
Izzy Miller
See how to use data science to enhance inventory decisions with this comprehensive project focused on analyzing, predicting, and optimizing inventory levels. Using histor...
How to build: Inventory Management Analysis
Effective inventory management is essential for preserving smooth operations and optimizing profitability in the fast-paced commercial sector. Keeping track of everything you have in stock, from raw materials to final goods, is the technique of inventory management. It entails tracking inventory levels, keeping an eye on sales patterns, and making sure that goods are available when needed. For any type of organization, regardless of size, effective inventory management is essential to cutting expenses, preventing stockouts, and maximizing cash flow. Avoiding stockouts can prevent operational disruptions and lost sales. It also helps companies to satisfy consumer demand, steer clear of overstocking or understocking, and eventually spur company expansion.
In several fields, including inventory management, Python has become a potent tool for predictive and statistical modeling. It is a good tool for analyzing big datasets, finding patterns, and making precise predictions because of its adaptability, simplicity of usage, and a strong set of libraries. Businesses may better understand inventory trends, predict demand, and make well-informed decisions to streamline their inventory management procedures by using Python for predictive and statistical modeling.
In this article, you will learn about the objectives of inventory management, key performance indicators (KPIs) for effective inventory management, various inventory management techniques, and the role of predictive and statistical modeling with Python and Hex in optimizing inventory management processes. This article will give you the information and resources you need to simplify inventory management and promote business success, whether you're a business owner, inventory manager, or aspiring data analyst.
Understanding Inventory Management
Inventory management is the process of overseeing and controlling the flow of goods from suppliers to warehouses and ultimately to customers. It involves managing the balance between supply and demand to ensure that sufficient inventory is available to meet customer needs while minimizing excess stock and carrying costs.
Objectives of inventory management
The objectives of inventory management are multiple and include:
- Sustain Ideal Stock Levels: This guarantees that you have adequate inventory to satisfy consumer demand without incurring needless storage expenses.
- Minimize Stockouts: Avoid scenarios in which you run out of necessities, which can result in lost revenue and disgruntled clients.
- Reduce Waste: Steer clear of overstocking low-demand or perishable goods that can go bad or become out-of-date.
- Boost Cash Flow: By keeping inventory levels optimal, you tie up less cash in stock, which strengthens the finances of your company.
- Managing Seasonal Demand: To maximize inventory levels, and anticipate and control demand fluctuations brought on by seasonal variations or market trends.
- Enhancing Customer Service: Making sure that products are available to quickly and effectively complete customer orders, therefore raising customer satisfaction.
Inventory Costs
The expenses that come with keeping, controlling, and storing inventory in a business are included in inventory costs. These consist of:
- Carrying Costs: Storage, electricity, insurance, and security costs are all considered carrying costs.
- Ordering Costs: Order processing, shipping, and supplier management fees are included in the ordering costs.
- Stockout Costs: Losses from low inventory that result in lost sales and disgruntled customers are known as stockout costs.
- Obsolete Inventory Costs: Costs associated with out-of-date or expired goods, including write-offs and disposal fees.
- Opportunity Costs: Opportunity costs are the possible gains derived from putting capital in profitable prospects rather than holding it up in inventories.
Key performance indicators (KPIs) for inventory management
Metrics known as key performance indicators (KPIs) are crucial for assessing how well inventory management procedures are working. They offer insightful information on a range of inventory performance topics, assisting companies in pinpointing areas for development and formulating data-driven choices. Below are some of the important KPIs to understand and monitor.
- Inventory Turnover Ratio: This measures how frequently you replace and sell your inventory stock during a given time frame, usually a year. While a lower ratio could imply overstocking, a higher ratio shows effective inventory management.
- Stockout Rate: This KPI shows the proportion of times you run out of a specific item. Reduced sales and unsatisfied customers may result from a high stockout rate.
- Carrying Cost of Inventory: This is the total of all the expenditures related to keeping and preserving your inventory, such as handling, insurance, and storage space.
- Order Cycle Time: This estimates how long it takes to place and receive an order. A reduced order cycle time guarantees that stockouts can be prevented and items can be quickly restocked.
- Fill Rate: This KPI shows the portion of client orders that are completed with no missing parts. Order cancelation risk is decreased and client satisfaction is guaranteed with a high fill rate.
Inventory Management Techniques
Businesses utilize inventory management techniques as a means of optimizing inventory levels, streamlining operations, and enhancing overall efficiency. By using these strategies, companies may efficiently manage their inventory to satisfy consumer demand while cutting expenses and increasing profits.
- Just-in-Time (JIT): By obtaining materials only when they are required for production, this strategy aims to reduce inventory. As a result, there is less chance of obsolescence and storage costs. JIT is frequently employed in sectors with robust suppliers and high production turnover.
- Economic Order Quantity (EOQ): The best order quantity to reduce overall inventory costs can be found using the EOQ formula. The most economical quantity to acquire at a moment is determined by taking into account variables including demand, storage expenses, and ordering costs.
- ABC analysis: This method divides inventory goods into groups according to demand and value. The most precious and in-demand "A" items necessitate constant observation. Since they are less valuable or in demand, "B" and "C" items don't need to be monitored as frequently. Prioritizing inventory control activities is aided by ABC analysis.
- Vendor-managed inventory (VMI): Your supplier is in charge of controlling your inventory levels when you use a VMI system. When new supplies are required, the supplier will automatically ship them to you based on an inventory-level check. Businesses with sophisticated inventory management needs or varying demands may find this useful.
- Kanban system: Using the Kanban system, inventory flow may be visually managed. It makes use of Kanban cards, which show the items and their respective stock levels. The system indicates graphically when supplies need to be reordered, which helps to ensure a smooth flow of goods.
Predictive Modeling with Python for Inventory Management
Using predictive modeling makes inventory management much more efficient. Using statistical and mathematical approaches, predictive modeling with Python allows you to project future demand for your goods. Businesses can use these strategies to foresee trends, spot patterns, and make well-informed decisions by leveraging historical data.
Concepts of Predictive Modeling for Inventory Management
A range of statistical and computational techniques are used in predictive modeling to examine past data and spot trends. Subsequently, projections about the future are derived from these patterns. The following are some essential modeling strategies for inventory control:
Regression
Regression is a statistical technique that focuses on establishing a relationship between a dependent variable (what you want to predict, e.g., future demand) and one or more independent variables (factors that influence the dependent variable, e.g., past sales data, economic trends), and it generates a predictive equation to estimate future outcomes. It is commonly used for predicting numerical outcomes, such as sales forecasts, stock prices, or customer satisfaction scores.
Time series forecasting techniques
Time series forecasting is a predictive modeling technique used to analyze sequential data points collected at regular intervals (e.g., daily, weekly sales data). It involves identifying patterns, trends, and seasonality in historical data to make predictions about future values. Time series forecasting is commonly used in financial forecasting, demand planning, and resource allocation.
- ARIMA (AutoRegressive Integrated Moving Average): ARIMA is a popular time series forecasting method used to model and forecast time-dependent data. It analyzes past observations and uses autoregressive and moving average components to predict future values. ARIMA models are suitable for forecasting sequential data, such as stock prices, sales data, or weather patterns.
