Unearth hidden insights and power business decisions with machine learning— or just good old applied statistics.
Featured
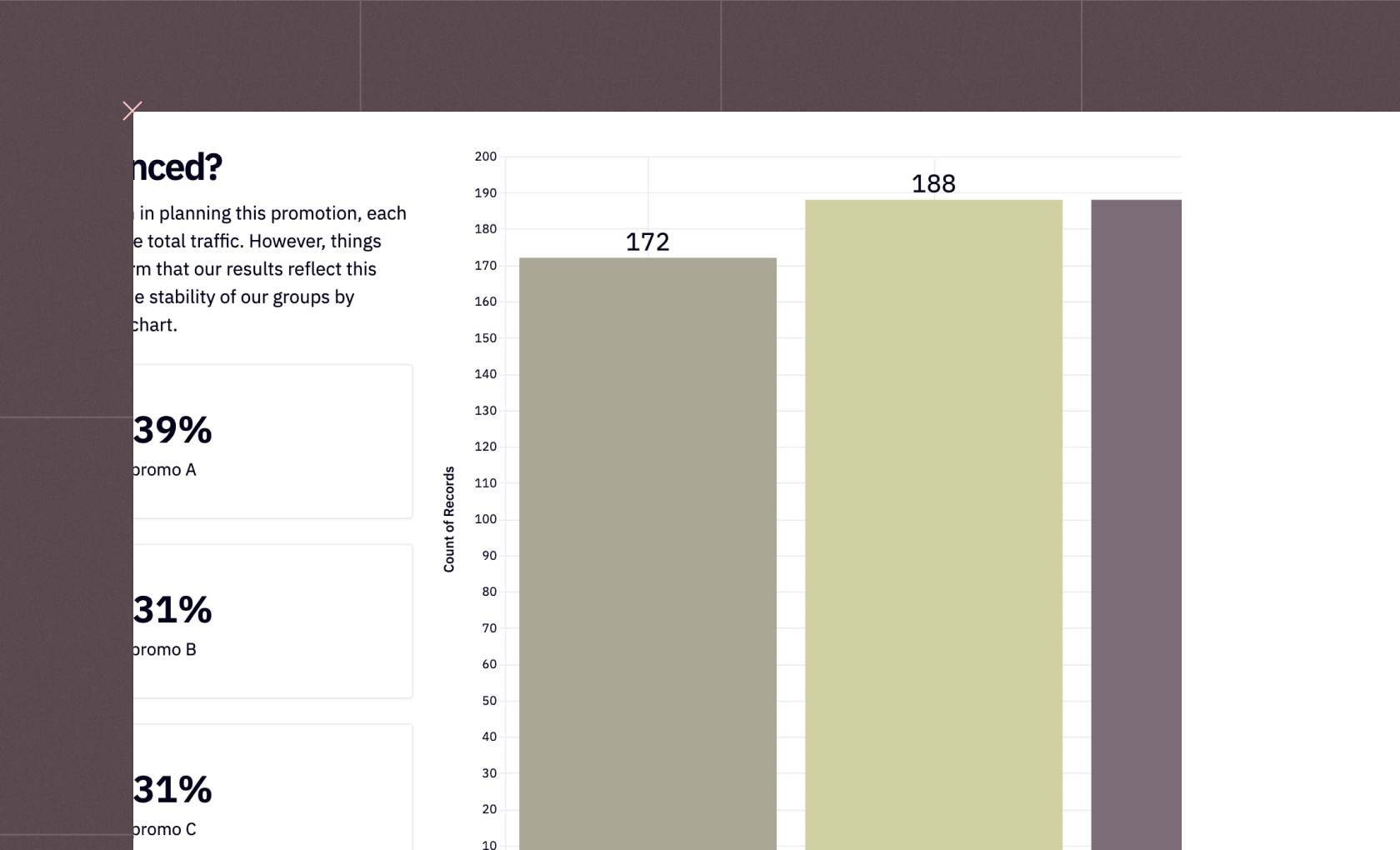
A/B testing
Scientifically optimize features and messaging
dbt Audit Helper
Validate dbt PRs and document changes with a Hex UI
Churn Prediction
Izzy Miller
Hex is a powerful development environment for churn prediction. It supports SQL, Python & R. It makes it easy to deploy accurate and scalable models.
ML Model Development
Izzy Miller
Build, test, and deploy powerful ML models
Build, test, and deploy powerful ML models
Izzy Miller
Hex is the most powerful development environment for prototyping and deploying predictive models. Get started with Hex and direct SQL access to your data warehouse, a polyglot environment for developing and deploying models, and a built in app builder.
Outlier Detection
Izzy Miller
Detect and analyze anomalies in your dataset using robust Outlier Detection methods.
Anomaly Detection
Detect and analyze anomalies in your dataset with a combination of sklearn and native tools
Don't see what you need?
We're always expanding our collection of examples and templates. Let us know what you're working on, and we'll whip up an example just for you.
How many users will visit your website next week? How do you suggest items to customers that they actually want to buy? Which version of this paragraph you’re reading right now will cause you to stay on the page longer? How many Taylor Swift songs in one Release Radar playlist is too many? These are the kinds of questions that you can answer with data science. It’s an umbrella term, and there’s a lot of industry jargon, but data science can be broadly defined as the process of extracting meaningful insights from data.
