Data science the way it should be
Everything you need to go from prototype to production to impact in record time.
"Hex has the most delightful data science notebook ever. Hex combines a SQL/python development environment with native visualizations and input widgets. This is the magic sauce; data scientists can both experiment and deploy models to users in one go.”
Joel S. Senior Data Scientist
More models, less mania
End your fragmented, tool-hopping workflow with Hexʼs collaborative, do- anything, go-anywhere canvas for data science.

Get a head start
Hexʼs scalable cloud environment is ready with common Python packages and connections to governed data.
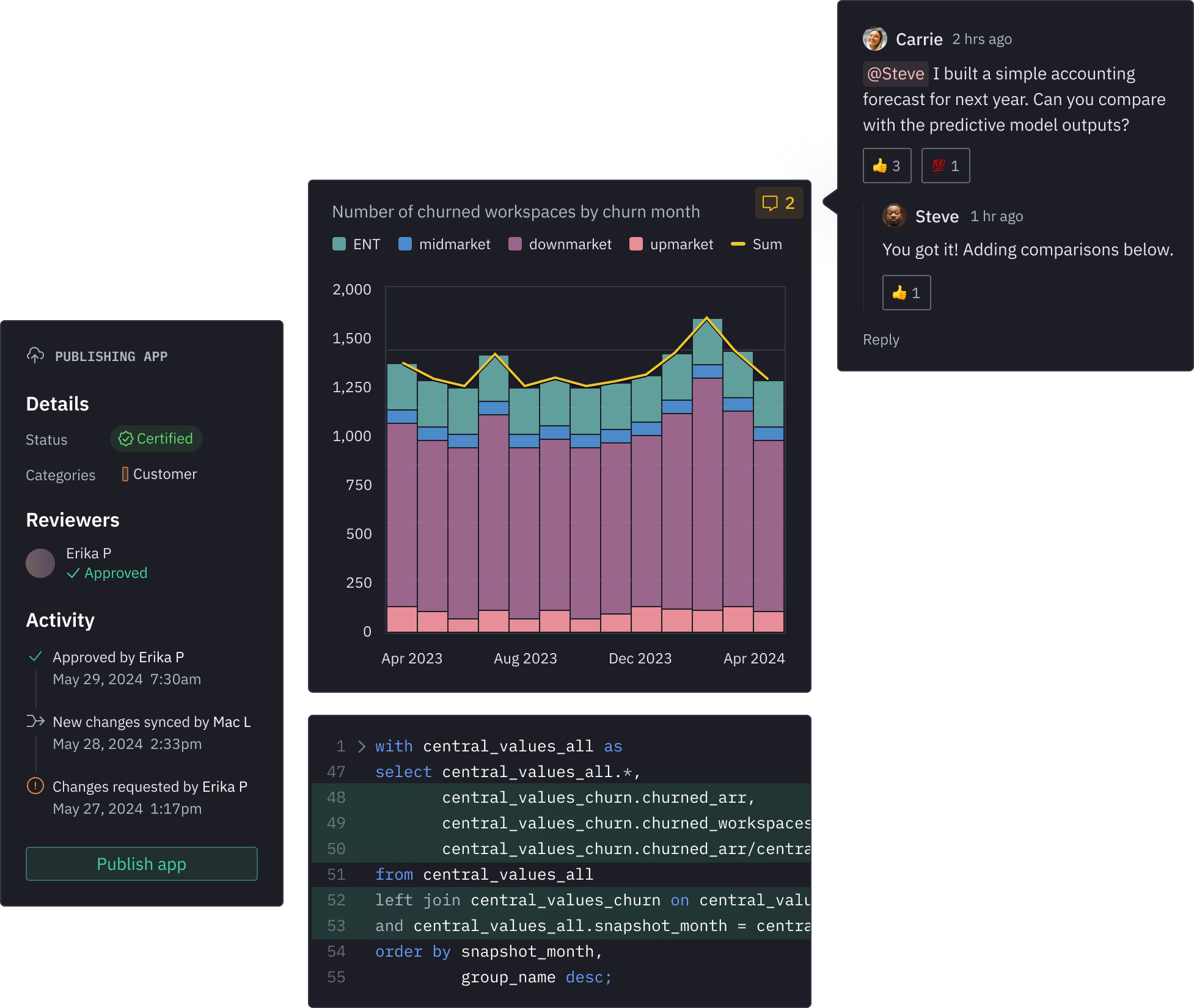
Build together or build upon
Work side-by-side in the same notebook, ask for a peer review, or use someone elseʼs project as a starting point.