- SARIMA (Seasonal AutoRegressive Integrated Moving Average): SARIMA extends the ARIMA model to handle seasonal variations in time series data. It incorporates seasonal autoregressive and moving average components to capture periodic patterns and fluctuations. SARIMA models are handy for forecasting seasonal trends in data, such as holiday sales or monthly production volumes.
Machine Learning Models
Without the use of explicit formulas, these algorithms are capable of learning intricate correlations from data. They are useful in scenarios where the relationship between demand and influencing factors would be difficult for a linear model (like regression) to describe, as they are strong tools for managing non-linear connections and complex data patterns.
- Random Forest: Using several decision trees and combining their forecasts, Random Forest is an ensemble learning technique that produces more accurate forecasts. It is appropriate for a variety of predictive modeling applications due to its versatility and ability to handle both regression and classification problems. Random Forest models accept input data consisting of features (independent variables) and their corresponding target variable values and generate predictions based on the collective decisions of multiple trees.
- Gradient Boosting: Gradient Boosting creates a sequence of weak learners (usually decision trees) by focusing on the mistakes made by its predecessors. By reducing prediction errors and learning from past errors, iteratively improving model performance is achieved. Because of their strength and accuracy, gradient-boosting models are perfect for intricate predictive modeling applications like financial risk or customer attrition prediction.
These are only a few ML algorithms used for inventory forecasting, there are obviously a lot of other algorithms that can be used for the same.
Selection of Appropriate Python Libraries
Choosing the right Python libraries is essential to successfully applying predictive modeling methods. These libraries give users access to crucial tools and features for machine learning, data manipulation, and visualization, facilitating effective data analysis and model building.
- Numpy: NumPy is an essential Python package for numerical computation that supports mathematical functions and multi-dimensional arrays. It is perfect for preprocessing jobs in predictive modeling and data manipulation since it provides effective array operations and mathematical functions.
- Pandas: Pandas is a robust Python data manipulation and analysis toolkit that provides data structures such as DataFrames and Series. Because it can load, clean, transform, and analyze structured data, it is an essential tool for predictive modeling jobs including data pretreatment and exploratory data analysis (EDA).
- Matplotlib: A complete Python visualization toolkit for static, interactive, and animated graphics is called Matplotlib. With its extensive range of customization choices and plotting functions, users can generate visually appealing and useful charts for data visualization and model evaluation.
- Scikit-learn (sklearn): Scikit-learn is a well-known Python machine-learning framework that offers an easy-to-use toolkit for creating predictive models. It provides many machine learning methods, including dimensionality reduction, regression, classification, and clustering, in addition to tools for choosing and evaluating models.
- Seaborn: Seaborn is a Matplotlib-based statistical data visualization library that offers extra features for making eye-catching and educational statistical visuals. It is appropriate for visualizing correlations and patterns in data for predictive modeling jobs because it provides high-level interfaces for generating complicated visualizations like heatmaps, pair plots, and violin plots.
Implementation of Inventory Management with Python and Hex
Now that you know about inventory management, it is time to see the practical implementation of it using Python and Hex. Hex is a modern data platform for data science and analytics, that gives you a notebook-based workspace for developing models of any kind— including collaborative filtering models. Hex is a polyglot platform that allows you to write code in different languages within the same development environment. It can connect to various data sources including different databases, data warehouses, and cloud storage. It also provides easy visualization with the help of its no-code cells. Hex makes it easy to build a recommendation engine using collaborative filtering with Python, and then deploy it as an interactive web app. Hex's seamless integration of SQL, Python, and intuitive visualization tools make it easy to explore inventory data, build predictive stock-level models, and communicate findings in an easy-to-understand, interactive report. This model ensures you maintain the optimum level of stock during peak periods, thus minimizing costs and preventing out-of-stock scenarios.
For this section, let's consider a scenario, Imagine you're the proud owner of a thriving shoe store, and your goal is to ensure customers can always find the shoes they want when they visit. It can be quite frustrating for a customer to discover a shoe they love, only to find that their size is unavailable. Similarly, offering a model that fits but doesn't resonate with them can be equally disappointing. While this may not be a significant issue on the first visit, repeated occurrences could result in losing a loyal customer.
It's impossible to control every customer's size, style, or preferences, and there's no guarantee that the perfect shoe will always be in stock. However, by implementing an effective inventory management system, we can increase the chances that their favorite shoes will be there when they visit.
Let's dive in.
Install and Load Dependencies
To begin with, you need to install a set of Python dependencies for loading and preprocessing data, creating plots, and then performing multiple operations for inventory management. Although Hex comes up with a lot of Python dependencies already installed, if you need to, you can install these dependencies with the help of PIP as follows:
$ pip install pandas
$ pip install numpy
$ pip install matplotlib
$ pip install seaborn
$ pip install scipyOnce these dependencies are installed, you can load them into the Hex environment with the help of the following lines of code:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
import calendar
import warnings
warnings.filterwarnings("ignore")The warnings module will be used to ignore warnings regarding library versions or other unnecessary details from packages.
Loading Data
Once the dependencies are loaded, you need to load the required dataset. The dataset that we are going to use is a shoe sales dataset that contains information about shoe sales made from 2014 - 2016. This one is stored in the Snowflake data warehouse and can be loaded in Hex with the help of SQL as follows:
select * from demo_data.demos.sales_inventory_data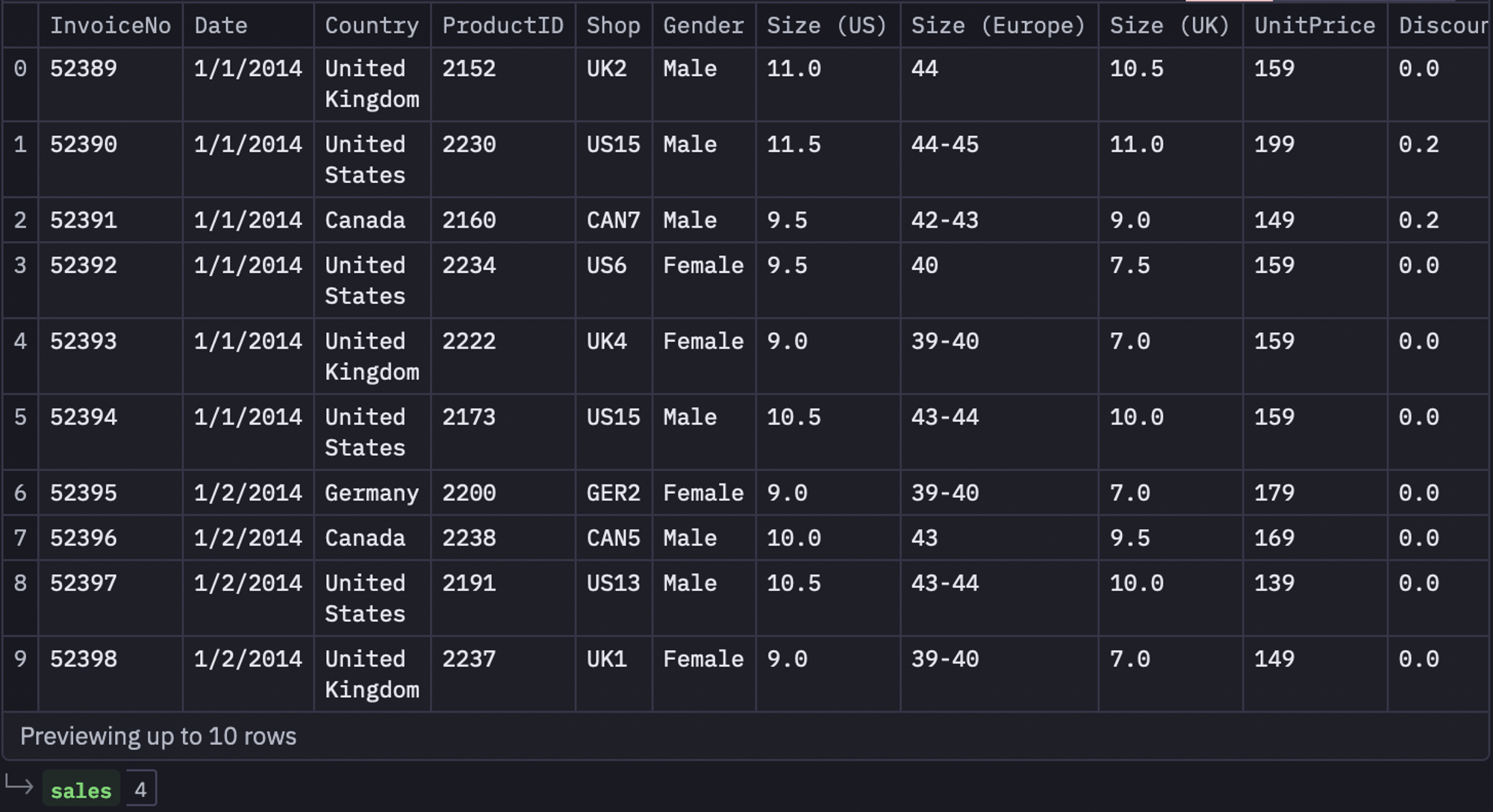
Feature Cleaning
We need to perform the data cleaning on the loaded dataset to make sure there are no null values or missing values. Also, there are some features like Shopor Size (US) in the dataset that we might not require for the analysis, we will be removing them as part of data cleaning. To check the null values, you can use the isnull().sum() method that provides an overview of null values in the entire dataset.
