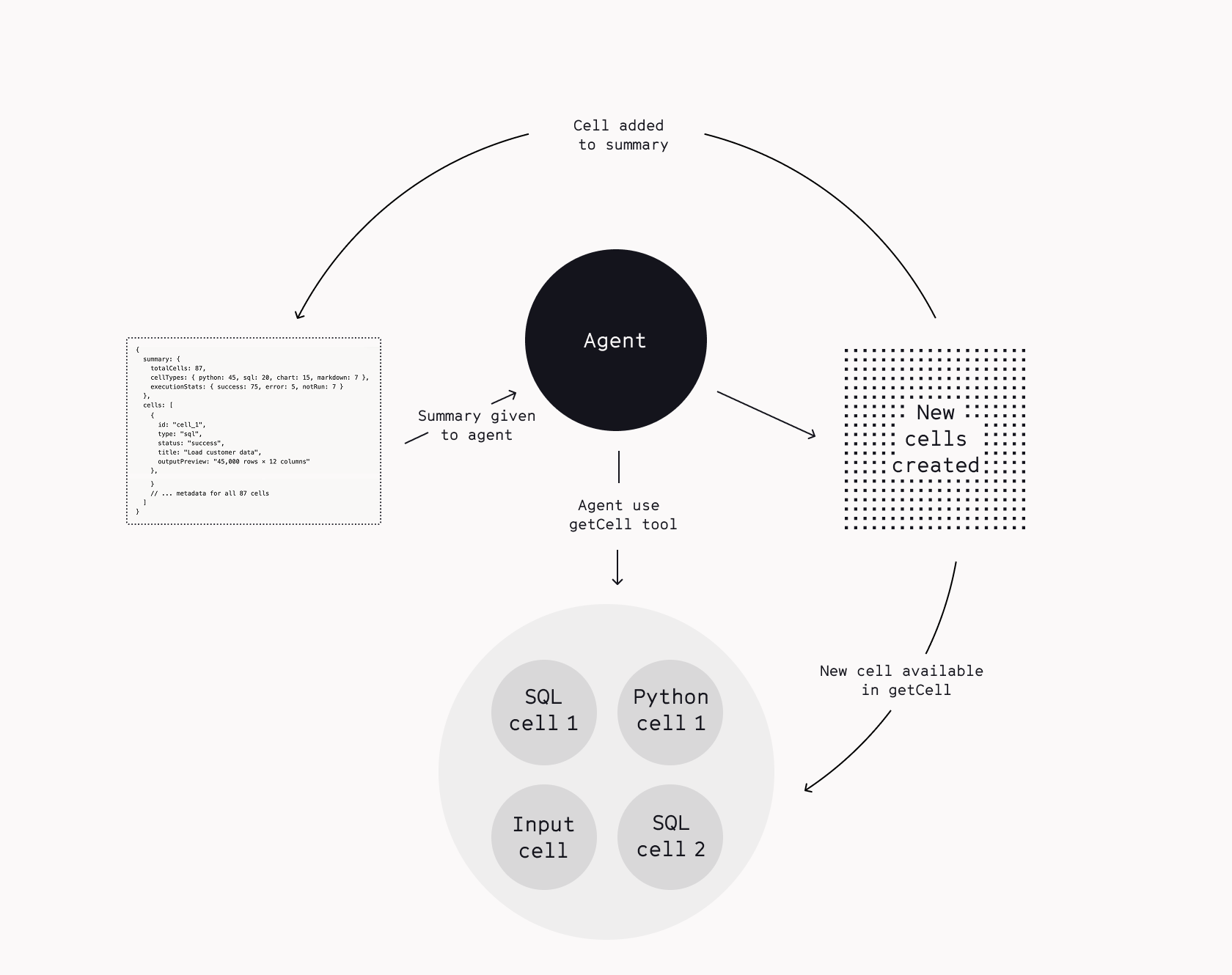
Early on, we gave the agent tools like "GetCellCode" and figured it would fetch what it needed. This worked for simple data exploration, but would struggle with more real world complex analysis — fetching Cell 17, then Cell 3, then back to Cell 8 — burning tokens and context without understanding the computational flow.
Notebooks aren't file trees. They're computational graphs. Cell 17 depends on Cell 12, which depends on Cell 8 and Cell 3. Without seeing that structure, the agent couldn't navigate intelligently.
So we built a cell inventory that shows the whole notebook at once: cell types, execution status, error states, output previews. It's like a table of contents, but for computation:

With the map in hand, the agent stopped wandering. It could trace dependencies, spot patterns, understand the analytical flow.
Set (token) boundaries
An effective analytics agent needs to read and reason about the outputs of its data operations. The resulting data from queries can be massive and accidentally blow up the context window.
The problem isn’t so much so that data objects are large. It's that data size is wildly unpredictable. The same "view table" operation could be 1,000 tokens or 100,000 tokens depending on what's in the cells. Unlike files in a codebase, where you roughly know a Python module is going to be a few hundred lines, data has no natural ceiling.
To tackle these unpredictably large token objects, we made the structure as predictable as possible. Every tool got a hard token budget (between 5-10k tokens) with explicit messaging on what was truncated and guidance on further probing. Further the notebook context itself became fixed-size: 15,000 tokens whether it's 50 cells or 500 cells.
These limits aren’t as much about escape hatches but enabling better agent ergonomics for our environment. When costs are known, reasoning is more efficient. The agent doesn't have to guess whether fetching a table will blow up its context budget. It knows the constraints upfront and can plan and chart its course.
Tell the agent what it can't see
Here's something that surprised us: agents work better when you tell them about limitations. When we truncate a table from 50 rows to 30, we don't just cut and hope the agent doesn't notice. We tell it explicitly:

The agent adapts. If the visible data is enough, it continues. If it needs those missing columns, it knows exactly how to ask. Silent truncation breaks reasoning. Explicit truncation enables it.
The context optimizations created a foundation for deeper intelligence. With the cell inventory providing notebook structure, we can now build graph-aware features: understanding data lineage, tracing dependencies, explaining computational flow.
This is different from just fetching cells efficiently. It's about teaching the agent to understand notebooks as computational stories — how data flows from raw inputs through transformations to final insights. This mirrors how effective data analysts actually work.
We'll explore this graph-aware navigation system in Part 2.
Context engineering for analytics isn't about fitting more data into a window. It's about representing complex, high-dimensional environments in ways AI agents can reason about efficiently. The constraints force better design.
If you're working on similar problems at the intersection of AI and data, we'd love to talk. See our open roles here.