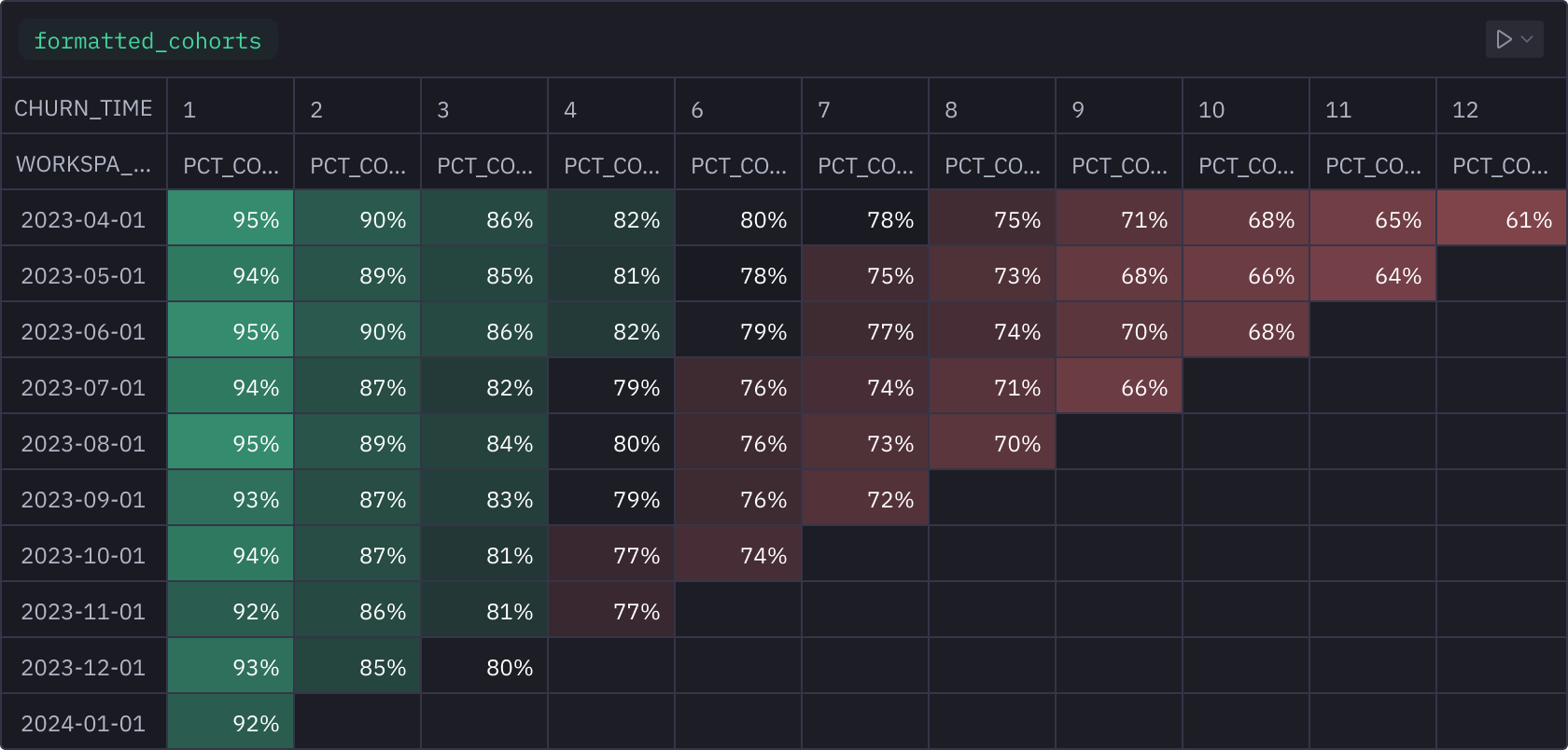
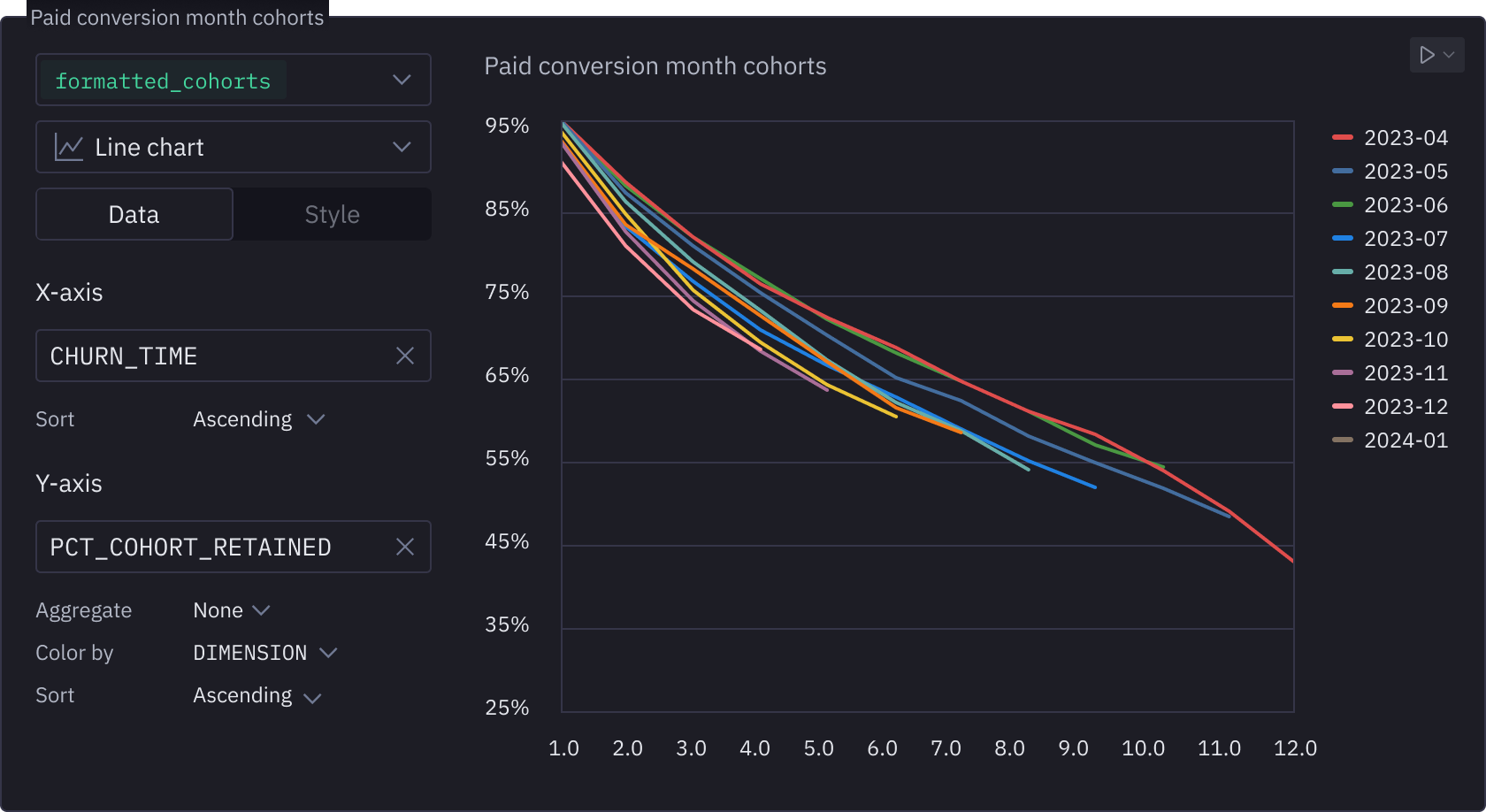
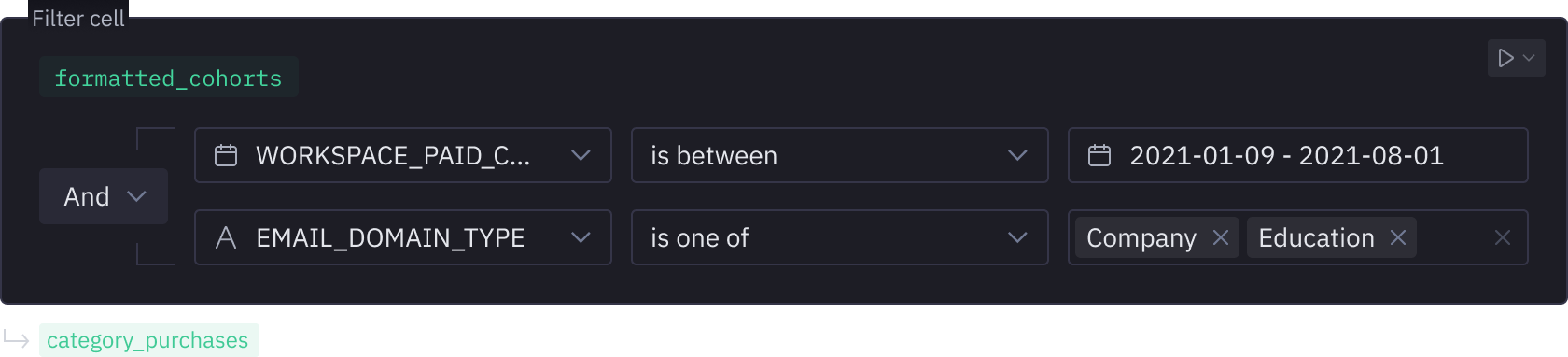
