Blog
How we built (and rebuilt) topic discovery into the Hex Context Agent
What are people actually asking your agent?

Letting everyone ask questions of data in natural language is an obvious, “holy grail” use case for AI – and a use case people love to do in Hex.
This can be, however, a rats nest of inconsistent answers, inaccurate conclusions, and inconvenient workflows. It’s great that everyone can ask questions — but what are they asking about? And are they getting good answers? Should they trust them?
Obviously data teams can’t manually review each thread, nor rely on users flagging potential issues. Instead, they need powerful, proactive tools to compound context — which was our motivation behind the Review Agent, which we first introduced in January. When a user concludes a conversation in Hex, the Review Agent then goes through it; extracting key facts, surfacing potential issues, and giving suggestions for how to improve context.
We’ve built many things into the Review Agent now, but the one we started with was important: Topics. It allows data teams to see what folks are asking about, and identify clusters of issues.
With Topics, our aim was to build a system that’d run for every active Hex organization (over 2,300 and growing fast!) multiple times per week, on all active threads since last run, and support merging and deduplicating topics—leaving us nicely-clustered results that data teams could use in their work.
Push 1: Real ML
To get Topics kicked off (as a card-carrying Machine Learning Person) I rolled up my sleeves to start casting some complex spells.
Anyone who has worked in natural language processing (NLP) knows that topic detection is a standard ML task with a plethora of reasonably successful approaches. My first instinct was to take one such approach I knew would work: generate embedding representations of each thread, and then cluster them with an off-the-shelf algorithm like HDBSCAN. In fact, I’d used this same strategy to great effect to understand our agent’s thinking patterns just a couple months earlier.
That kind of thing works great as an offline, one-off analysis. However, once I started to math it out, this solution wasn’t really a fit for Hex’s existing infrastructure, and wasn’t going to work for the product experience we had in mind.
In isolation, HDBSCAN wasn't actually the bottleneck (even at 10k examples, the clustering step itself ran in just a few seconds.) The expensive part was everything around it. UMAP, the dimensionality reduction step that takes 1536-dimensional embedding vectors down to something clusterable, took tens of seconds per run on CPU at 7.5–10k examples, and that cost only grows with dataset size. Multiplied across 2,300+ orgs, running multiple times per week, on a steadily growing pile of threads, this just wasn't going to fit on CPU.
On GPU, the dimension reduction would have been trivially fast. But the only way to get there was to stand up a brand-new GPU service for a single workload, plus the supporting infrastructure for high-dimensional vector processing — at minimum an entire sprint of work, before we even shipped a single topic to a customer. And it also introduced a real tuning surface, with knobs to fiddle with on both the UMAP and HDBSCAN side.
Even after all that effort, the classical pipeline wouldn't have eliminated the hardest part of the problem: we'd still need an LLM to name the clusters, merge near-duplicates, and keep topics stable as new threads arrived. UMAP + HDBSCAN is fundamentally a batch recomputation workflow — fine for a one-off notebook analysis, awkward as recurring product infrastructure — but the product needed stable topics plus online classification of new threads as they came in. The classical approach didn't remove the LLM workflow… it just added a second system in front of it.
So I started thinking, could I do something dead simple that wouldn’t require setting up our own GPU infrastructure?
Push 2: LLMs are all you need
I had actually already tried a pure-LLM approach. We already generate a brief, few-sentence summary for every thread (which fit the bill for a concise, low-token representation of the conversation,) so I wanted to see what would happen if I just tossed 100 of those summaries into an LLM and asked it to cluster them into semantically interesting topics.
Admittedly, my bias was that this was unlikely to work. I didn’t think that generative LLMs had the ability to pick up on enough nuance to make interesting topics. And, sure enough, my first attempt yielded a bunch of boring and uninformative topics like “Data Source Discovery” and “Salesforce Field Names.” Pretty useless for understanding the actual intention of these conversations.
Faced with the reality of having to beg our Infra team for GPU allocation, I revisited the pure-LLM approach with a more open mind. My first attempt, admittedly, had been a bit lazy: I tried to do both topic discovery AND assigning all the threads into their topics in a single prompt. This was cluttering the context window and giving the LLM too many things to think about in one call.
