




Don't see what you need?
We're always expanding our collection of examples and templates. Let us know what you're working on, and we'll whip up an example just for you.
A quick guide to Natural Language Processing
Natural Language Processing (NLP), an integral branch of Artificial Intelligence (AI), is about making machines understand and respond to human language, thereby bridging the gap between human communication and machine understanding. Through NLP algorithms, AI applications can interpret, recognize, and even generate human language in a meaningful and useful way.
What is NLP?
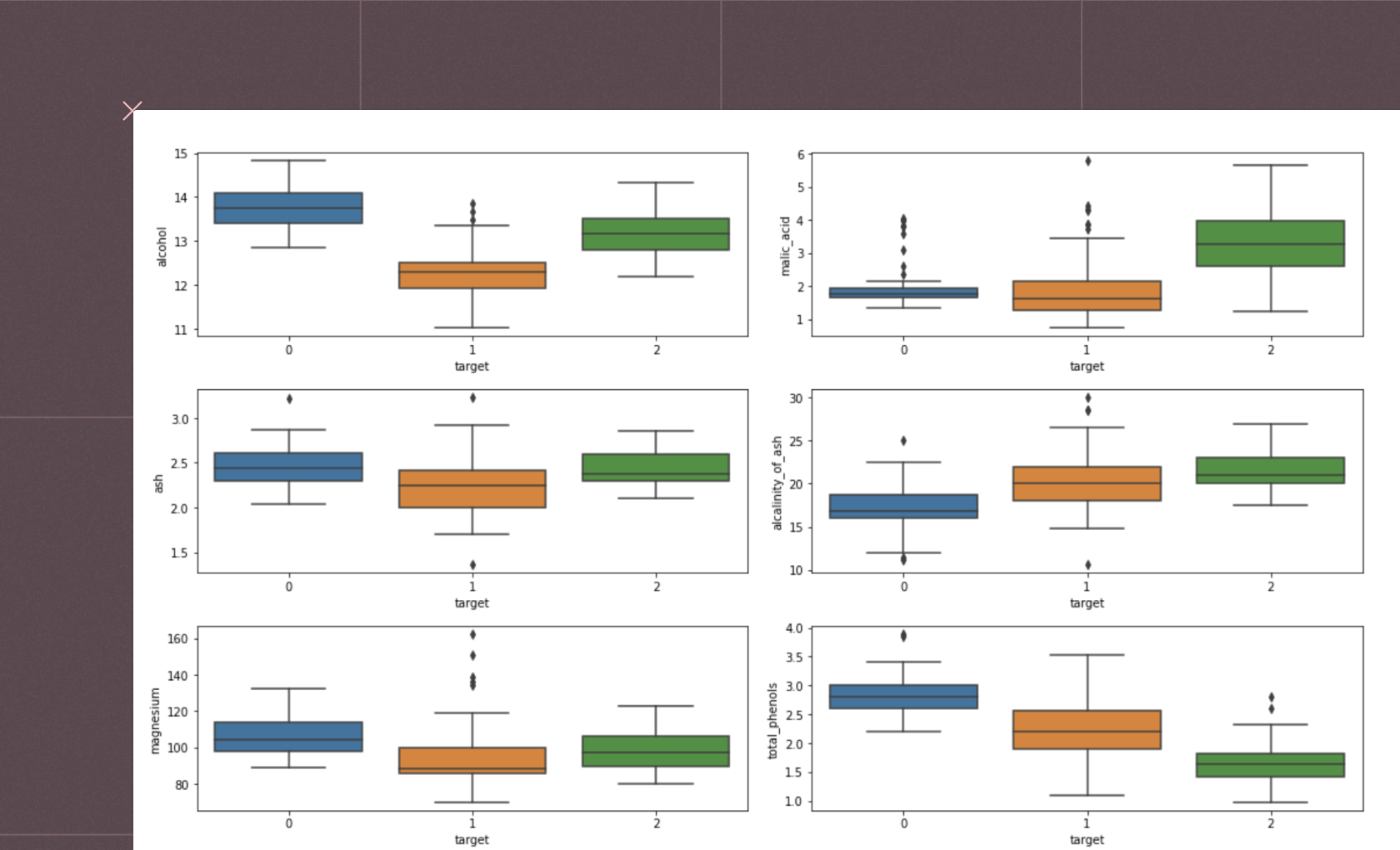
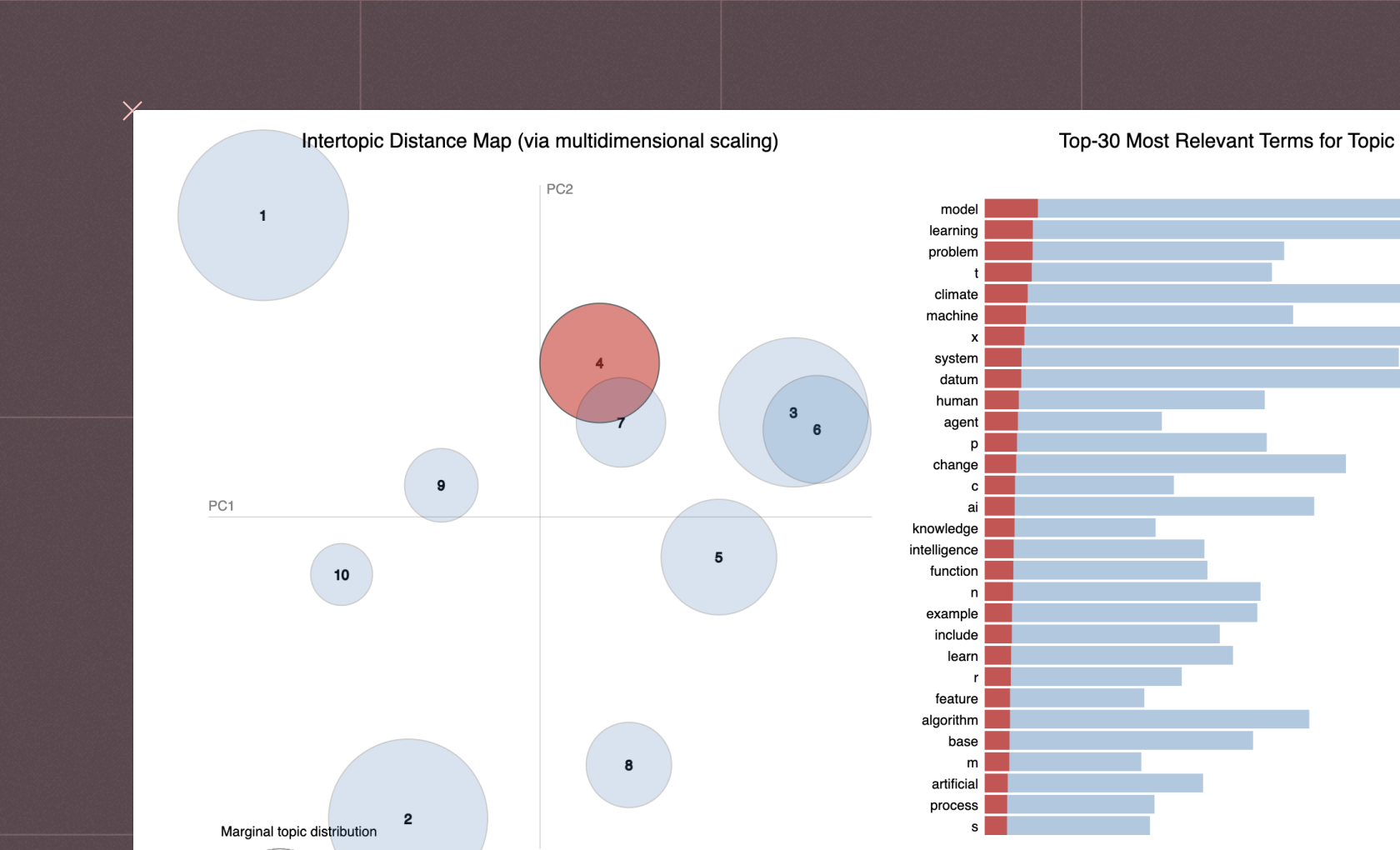
NLP includes tasks like text classification, part-of-speech (POS) tagging, and information extraction, each serving a unique purpose in understanding the complexity of human language. Text classification categorizes text into predefined groups, while POS tagging assigns grammatical information to individual words in a sentence, such as denoting a word as a noun, verb, or adjective. Information extraction, on the other hand, identifies and extracts structured information from unstructured text data.At the core of NLP lies Natural Language Understanding (NLU) and Natural Language Programming (NLP). NLU involves interpreting the nuances and context of the human language, allowing AI to respond appropriately. Natural Language Programming is about writing algorithms and statistical models to direct AI in understanding and utilizing human language effectively.