sales.isnull().sum()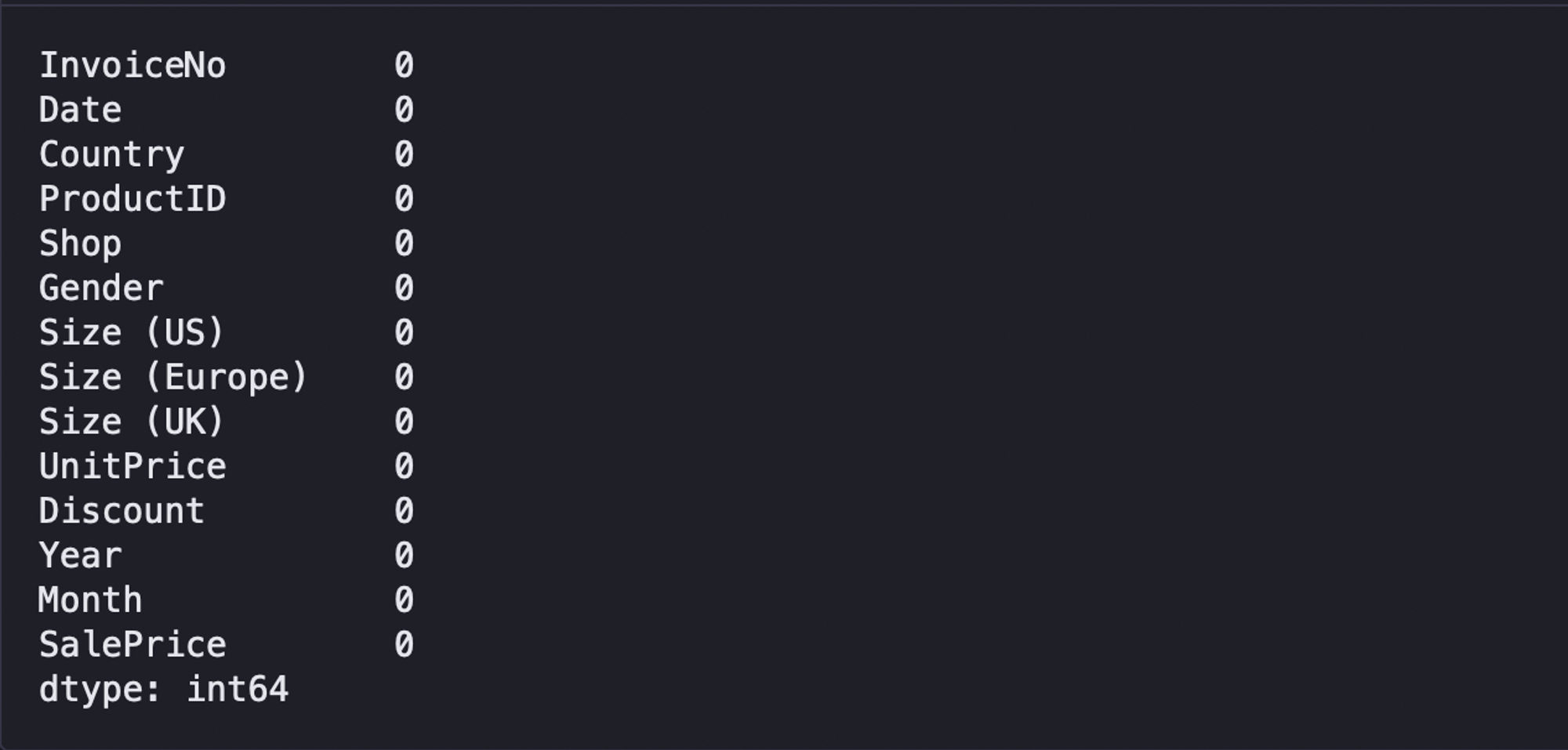
As you can see in the above image, the count of null values in each column equals 0 which indicates there are no null values in any of the columns in the dataset.
Now, let's create a new dataframe sales_mini that will only contain the required features for analysis, and will drop any columns we do not expect to use.
sales_mini = sales.drop(['InvoiceNo', 'ProductID', 'Size (Europe)', 'Size (UK)', 'UnitPrice', 'Discount', 'Date'], axis=1)Our final dataset will only contain the InvoiceNo, ProductID, Size (Europe), Size (UK), UnitPrice, Discount, and Year features.
Data Visualization
A shoe size is typically influenced by various factors some of which are gender, country of origin, and year.
- Gender: Are we looking at the expected outcome for male or female shoe sizes?
- Year: How much data do we want to consider in our analysis?
- Country: What is the country of origin in our analysis?
We will be exploring different combinations of these features to get an accurate representation of what we expect to sell, providing us with more fine-grained control.