The One Weird Trick that made it all work was to split this into two separate stages: a discovery step and a batch-classification step. In the first step, the LLM’s only job was to propose topics, and to reference at least a handful of threads as the “examples” for each topic. Then, in the second stage, I fed that topic catalog into a fresh context window, and said “now here are 30 threads, please classify them into the provided topics.” It would then repeat until all unclassified threads are classified.
The funny thing is I didn’t even need to change the prompt all that much; I just needed to stop overloading the LLM with too much responsibility at once. Just breaking the pipeline into stages was enough to improve topic quality significantly.
This produced topics that were still pleasantly brief, but now they actually indicated what the threads were trying to do: “AI Feature Adoption,” “Customer Seat Usage,” “Sales Pipeline Analysis.” When our data team saw these, they immediately knew what they meant. Now that they had useful signal on what people were asking, they could prioritize where to make targeted context improvements for the agent: writing topic-specific guides (link), referencing reusable logic from projects, creating semantic models for common analyses, and improving table and column descriptions.
How the system works now
The final design landed in almost exactly this shape. It works like this:
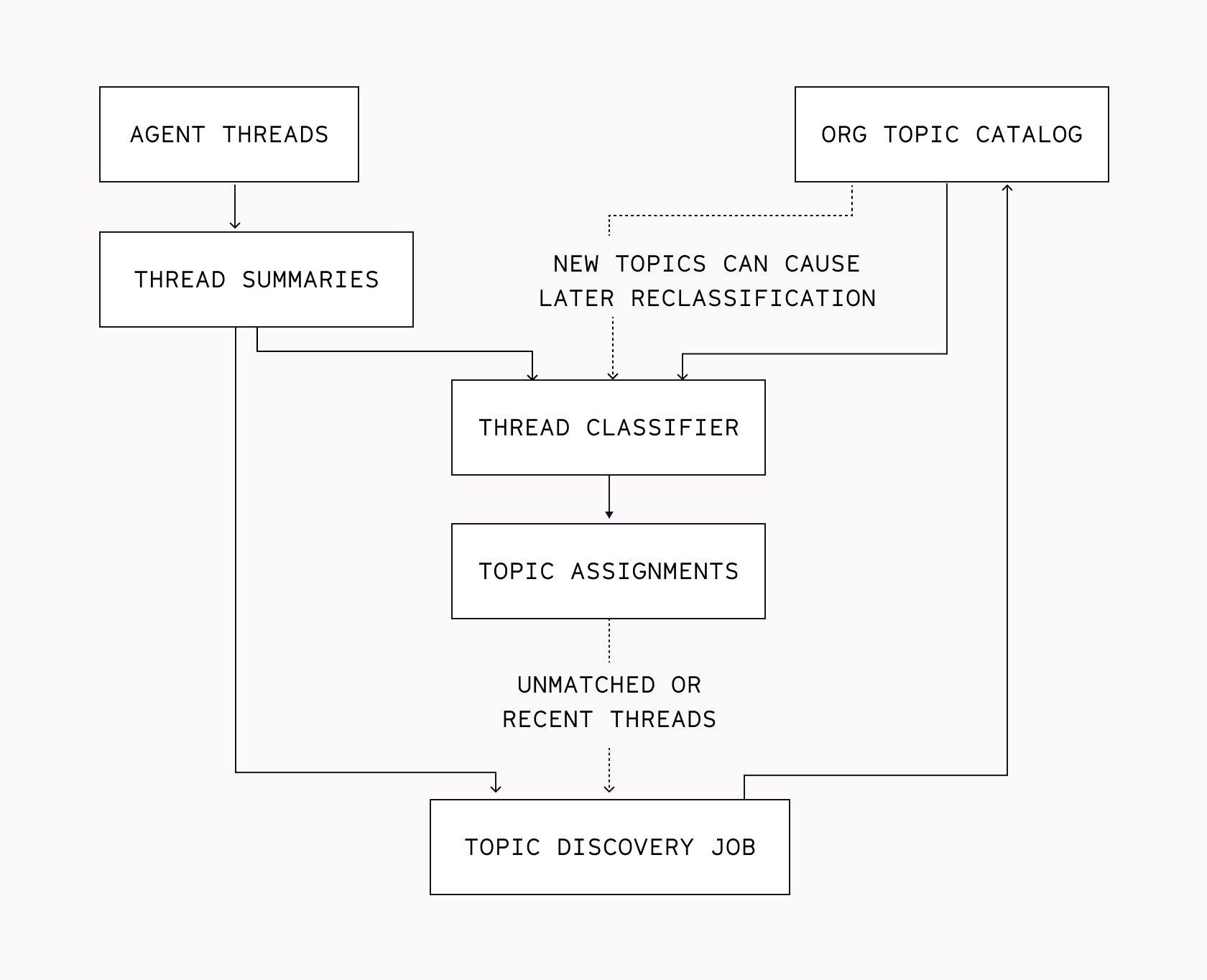
Topic Discovery
For every org, we check whether they’ve asked at least 40 questions in Threads.