NLP in action
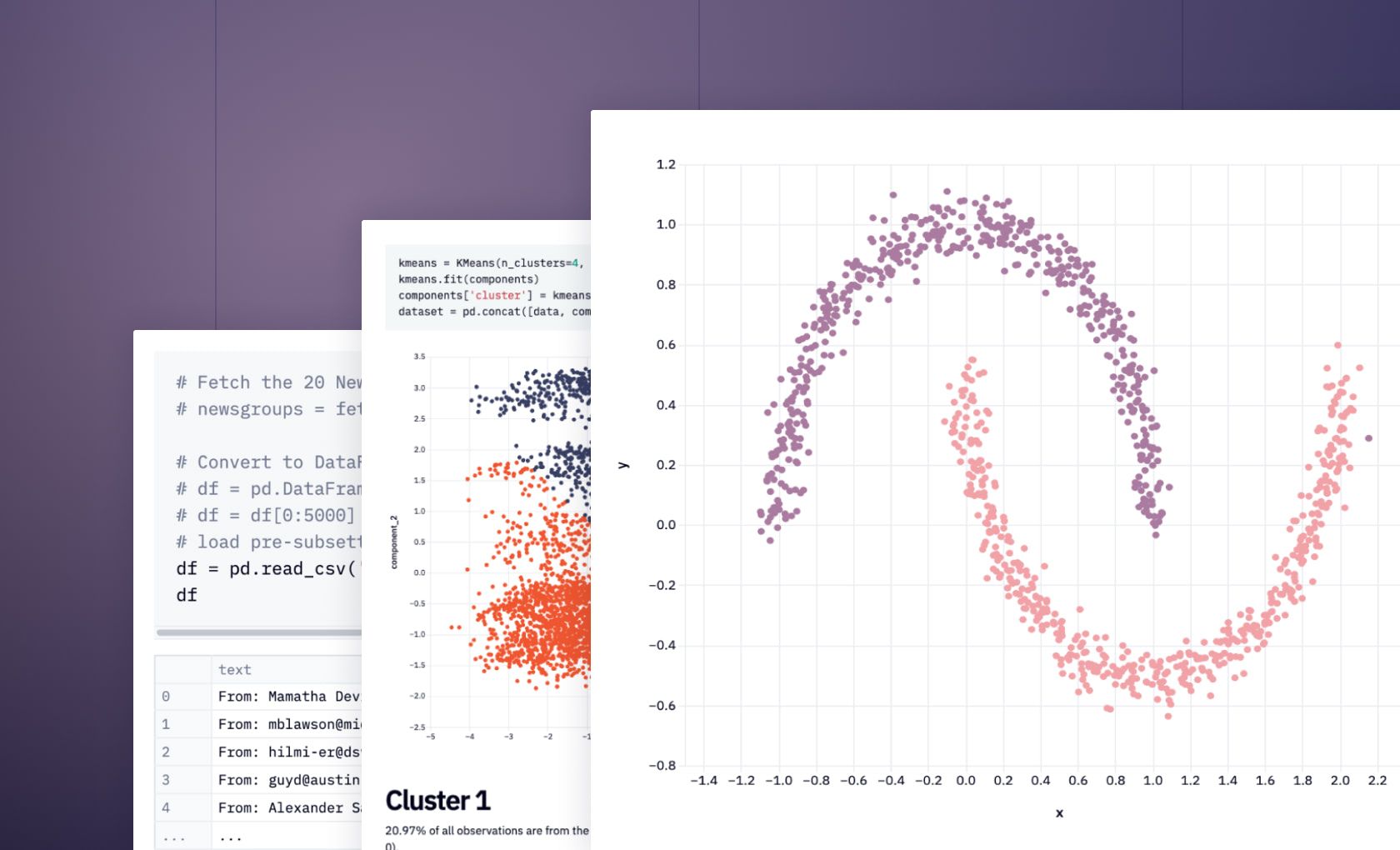
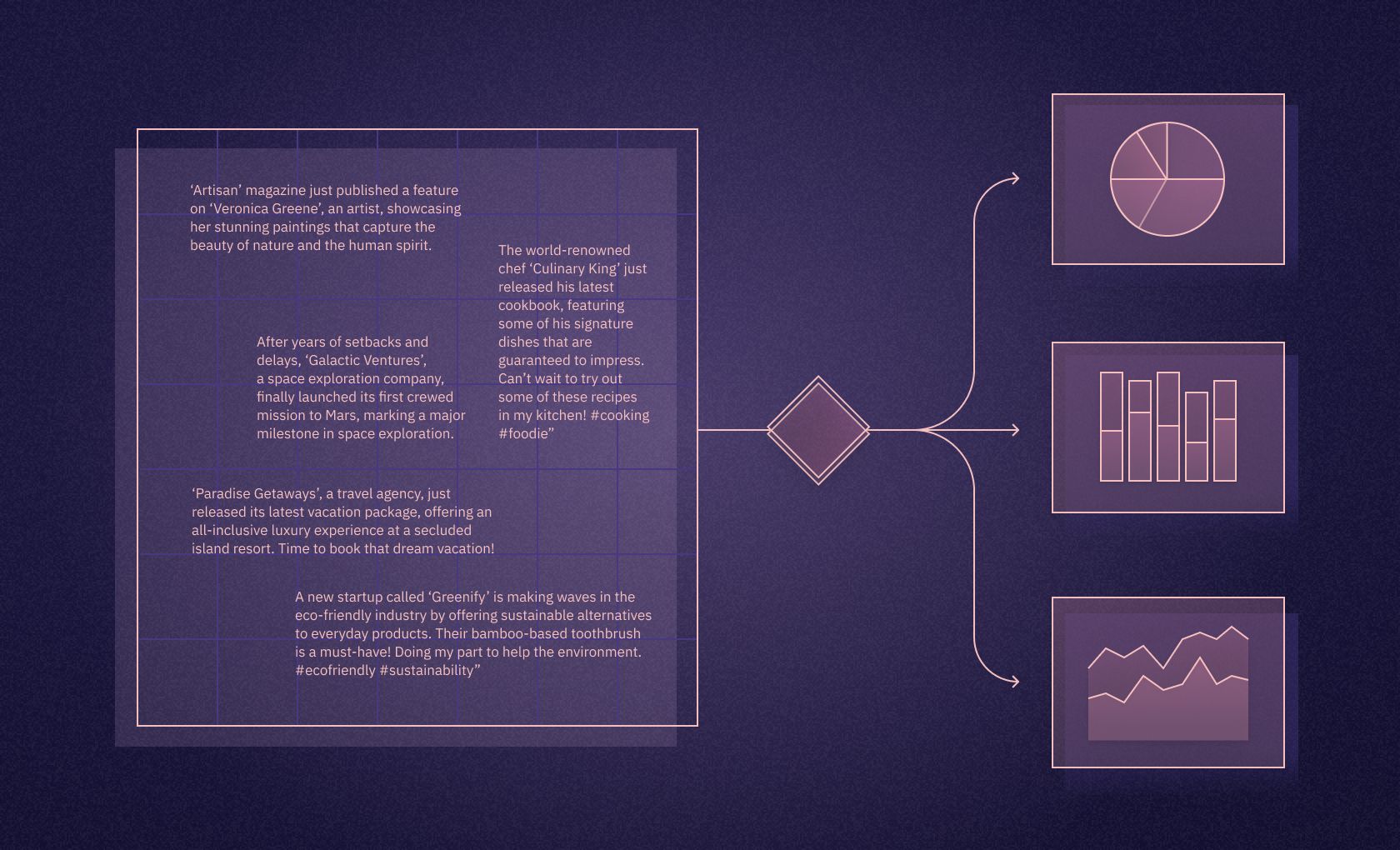
The process typically begins with text data being input into NLP algorithms. This data is then tokenized using tools like the SpaCy tokenizer, which breaks down the text into individual words or tokens. Tokens are then analyzed for root words, a process that often involves removing stop words - commonly used words like "is," "and," "the," which offer little semantic value.Let's consider a simple NLP task using Python's NLTK (Natural Language Toolkit) library: tokenization, which breaks up text into words, phrases, or other meaningful elements called tokens.import nltk nltk.download('punkt') # Download the Punkt tokenizer text = "Hello, world! I'm learning NLP." # Tokenize the text tokens = nltk.word_tokenize(text) print(tokens)The output will be:['Hello', ',', 'world', '!', 'I', "'m", 'learning', 'NLP', '.']This simple task is a foundational step in many complex NLP processes, as handling individual words often provides the basis for further analysis like determining the sentiment of the sentence or translating it into another language.Word frequency, the count of how often each word appears, provides insight into text data's key themes. Similarly, POS tagging and recognition of noun phrases contribute to understanding the text's grammatical structure and context.Another sophisticated aspect of NLP tasks is entity linking, which connects distinct data points to create meaningful relationships and establish context. For instance, linking the entity "Washington" with "USA" can clarify that the reference is to a city, not a person.
