
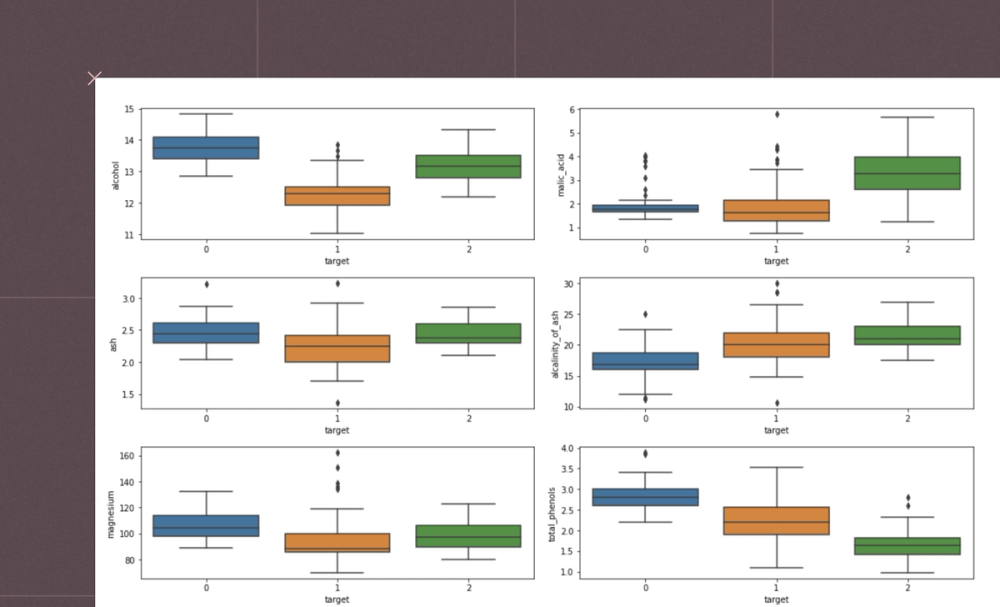
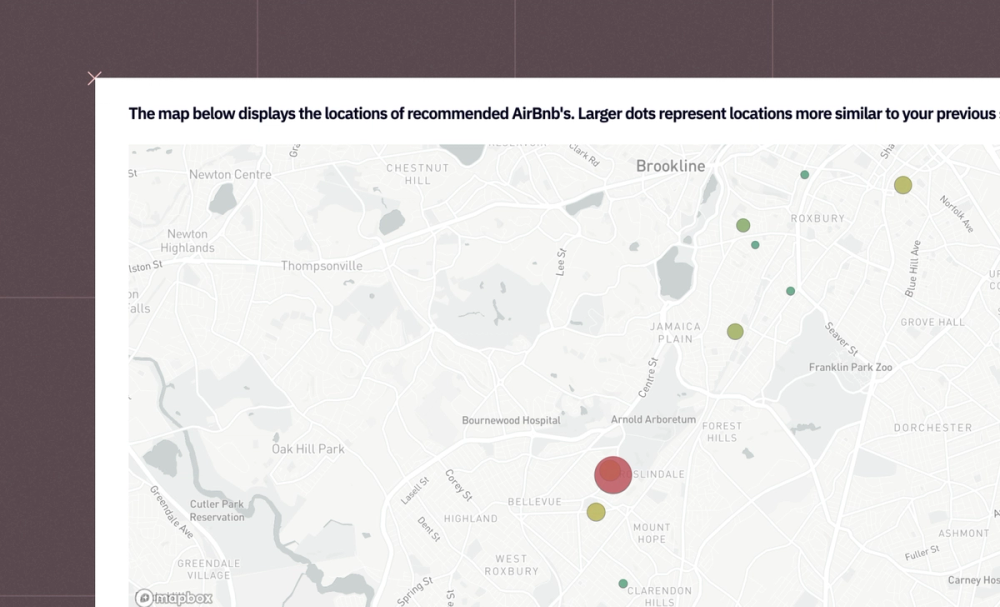
Don't see what you need?
We're always expanding our collection of examples and templates. Let us know what you're working on, and we'll whip up an example just for you.
A quick guide to Data Modeling
In the age of information, understanding customer behavior is pivotal to increasing sales. This understanding comes from analyzing customer purchases and transaction data, which can be achieved through the effective application of Machine Learning (ML) algorithms and data modeling techniques. In this context, recommendation models play a vital role.Recommendation systems come in various types. The two most prevalent forms are content-based filtering and collaborative filtering. In the former, recommendations are made based on the similarity between items, while in the latter, similar users' behaviors are leveraged to suggest products.
Building recommendation engines in Python
Product Affinity Analysis in Python is a commonly used technique for building recommendation engines. One of the most popular libraries to perform this task is MLxtend. Its frequent_patterns module includes the Apriori algorithm, which is ideal for discovering frequent itemsets in transaction data. These are combinations of items frequently purchased together, essential for understanding product and brand affinity.In Market Basket Analysis, cross selling, where customers are encouraged to buy related or complementary items, can significantly enhance sales. The frequent itemsets discovered by the Apriori algorithm can be useful in these strategies. It enables identifying items that are likely to be bought together, facilitating the promotion of such combinations.# Import the necessary libraries import pandas as pd from mlxtend.preprocessing import TransactionEncoder from mlxtend.frequent_patterns import apriori# Suppose we have a list of transactions transactions = [['milk', 'bread', 'butter'], ['beer', 'bread'], ['milk', 'beer', 'butter'], ['milk', 'bread']]# Encode the data into a transaction matrix te = TransactionEncoder() te_ary = te.fit(transactions).transform(transactions)# Create a DataFrame df = pd.DataFrame(te_ary, columns=te.columns_)# Generate frequent itemsets using the Apriori algorithm frequent_itemsets = apriori(df, min_support=0.5, use_colnames=True) print(frequent_itemsets)The apriori function returns the items that have a support value greater than the specified minimum support (0.5 in this case). The use_colnames=True argument means you're using item names instead of integer column indices.This is a simple recommendation system that suggests items based on the frequency of itemsets. For instance, if bread and butter are frequently purchased together, promoting butter when a customer buys bread can encourage additional sales. You can further enhance it by implementing association rules, which can measure itemset importance and make more complex recommendations.In tandem with this, hot encoding of transaction data can be beneficial in processing large volumes of data. This technique transforms categorical data into a format that can be better understood by ML algorithms. This preprocessing stage, though sometimes overlooked, can considerably impact the accuracy of the resulting recommendation models.
Advanced data modeling
A more advanced approach includes using community detection algorithms in the context of recommendation systems. In this method, customers are seen as nodes in a network, and transactions between them are viewed as links. Identifying communities within this network can unearth patterns otherwise hidden in the data, providing valuable insights into customer purchasing behaviors.Moreover, the integration of domain knowledge can significantly improve the effectiveness of recommendation models. Incorporating understanding about the business and its customers can help refine these models, ensuring they are more aligned with the real-world scenarios they are intended to mimic.Finally, a personalized recommendation system developed in Python can offer unique benefits. It can provide product recommendations tailored to each user, thereby increasing the likelihood of sales and enhancing customer experience. Through such systems, recommendations can be made based on a user's individual purchase history, their preferences, and the behavior of similar users.Leveraging ML algorithms and various data modeling techniques can provide a deeper understanding of customer behavior, brand and product affinity, and enable effective cross selling. This can result in an optimized marketing strategy and, ultimately, increased sales. Following these best practices, businesses can make data-driven decisions to secure their competitive advantage in the market.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.




FAQ
Can't find your answer here? Get in touch.