Hex provides multiple interactive components like, dropdowns and value fields to read values for different parameters and features. We will first define a dropdown for Gender feature from the dataset as follows:
Once a value is selected for Gender, we will filter our dataset based on that value as follows:
sales_mini_gendered = sales_mini[sales_mini['Gender'] == gender]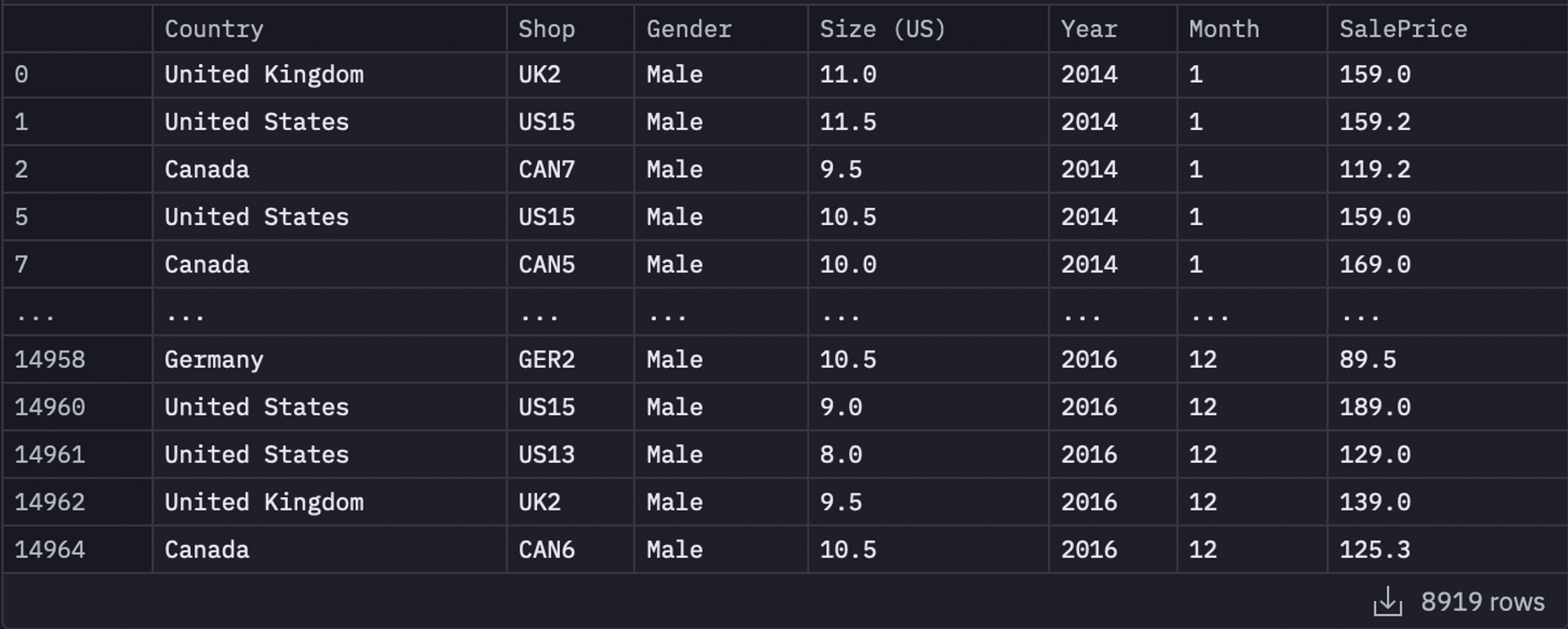
As you can see in the above image, all the entries in the dataset belong to only one (selected) gender.
Next, let's define the Hex dropdown components for Year and Country features from the dataset.

To filter the gendered-filter data further with year and country features, you can use the following lines of code:
df = sales_mini_gendered[sales_mini_gendered['Year'] == year] country_data = df[df['Country'] == country] country_data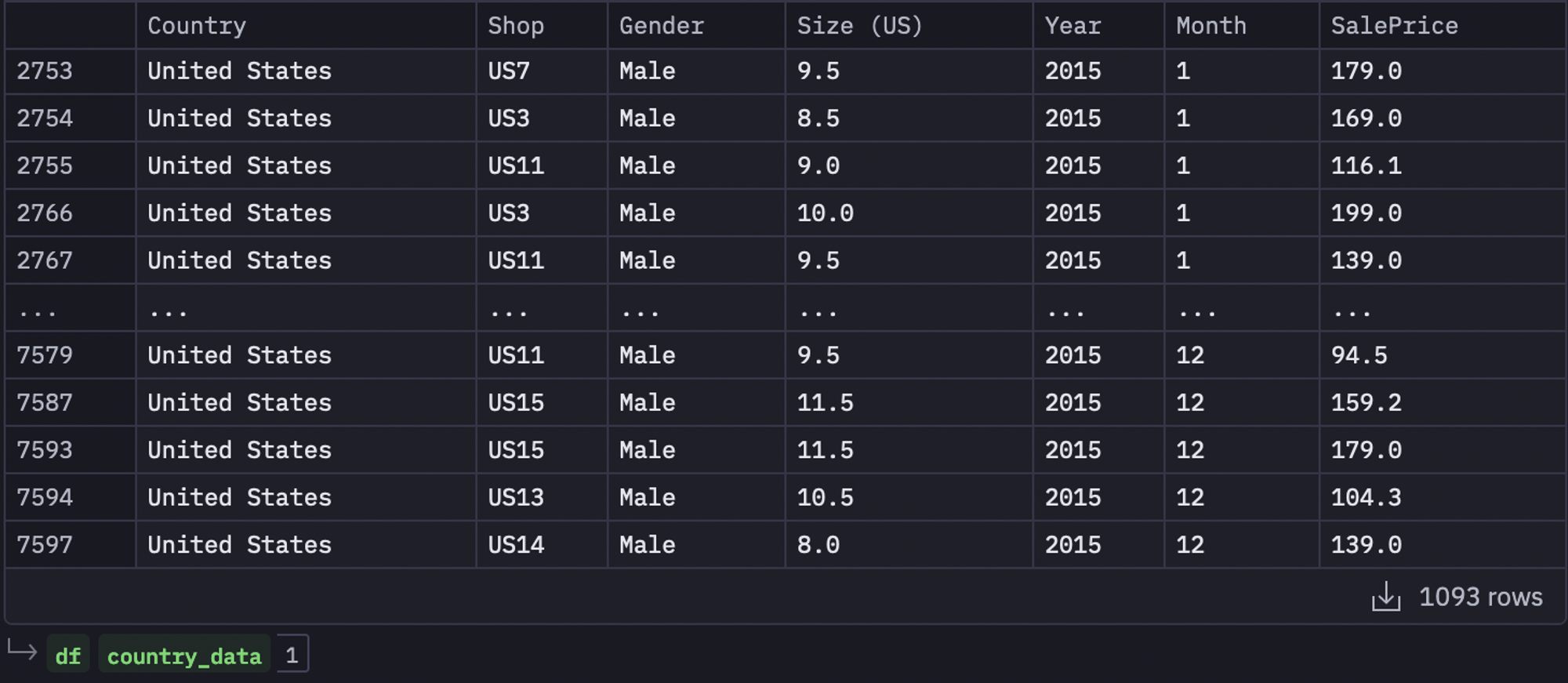
To get a simple picture of how our data is distributed, we will create a pivot table to view the number of sales of each size by month. This is where you can use the no-code cells from Hex that allows you to perform analysis on the data without writing a single line of code. The created pivot table might be something like this:
Next, we will map the months that are represented with the help of numbers in the pivot table to their actual names. For this, we will utilize a special Python package calendar.