Modern NLP techniques
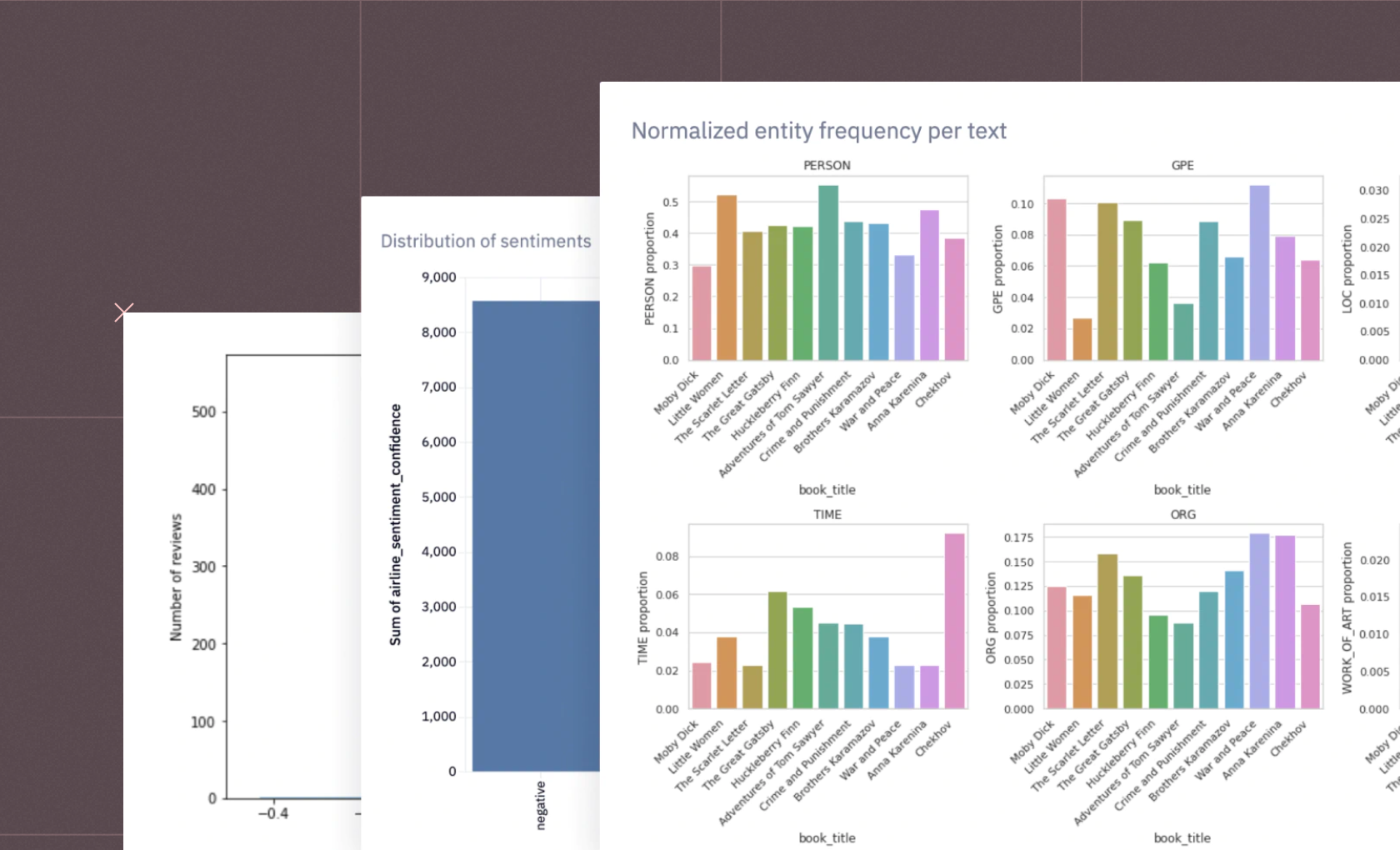
Deep Learning Models and Deep Neural Networks, the backbone of modern NLP, learn from vast amounts of text data, improving their understanding and prediction abilities over time. They identify patterns and trends in the way language is used, making sense of unique words, common words, noun phrases, and the frequency of words.The evolution of large language models, like GPT-4, has significantly boosted the performance of NLP. These models can generate human-like text, demonstrating a remarkable understanding of language semantics, style, and context.The realm of Natural Language Processing for text is vast and exciting. From simple tasks of identifying common and unique words to complex undertakings of entity linking and information extraction, NLP is making waves in the AI landscape, powered by advanced algorithms, deep learning models, and sophisticated tools like SpaCy models.
See what else Hex can do
Discover how other data scientists and analysts use Hex for everything from dashboards to deep dives.
FAQ
Can't find your answer here? Get in touch.