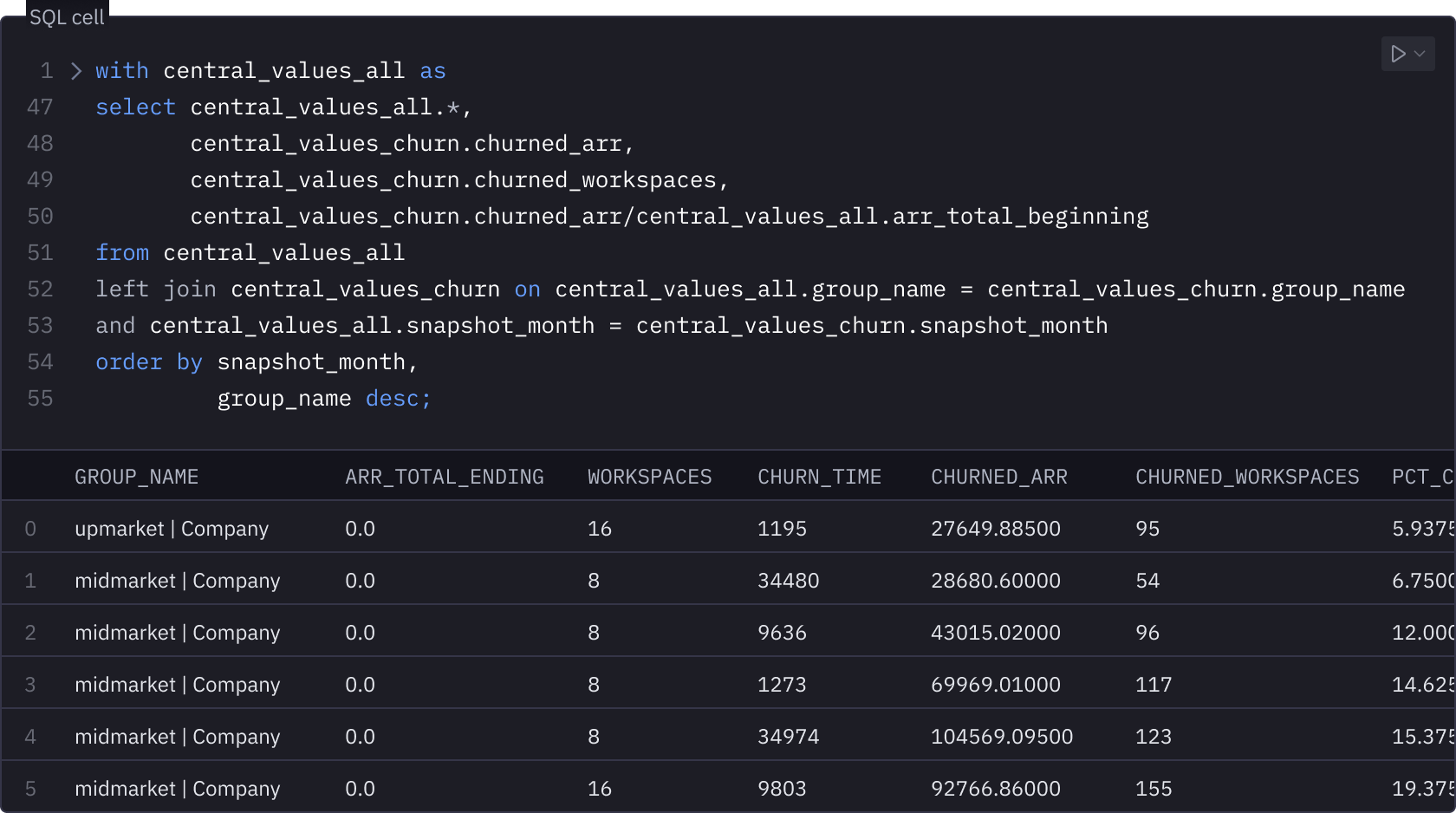

Everything, altogether, all at once
The right tool is always at the ready. Chain Python, SQL, pivots, formulas, and no-code viz interchangeably in Hexʼs multi-modal notebook.