results = pivot_result.pivoted
results.columns = [calendar.month_abbr[month[0]] for month in results.columns.to_flat_index().to_numpy()]
Now that the data is ready, it is time to create a plot to analyze the purchase frequency per month for each shoe size. For this, we will use the Seaborn library to plot a heatmap as follows:
plt.figure(figsize=(20, 12)) sns.heatmap(results, annot=True, fmt='g', cmap='magma');
We will also create a plot for how demand is distributed across shoe sizes. For this, let's first calculate the total number of shoes belonging to each shoe size as follows:
results_chart = results.copy() results_chart['Total'] = results_chart.sum(1) results_chart = results_chart.reset_index()[['Size (US)', 'Total']].iloc[:-1, :] results_chart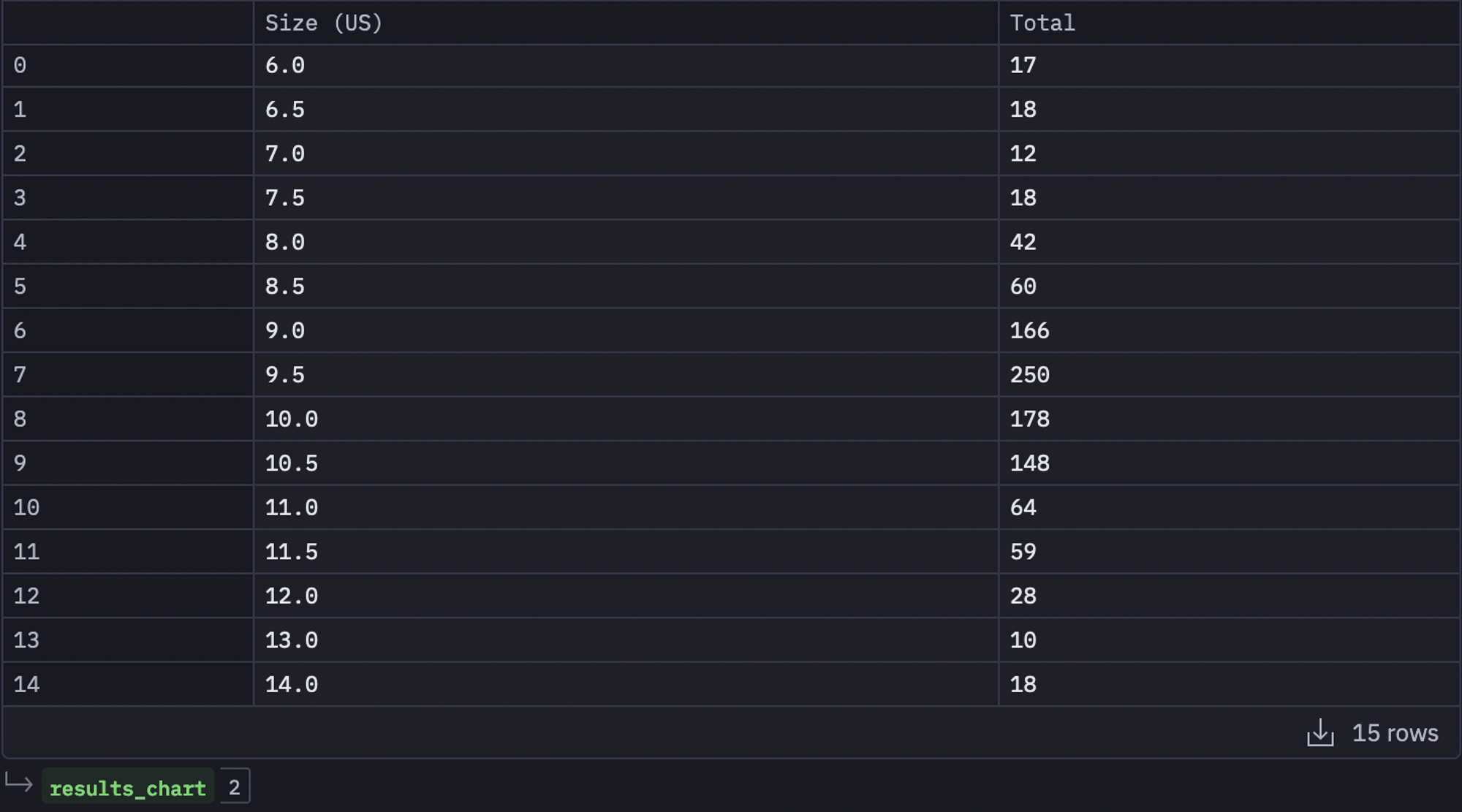
We will then create a bar chart for this data using the nocode cell without writing a single line of code.
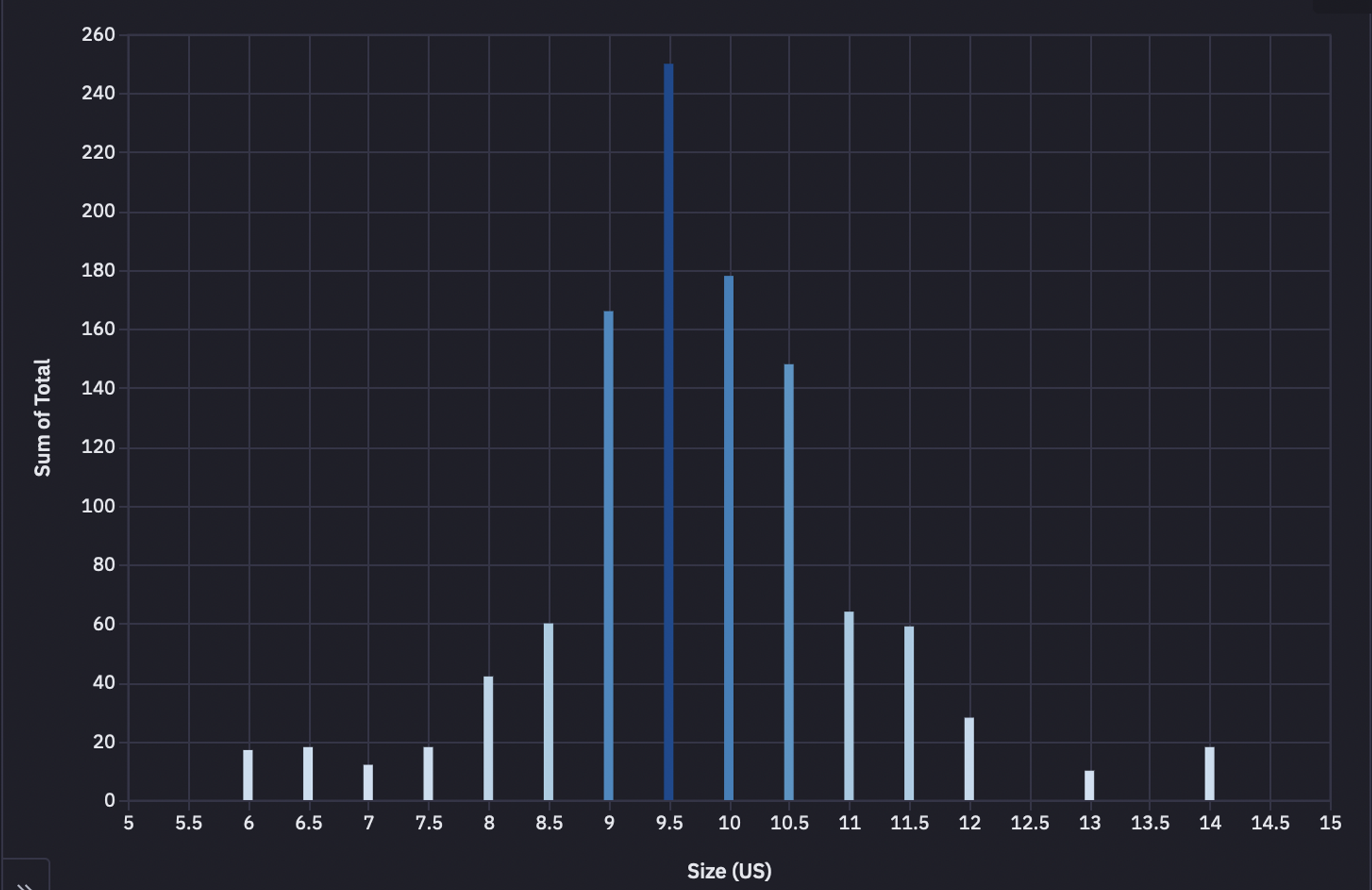
Student's T-test
Since the data that we are using is relatively small, we will use the Student's T-test instead of using a predictive model with Python that requires a relatively larger dataset. We will perform a 2-tailed Student's T-test to determine a stock interval for each