In simple terms, this process includes:
Deciding what questions you can (and should) ask of your data
Obtaining and processing data into a usable format
The actual answering of questions or extracting insights from the data— or building predictive models to forecast future data or simulate scenarios
And crucially: the presentation and communication of these insights to others, so that action can be taken.
From extracting insights from unstructured data to creating predictive models using machine learning, data science is an incredibly important function, with the potential to have major business impact if done right. It is also a complex field to master, with many complex subtopics and specializations to understand. This page provides interactive and explanatory examples of some of the most common data science use cases and subtopics. If you see something interesting, click “Get a copy” to start exploring and customizing any example for yourself.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.
BLOG
One Chart Forward, Two Queries Back
Matt Palmer · August 22, 2023
See how using an end to end tool like Hex makes iterating on an analysis faster than using multiple tools
BLOG
Building a Builder
Sean Mateer · March 29, 2022
Designing and engineering a new app layout engine from scratch
BLOG
Why, when and how to use a first-touch attribution model
Caleb Bowie · July 17, 2023
How we answer the two most important questions for any marketing activity: “Was it worth it?” and “What should we do differently next time?”
BLOG
How collaboration changes everything, from design to data
Adam Storr · September 13, 2022
Leaving fragmentation, local files, and version control hell in the past
BLOG
Planning a Modern Datathon
Izzy Miller · February 15, 2022
How to run a hackathon for data in the age of the modern data stack
BLOG
Hex for Analytics Engineers: Data Transformation
Erika Pullum · April 14, 2022
Streamlining analytics engineering workflows with Hex
FAQ
What is the difference between data science and data analytics?
While both data science and data analytics involve working with data, they differ in scope and approach. Data analytics primarily focuses on analyzing historical data to provide insights on what has happened. Data science, on the other hand, uses complex algorithms and predictive models to understand what might happen in the future.
Why is Python commonly used in data science?
Python's popularity in data science is due to its simplicity and wide range of libraries and frameworks like Pandas, NumPy, and Matplotlib, which simplify tasks such as data cleaning, analysis, visualization, and predictive modeling.
What skills do I need to become a data scientist?
Core skills include a good grasp of mathematics and statistics, programming skills (primarily in Python or R), knowledge of machine learning algorithms, and data wrangling and analysis. Also crucial are visualization skills, domain knowledge, and the ability to communicate complex results clearly.
What are the different types of data in data science?
Data can be structured (organized in a defined manner like SQL databases), unstructured (not organized in a pre-defined manner, such as text, images, and social media posts), or semi-structured (a mix of the two, like JSON files).
What is big data and how does it relate to data science?
Big data refers to extremely large datasets that are often too complex to be dealt with by traditional data-processing software. Data science techniques are employed to extract meaningful insights from these big data sets.
What is the role of data cleaning in data science?
Data cleaning is the process of detecting and correcting or removing corrupt, inaccurate, or irrelevant parts of data. As the quality of data significantly affects the outcome of data analysis, data cleaning is a critical step in the data science process.
What is a predictive model in data science?
A predictive model is a mathematical tool that uses historical data to predict future outcomes. It identifies patterns in the data and applies these patterns to forecast future events.
What's the significance of data visualization in data science?
Data visualization involves presenting data in a visual context, such as charts or graphs, to help stakeholders understand complex patterns within the data. It aids in making data-driven decisions by allowing clear and quick interpretation of data and its trends.
What are some common challenges in data science?
Challenges include dealing with messy and large datasets, ensuring data privacy and security, communicating complex results to non-technical audiences, and staying updated with the latest tools and techniques in the rapidly evolving field of data science.
What are the key steps in a data science process?
The key steps include identifying the problem or question, collecting and cleaning the data, exploring and analyzing the data, building and evaluating models or hypotheses, and finally, presenting and communicating the findings.
What is machine learning in data science?
Machine learning is a key component of data science that involves creating and using algorithms to make predictions or decisions without being explicitly programmed to do so. Applications include recommendation systems, image recognition, and natural language processing. These algorithms learn from data and improve their performance over time, enabling data scientists to generate insights, forecast trends, and create data-driven solutions.
How do you learn data science?
Learning data science involves acquiring skills in mathematics, statistics, programming (particularly in Python or R), and machine learning. You can learn these through online courses, textbooks, tutorials, or degree programs. Working on practical projects and problems, and understanding domain knowledge is also vital for applying data science concepts effectively.
What is NLP in data science?
NLP, or Natural Language Processing, is a subfield of data science that focuses on the interaction between computers and human language. It involves teaching machines to understand, interpret, generate, and manipulate human language, enabling applications such as language translation, sentiment analysis, speech recognition, and chatbots.
What is EDA in data science?
EDA, or Exploratory Data Analysis, is an approach in data science where one analyzes datasets to summarize their main characteristics, often using statistical graphics and other data visualization methods. It helps to understand the data, identify patterns, spot anomalies, test hypotheses, and check assumptions.
What is feature engineering in data science?
Feature engineering is the process of transforming raw data into features, or input variables, that better represent the underlying patterns in the data, thereby improving the performance of machine learning models. It involves steps like handling missing data, dealing with outliers, and creating interaction features to capture complex relationships.
How do you learn Python for data science?
Learning Python for data science involves understanding Python's basic syntax and control structures, and then learning to use key libraries like Pandas for data manipulation, NumPy for numerical computations, Matplotlib for visualization, and Scikit-learn for machine learning. Various online courses, books, tutorials, and hands-on projects are available to help you master Python for data science.