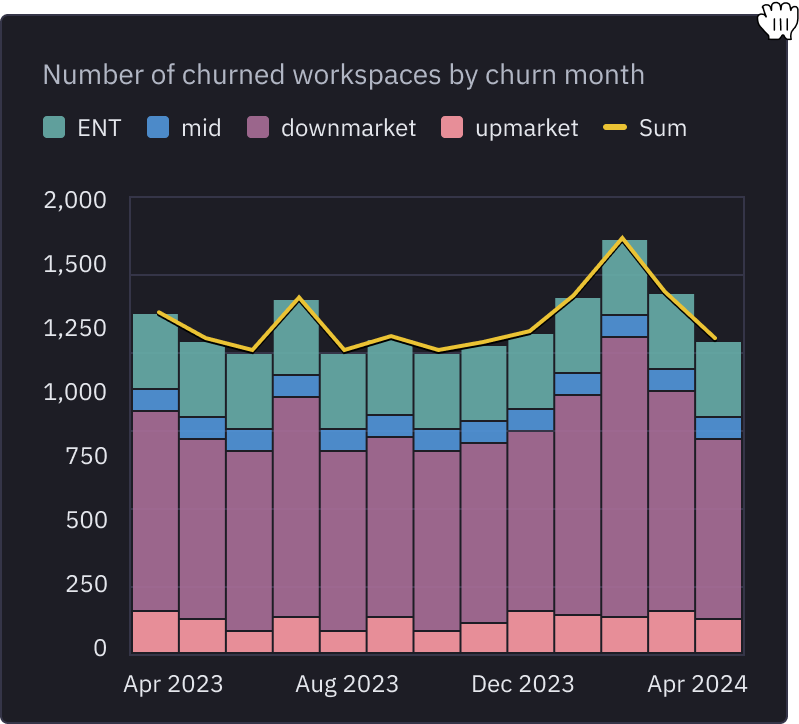
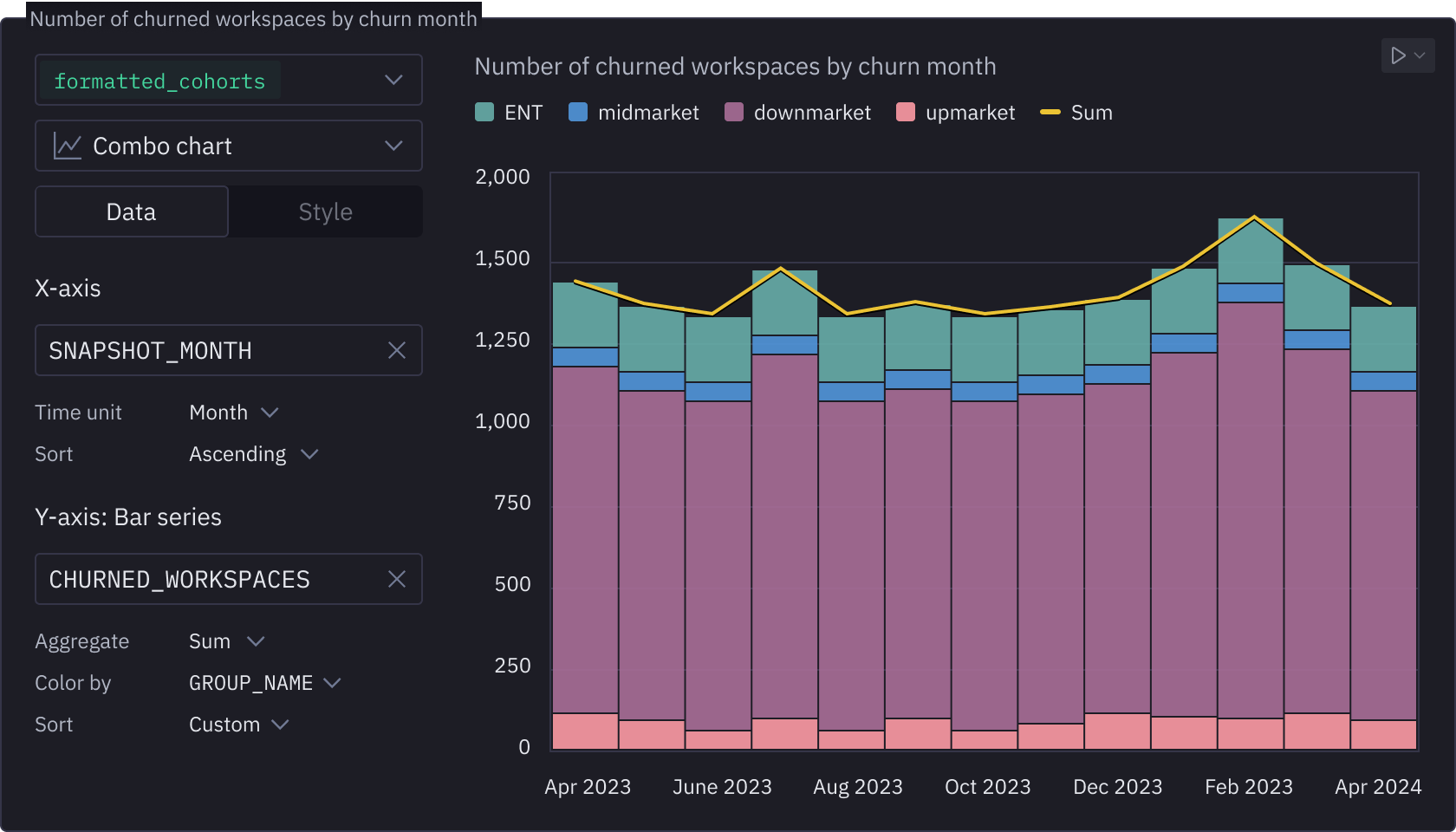
Drive business action
That model doesnʼt belong in a dashboard. Empower stakeholders with data apps to tailor outputs to their program, project, or decision.
AI-Accelerated
No more hunting for obscure syntax. Just ask AI in Hex to draft a script, fix a bug, or scaffold an entire project.
Developer touches that make you say “ahhhˮ
Data science in Hex feels easier because it IS easier.