size. With 95% confidence, we can assert that the retailer would need their stock levels to be within these intervals for their store to be adequately stocked. To do so, let's start with creating a copy of the results pivot table and then calculate the total sales for each shoe size for each month as follows:
data = results.copy() data.loc['Total'] = results.sum(0) # get the sum of each row (up and down) 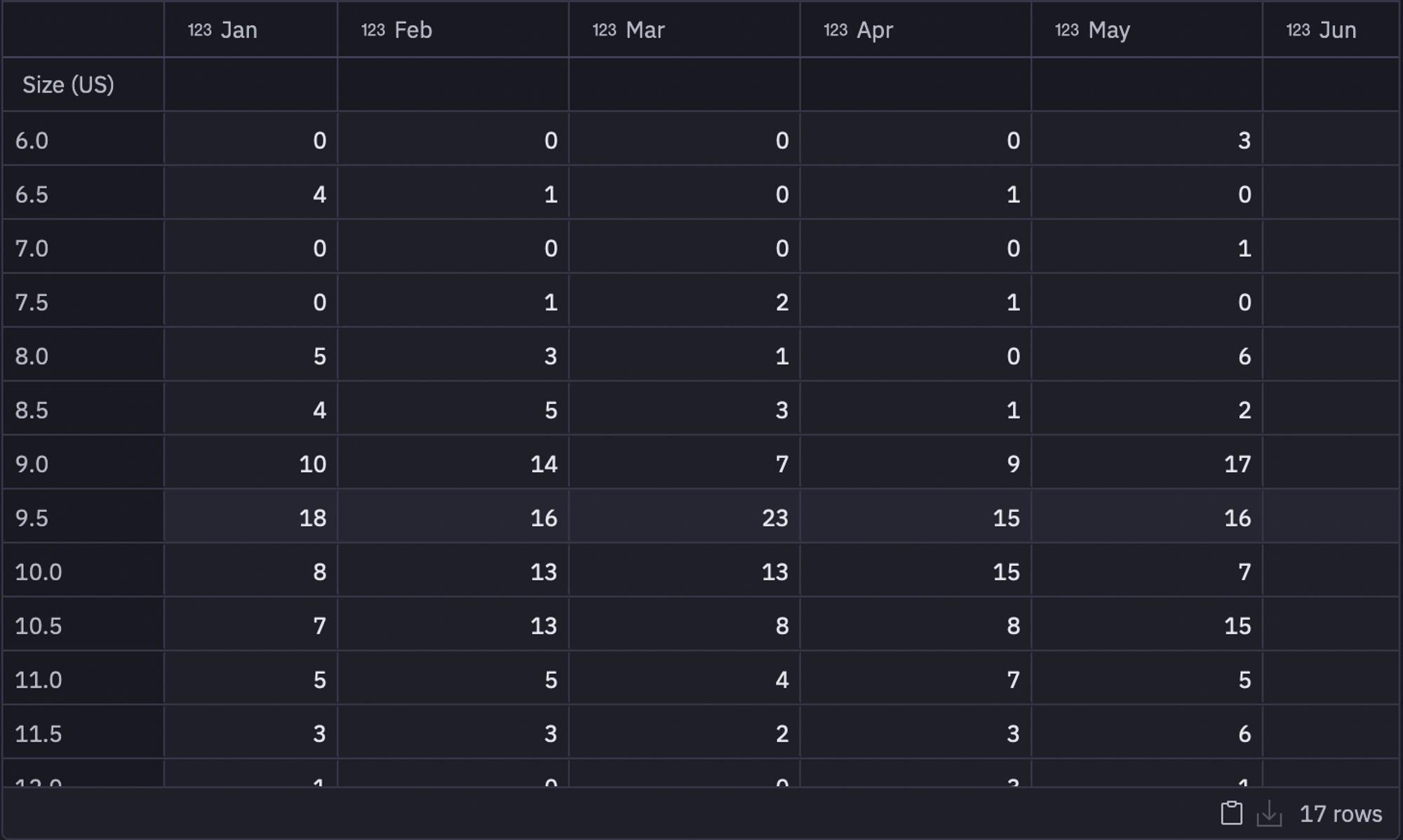
To perform a Student's T-test, we need to calculate the t_value first. The scipy.stats library provides the t.ppf function to look up this value. As our goal is to determine the upper and lower bounds for each stock level, a 2-tailed test is required. Consequently, we use 2.5% (5% divided by 2) instead of 5% when looking up the t-value.
t_value = stats.t.ppf(1 - 0.025,11) t_value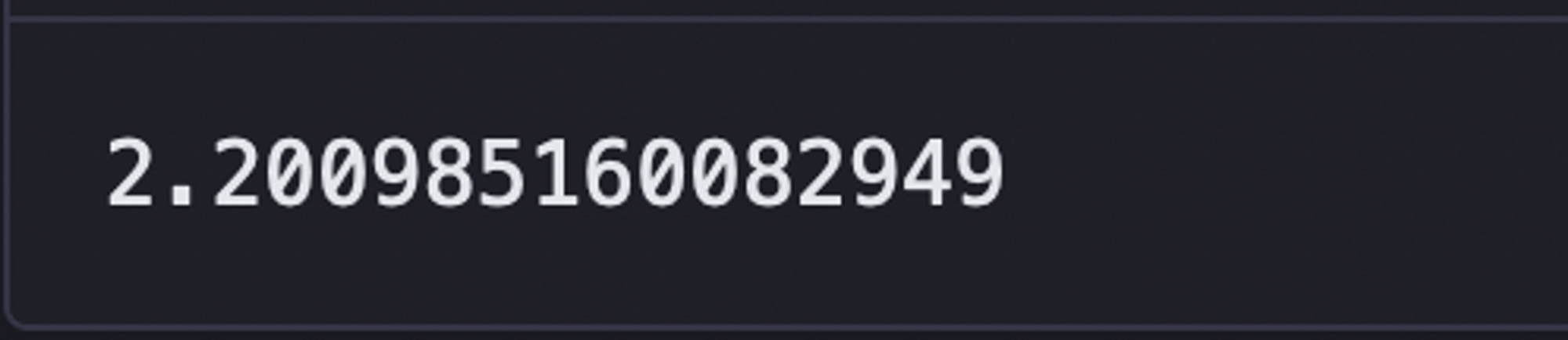
We will now display our aggregates in a new dataframe. We will utilize the sem() function from the pandas library to compute the standard error. In order to determine the margin error, we will multiply the standard error by the t_value. We will calculate our lower and upper bounds by subtracting and adding the margin error from the mean, respectively.