If they have, we feed up to 100 thread summaries to an LLM, and ask it to find interesting patterns specific to that org to cluster the threads with. This is the initial discovery phase. We then batch-classify all unclassified threads using that topic catalog.
Every 2-3 days, we run “incremental” topic discovery to create additional topics for any new or emerging trends in the org’s Threads.
Topic Classification
As new threads come in, we attempt to classify them using the org’s existing topic catalog. But there’s a hidden gotcha here: if most threads are a reasonably good fit for existing topics, we would hardly ever discover new topics, because those threads would just get lumped into the existing ones.
Instead, we add a little carveout: the thread is still added to the “discovery pool” at the next incremental discovery date, and is eligible to be reclassified if we discover a better-fitting topic for it. This gives us a richer body of threads for incremental discovery, because it includes both “threads that didn’t fit an existing topic” and “threads that kind of, but not completely, fit an existing topic.”
Current Limitations & What’s Next
One notable limitation of this method is that the topic list is flat. Rather than the various finance-related topics falling under a Finance topic, then splitting out into finer-grained topics, we end up with many atomic topics about Finance, but nothing explicitly relating them to each other. We’ve thought about implementing a hierarchical clustering technique—but in practice, in-product data and customer feedback has indicated they’re happy with the existing topic structure (but let us know if you disagree! 🙂).
One can imagine doing a lot more with this data than just using topics to drill down on threads in Context Studio, though. For example: what if we tried to classify a thread’s topic up front, just from the first user question? Then, orgs could pre-specify reference context (guides, tables, models) for particular topics, and we could inject them for the agent to use at runtime. User asks question → we proactively inject that context → the agent becomes much likelier to get to an accurate and trusted conclusion.
Another idea: Topic-specific eval suites with health scores. User-facing evals are an active area of development at Hex. We can ask: what’s the pass rate for evals in this topic? How, qualitatively, do this topic’s evals tend to fail? Wrong choice of table, wrong choice of metric? Those could then become an issue for our Review Agent to investigate, and it can then propose concrete fixes for org context or warehouse metadata via our Suggestions system.
We could even try to answer the question: “what are people doing with data agents, across all orgs?” We could use privacy-preserving analysis techniques, such as in (Anthropic’s blog post). We could turn this treasure trove of thread topics into a “State of Data Work with Agents,” and better understand what types of problems people are seeking to solve with data agents. Maybe this could even lead to Hex developing its own (internal or external) benchmark for high-quality agentic data analysis. So many possibilities!
The lesson: embrace the simpler path
We live in a weird world. Only a few years ago, this topic discovery pipeline would have required dedicated GPU infrastructure and potentially multiple engineers. Instead, a single IC whipped it up 100% agentically (yup—agents wrote the code too), simply by duct taping some APIs together and pointing it at the right data.
Personally, I’m thrilled by how much smaller the gap is now between deciding to build the thing and actually building the thing. There’s never been a better time to be an engineer who delights in making your end users’ lives easier. If shipping a ton of good features quickly sounds fun to you too, come do it here at Hex!
If this is is interesting, click below to get started, or to check out opportunities to join our team.