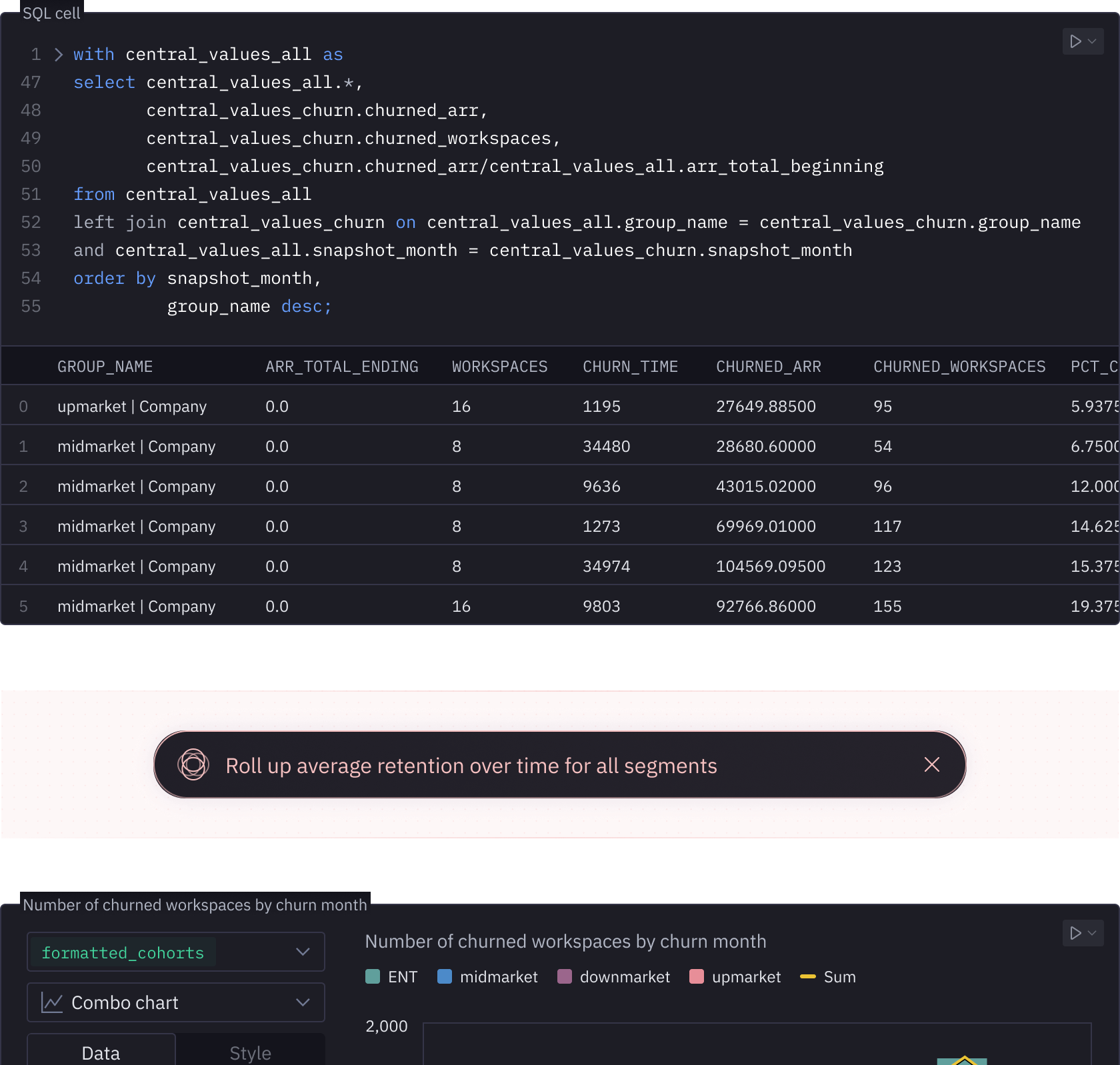
Interpretable, reproductible, performant
Reactive, graph-based compute model helps you visualize dependences and only re-execute downstream logic when changes are made.
Learn More
Version-controlled
Automatically track and store history so itʼs easy to understand changes and revert back to previous versions.
Learn More
Easily automated
Schedule projects to run on a cadence you choose. Set up notifications in Slack for successes and failures.