sizes = data.index
avg_size = data.mean(1)
std_err = data.sem(1)
margin = std_err * t_valuevalues = {
'Size': sizes,
'Average size': avg_size,
'Standard error': std_err,
'Margin of error': margin,
'Lower bound': avg_size - margin,
'Upper bound': avg_size + margin
}inventory_stats = pd.DataFrame(values)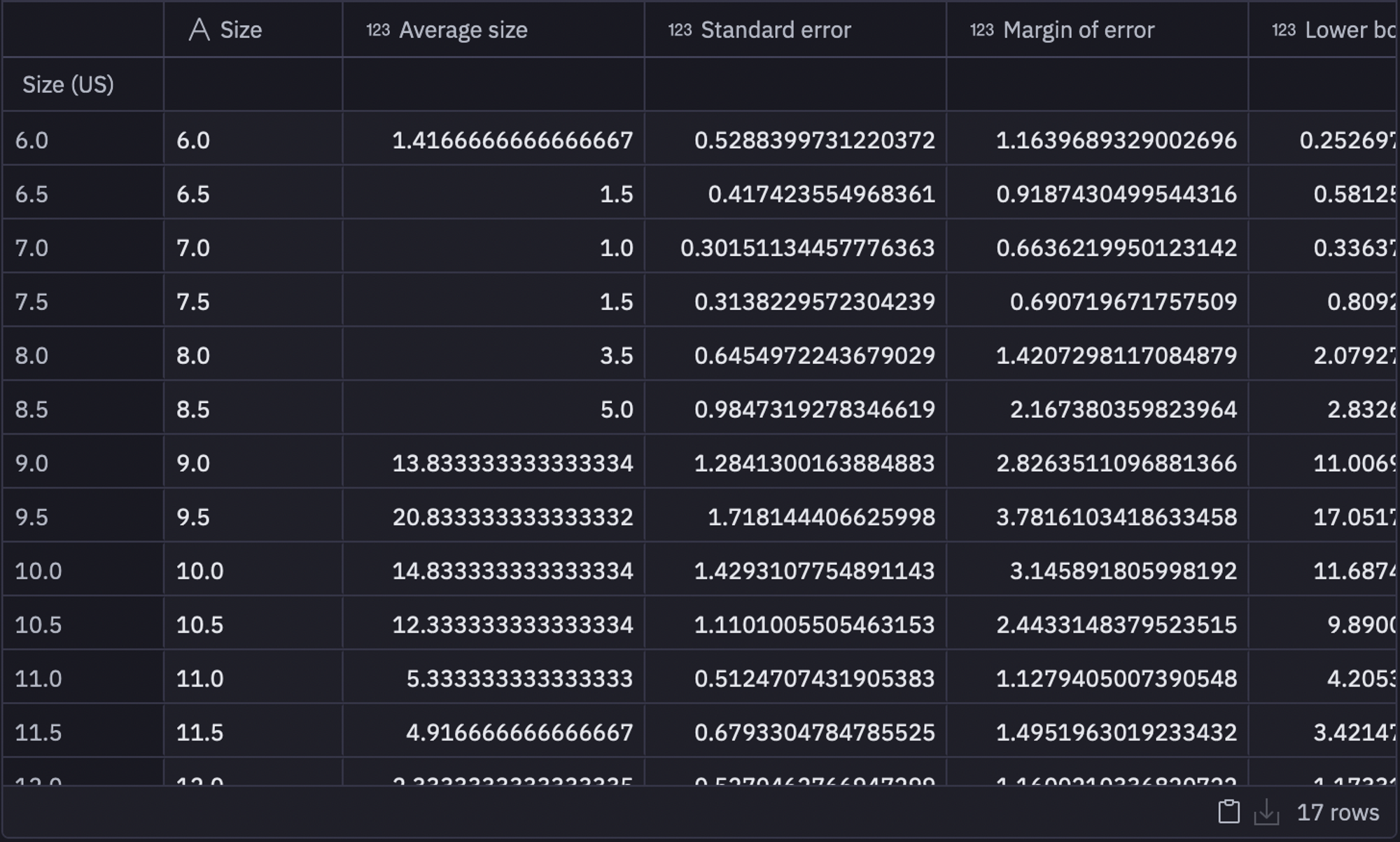
As you can see in the above image, we now have our lower and upper bounds for each shoe size that can be utilized further to manage the inventory.
Inventory Reports
Based on the above analysis of our previous year's sales data, we will now generate reports that will provide insights into the expected sales volume and revenue for each month. These reports will help us predict the anticipated customer traffic and estimate the potential revenue we can generate from these sales.
For this, we will only focus on the Lower Bound and Upper Bound features of our inventory_stats dataframe. To make information more interpretable, we will calculate the ceil of the lower bound and the floor of the upper bound.
conclusion = pd.DataFrame()
conclusion['Size'] = inventory_stats['Size']
conclusion['Lower bound'] = np.abs(inventory_stats['Lower bound'].apply(np.ceil))
conclusion['Upper bound'] = inventory_stats['Upper bound'].apply(np.floor)
conclusion = conclusion.iloc[:-1, :]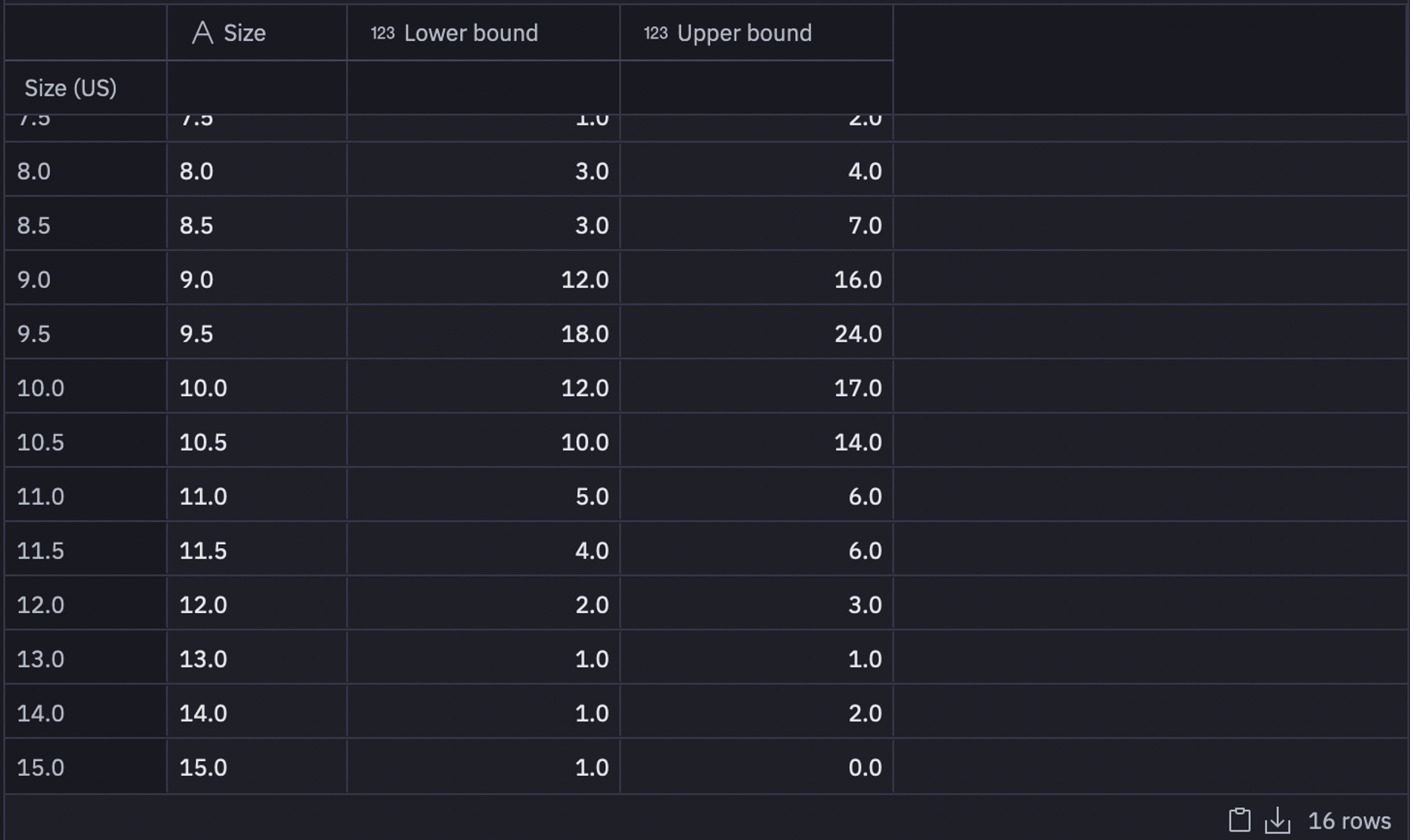
Next, let's add a selection component of Hex to select the sizes feature to estimate the average revenue for each shoe size category.