Learn More
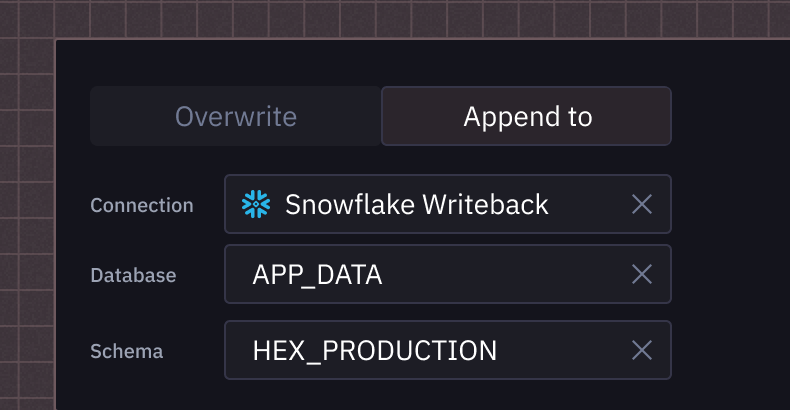
Database writebacks
Create, replace, or append results of a dataframe to tables in your warehouse.
Learn More
Get started fast with components and templates
Start from commonly used query logic unique to your organization or use one of Hexʼs pre-built templates.
Questions? Talk to us
Get in touch with us to see a demo or find out which plan is right for you.