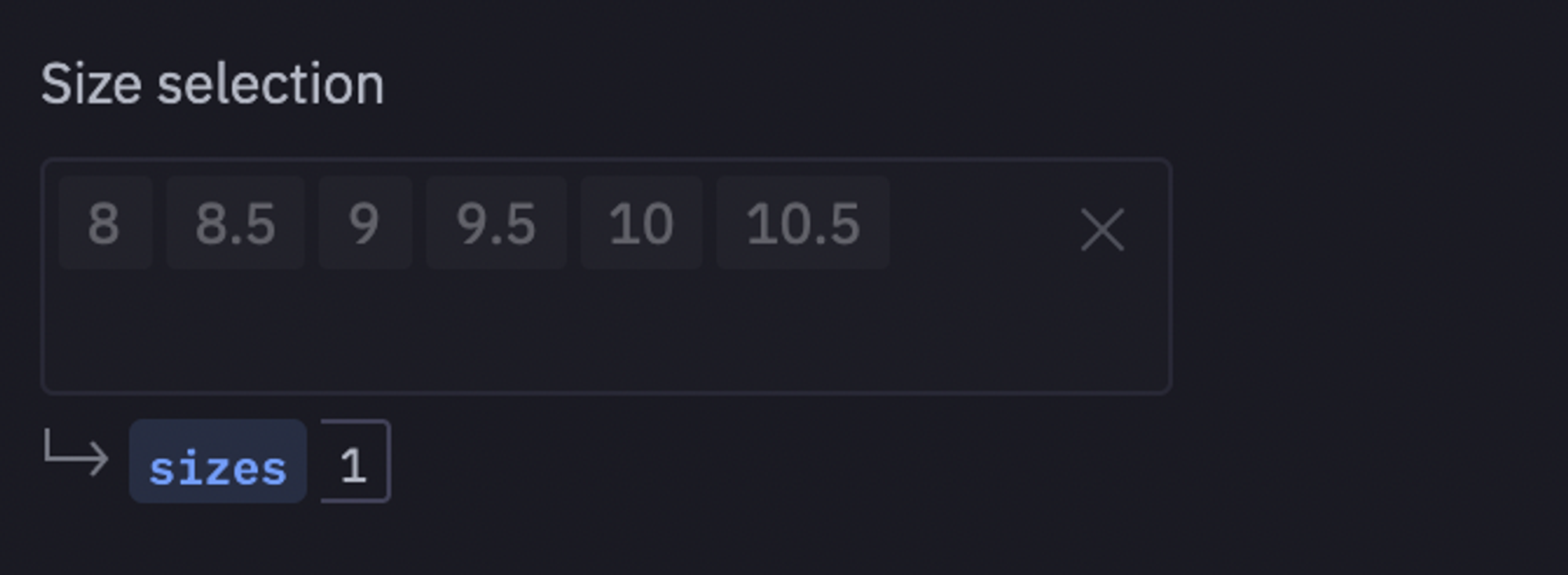
Once defined, we will create a Python method average_revenue_estimatation() that will filter the sales amount for each selected shoe category.
def average_revenue_estimatation(shoe_size, amount_sold):
frame = sales.copy()
size_mask = frame['Size (US)'] == shoe_size
country_mask = frame['Country'] == country
frame = frame[size_mask & country_mask] # average unit price for the selected shoe size in the selected country
average_price = frame['UnitPrice'].mean()
print(f'Average price: {average_price}')
return np.round(average_price * amount_sold, 2)lower_bound = lambda size: conclusion[conclusion['Size'] == size]['Lower bound'].to_numpy()[0]
upper_bound = lambda size: conclusion[conclusion['Size'] == size]['Upper bound'].to_numpy()[0]Let's also simplify the Gender, instead of using "Male" and "Female" as feature values, we will use "men" and "women".
gen = 'men' if gender == 'Male' else 'women'Finally, let's not show all the data (i.e. all the shoe sizes) in a single list instead let's split them into two different lists as follows:
def split_list(a_list):
half = len(a_list)//2
return a_list[:half], a_list[half:]l1, l2 = split_list(sizes)Now you are all ready to check some of the useful information for inventory management. For a selected year, and select shoe sizes, you can clearly estimate the minimum (lower bound) and maximum (upper bound) sales. You can use the markdown cells in Hex to present the text and variables used throughout the notebook as follows:
{% for size in l1 %}{% set low = lower_bound(size) %}
{% set high = upper_bound(size) %}## Inventory: Size {{size}} {{gen}}
Based on the `{{year}}` data in {{country}}, our shoe store is projected to sell a minimum of **{{low}}** pairs of shoes and potentially up to **{{high}}** pairs. This sales volume is estimated to generate a revenue ranging from *${{average_revenue_estimatation(size, low)}} - ${{average_revenue_estimatation(size, high)}}*{% endfor %}
Now that you are done with the implementation part, you can head over to the App Builder section of the Hex environment. You will notice that there is a dashboard already created for you while you were doing the implementation. The components of this dashboard are adjustable, you can drag and drop them to the desired location as you see fit. Once you feel that the dashboard looks good enough, you can click on the publish button to deploy this dashboard.
You have now created an inventory management system, created a dashboard for it, and finally deployed it with a few simple steps in Hex.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.




Ready to get started?
You can use Hex in two ways: our centrally-hosted Hex Cloud stack, or a private single-tenant VPC.